

Google Chrome的历史和指导原则 【译注】这部分不再详细翻译,只列出核心意思。
驱动Chrome继续前进的核心原则包括:
Speed: 做最快的(fastest)的浏览器. Security:为用户提供最为安全的(most secure)的上网环境。
Stability: 提供一个健壮且稳定的(resilient and stable)的Web应用平台。
Simplicity: 以简练的用户体验(simple user experience)封装精益求精的技术(sophisticated technology)。
本文关将注于第一点,速度。
关于性能的方方面面 一个现代浏览器就是一个和操作系统一样的平台。在Chrome之前的浏览器都是单进程的应用,所有页面共享相同的地址空间和资源。引入多进程架构这是Chrome最为著名的改进【译注:省略一些反复谈论的细节】。

一个进程内,Web应用主要需要执行三个任务:获取资源,页面 排版及渲染,和运行JavaScript。渲染和脚本都是在运行中交替以单线程的方式运行的,其原因是为了保持DOM的一致性,而JavaScript本 身也是一个单线程的语言。所以优化渲染和脚本运行无论对于页面开发者还是浏览器开发者都是极为重要的。
Chrome的渲染引擎是WebKit, JavaScript Engine则使用深入优论的V8 (“V8″ JavaScript runtime)。但是,如果网络不畅,无论优化V8的JavaScript执行,还是优化WebKit的解析和渲染,作用其实很有限。巧妇难为无米之炊,数据没来就得等着!
相对于用户体验,作用最为明显的就是如何优化网络资源的加载顺 序、优先级及每一个资源的延迟时间(latency)。也许你察觉不到,Chrome网络模块每天都在进步,逐步降低每个资源的加载成本:向DNS lookups学习,记住页面拓扑结构(topology of the web), 预先连接可能的目标网址,等等,还有很多。从外面来看就是一个简单的资源加载的机制,但在内部却是一个精彩的世界。
关于Web应用 开始正题前,还是先来了解一下现在网页或者Web应用在网络上的需求。
HTTP Archive 项目一直在追踪网页构建。除了页面内容外,它还会分析流行页面使用的资源数量,类型,头信息以及不同目标地址的元数据(metadata)。下面是2013年1月的统计资料,由300,000目标页面得出的平均数据:

1280 KB 包含88个资源(Images,JavaScript,CSS …)
连接15个以上的不同主机(distinct hosts)。
这些数字在过去几年中一直持续增长( steadily increasing ),没有停下的迹象。这说明我们正不断地建构一个更加庞大的、野心勃勃的网络应用。还要注意,平均来看每个资源不过12KB, 表明绝大多数的网络传输都是短促(short and bursty)的。这和TCP针对大数据、流式(streaming)下载的方向不一致,正因为如此,而引入了一些并发症。下面就用一个例子来抽丝剥茧,一窥究竟……
一个Resource Request的一生 W3C的Navigation Timing specification定义了一组API,可以观察到浏览器的每一个请求(request)的时序和性能数据。下面了解一些细节:

给定一个网页资源地址后,浏览器就会检查本地缓存和应用缓存。如果之前获取过并且有相应的缓存信息(appropriate cache headers)(如Expires, Cache-Control, etc.), 就会用缓存数据填充这个请求,毕竟最快的请求就是没有请求(the fastest request is a request not made)。否则,我们重新验证资源,如果已经失效(expired),或者根本就没见过,一个耗费网络的请求就无法避免地发送了。
给定了一个主机名和资源路径后,Chrome先是检查现有已建立的连接(existing open connections)是否可以复用, 即sockets指定了以(scheme、host和port)定义的连接池(pool)。但如果配置了一个代理,或者指定了 proxy auto-config (PAC)脚本,Chrome就会检查与proxy的连接。PAC脚本基于URL提供不同的代理,或者为此指定了特定 的规则。与每一个代理间都可以有自己的socket pool。最后,上述情况都不存在,这个请求就会从DNS查询(DNS lookup)开始了,以便获得它的IP地址。
幸运的话,这个主机名已经被缓存过。否则,必须先发起一个 DNS Query。这个过程所需的时间和ISP,页面的知名度,主机名在中间缓存(intermediate caches)的可能性,以及authoritative servers的响应时间这些因素有关。也就是说这里变量很多,不过一般还不致于到几百毫秒那么夸张。
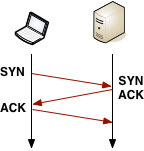
拿到解析出的IP后,Chrome就会在目标地址间打开一个新TCP连接,我们就要执行一个3度握手(“three-way handshake”): SYN > SYN-ACK > ACK。这个操作每个新的TCP连接都必须完成,没有捷径。根据远近,路由路径的选择,这个过程可能要耗时几百毫秒,甚至几秒。而到现在,我们连一个有效的字节都还没收到。
当TCP握手完成了,如果我们连接的是一个HTTPS地址,还有一个SSL握手过程,同时又要增加最多两轮的延迟等待。如果SSL会话被缓存了,就只需一次。
最后,Chrome终于要发送HTTP请求了 (如上面图示中的requestStart)。 服务器收到请求后,就会传送响应数据(response data)回到客户端。这里包含最少的往返延迟和服务的处理时间。然后一个请求就完成了。但是,如果是一个HTTP重定向(redirect)的话?我们 又要从头开始这个过程。如果你的页面里有些冗余的重定向,最好三思一下!
你得出所有的延迟时间了吗? 我们假设一个典型的宽带环境:没有本地缓存,相对较快的DNS lookup(50ms), TCP握手,SSL协商,以及一个较快服务器响应时间(100ms)和一次延迟(80ms,在美国国内的平均值): 50ms for DNS 80ms for TCP handshake (one RTT)
160ms for SSL handshake (two RTT’s)
40ms (发送请求到服务器)
100ms (服务器处理)
40ms (服务器回传响应数据)
一个请求花了470毫秒, 其中80%的时间被网络延迟占去了。看到了吧,我们真得有很多事情要做!事实上,470毫秒已经很乐观了:
如果服务器没有达到到初始TCP的拥塞窗口(congestion window),即4-15KB,就会引入更多的往返延迟。 SSL延迟也可能变得更糟。如果需要获取一个没有的认证(certificate)或者执行 online certificate status check (OCSP), 都会让我们需要一个新的TCP连接,又增加了数百至上千毫秒的延迟。
怎样才算”够快”? 前面可以看到服务器响应时间仅是总延迟时间的20%,其它都被DNS,握手等操作占用了。过去用户体验研究( user experience research )表明用户对延迟时间的不同反应:
延迟及用户反应 0 – 100ms 迅速 100 – 300ms 有点慢 300 – 1000ms 机器还在运行 1s+ 想想别的事…… 10s+ 我一会再来看看吧…
上表同样适用于页面的性能表现: 渲染页面,至少要在250ms内给个回应来吸引住用户。这就是简单地针对速度。从Google, Amazon, Microsoft,以及其它数千个站点来看,额外的延迟直接影响页面表现:流畅的页面会吸引更多的浏览、以及更强的用户吸引力(engagement) 和页面转换率(conversion rates).
现在我们知道了理想的延迟时间是250ms,而前面的示例告诉我们,DNS Lookup, TCP和SSL握手,以及request的准备时间花去了370ms, 即便不考虑服务器处理时间,我们也超出了50%。
对于绝大多数的用户和网页开发者来说,DNS, TCP,以及SSL延迟都是透明,很少有人会想到它。这也就是为什么Chrome的网络模块那么的复杂。
我们已经识别出了问题,下面让我们深入一下实现的细节…
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/2002/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料