


我以前写服务的时候,习惯性就用 UUID 来做主键或者分布式 ID,感觉挺自然的嘛,Java 里一行 UUID.randomUUID() 就能搞定,Python 里 uuid.uuid4() 也很顺手。可是时间长了,问题一个个暴露出来,才发现 UUID 虽然“方便”,但真不一定是最佳选择。
UUID 的那些小坑
先说 UUID,它是 128 位,通常写成 36 个字符那种带横杠的字符串,比如:
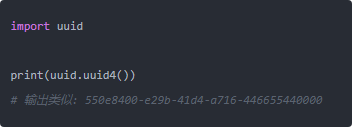
看上去没啥问题,但问题有几个:
- 太长了:36 个字符,在数据库里当主键,不管是索引还是存储,开销都挺大。
- 无序性:UUID 本质上是随机的(尤其是 v4),写到数据库里会导致索引乱跳,插入性能直线下降。
- 可读性差:光看 UUID 完全没法区分谁先谁后,排个序都不现实。
这些小坑叠在一起,就让 UUID 在高并发、大量写入的业务里挺难受。
ULID 登场
后来我接触到 ULID(Universally Unique Lexicographically Sortable Identifier),说白了,它和 UUID 一样是全局唯一 ID,但设计上更贴合实际场景。
ULID 的几个优势:
- 长度更短:26 个字符,比 UUID 少一截。
- 可排序:它的前半部分是基于时间戳生成的,天然有序,插入数据库更友好。
- 可读性好:ULID 是 Crockford’s Base32 编码,不会有大小写混乱问题,看起来干净多了。
举个 Python 的例子,先装个库:
然后:
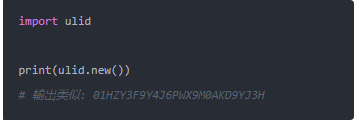
是不是比 UUID 短一些,而且字母数字组合看起来也没那么乱。
性能和排序的对比
UUID 在数据库里有个老毛病:因为它随机,写入时会让索引树不停分裂,写多了性能直接掉下来。ULID 前半部分是时间戳,天然就顺序增长,索引几乎是线性扩展的。
比如你要存一批订单数据,用 ULID 作为主键,后续查询“最近的订单”,直接 ORDER BY id DESC 就行了;用 UUID 就没这个优势。
我自己测试的时候,PostgreSQL 下用 UUID 做主键,插入几百万条后,索引膨胀得厉害,查询也慢。换成 ULID,性能稳得多。
代码里的应用场景
比如建表的时候:
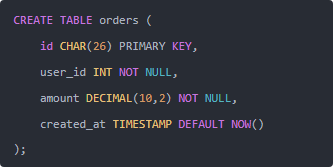
Python 里插入:
这样每个订单都有一个可排序、全局唯一的 ID,数据库层面也不会卡。
什么时候该用 ULID?
不是说 UUID 就完全不能用了,如果你是那种“无状态、临时 ID”的场景,用 UUID 随便搞搞也无所谓。但如果是:
- 数据库主键
- 日志追踪 ID
- 分布式系统里需要唯一 ID 且要排序
那 ULID 基本就是完美替代品。
我现在新项目里基本就不考虑 UUID 了,直接用 ULID,省心省力,还顺便优化了数据库性能。你要还在用 UUID,当心哪天线上写入卡得你怀疑人生。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/13524/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料