


前几天啊,我在公司写个小脚本,明明逻辑跑得挺快的,结果机器风扇狂转,内存飙到八九个G,我人都傻了…同事走过来一看,笑我说:“你这就是典型的 Python 内存没管好,数据全堆内存里了”。那天我回家路上想了半天,才意识到,很多人写 Python,尤其是数据处理、爬虫、甚至是服务端代码,都容易掉进这个坑。今天我就用聊天的方式,跟你们聊聊 Python 里的内存管理,怎么回事,能怎么优化,避免被系统反杀进程。
Python 内存的“幕后老板”
其实啊,Python 程序里的内存,并不是你直接在管,背后有个大总管 —— Python 内存管理器。这个玩意儿负责分配和回收内存,还会搞点缓存机制。比如你写:
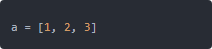
其实底层是 C 实现的对象分配机制。对象创建出来,就会登记在“对象表”里,当没人用了,它才会回收。这里有两个关键点:引用计数 和 垃圾回收。引用计数特别好理解,你想象一下,变量 a 指向一个列表,这个列表的引用数就是 1,如果你再写 b = a,那它就是 2。等到所有指向它的变量都没了,引用数归零,它才会被销毁。

但是呢,单靠引用计数有个致命问题:循环引用。比如链表互相指着,引用计数永远不会归零。Python 这时候就要靠垃圾回收(GC)机制出场,它会定期检查对象之间有没有这种死循环,把孤立的对象清理掉。
那些悄悄吃掉你内存的坑
我举个真实例子,前几天写个 CSV 处理脚本,图省事,直接 data = open("big.csv").readlines(),结果几十万个行全怼内存里,机器差点卡死。其实这种场景根本不用全读到内存,可以一行行迭代:
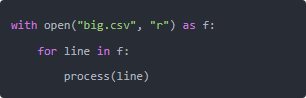
这样 Python 内部只留一行数据在内存,稳得很。还有一种隐蔽情况就是 全局变量忘了清。比如搞个大字典缓存数据,结果处理完不清掉,下一个任务又堆上去。要是线上服务,内存曲线直接上天。解决办法很简单:处理完就 del dict_name,或者赋值 None,让 GC 能接手。
内存优化的几个“土办法”
我平时踩过坑,总结了几个好用的办法,分享下:用生成器代替列表列表会一次性放所有元素,生成器是懒加载,要多少给多少。比如:
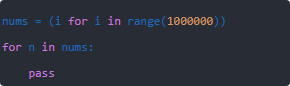
你这跑一百万循环,内存还是稳稳的,因为没有存下全部。
数据量大用 array 或 numpyPython 的 list 很灵活,但存储是“指针数组”,每个元素都是对象引用,浪费空间。你要处理上百万数字,不如用 array('i') 或者 numpy.array,紧凑得多。
对象池和小整数缓存Python 内部其实自己也在优化,比如 -5 到 256 的整数是复用的,你写一万个 1,它们全是同一个对象。但这也提醒我们,不要过分依赖“每次新建对象”,能复用尽量复用。
弱引用(weakref)有时候你只是临时需要引用对象,不希望它阻止 GC 清理,就可以用 weakref。比如缓存系统就会这么玩。

定期手动清理虽然 GC 会自动跑,但有时候长时间运行的服务,内存抖动厉害,可以在合适的时候调:
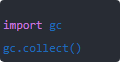
这能主动触发垃圾回收,把一些悬挂对象清掉。
内存监控与调试
说到调试,我之前真干过一件傻事:上线一个 Flask 服务,跑几天内存就爆,硬是查不出原因。后来用 objgraph 一分析,发现是某个列表一直被追加数据,但没清空。简单贴段代码,看看对象泄漏:
这个库会画出对象引用关系图,直观到爆炸。还有个轻量的办法就是用 tracemalloc,Python 自带的,能追踪内存分配位置:
你能直接看到内存分配的峰值在哪。
服务端环境下的注意事项
如果你们写的是长时间跑的服务,比如 Django 或者爬虫调度器,内存泄漏特别要注意。有时候不是你代码的问题,而是三方库没写好。比如早期某些 HTTP 库在连接池里泄漏过对象,结果整个进程越来越大。遇到这种,你要么升级库,要么考虑用进程隔离,跑完就重启。multiprocessing 就是个好工具,干完活的子进程直接销毁,内存自然释放。另外,容器环境下,Kubernetes 经常会因为 OOMKill 把 pod 干掉。所以建议生产环境加上内存上限监控,或者用 resource 模块设置 Python 进程的内存阈值,避免无限制吃内存。
==
扯了这么多,其实总结一句:Python 的内存你管不了太细,但你得懂它怎么运作,写代码的时候心里有数。引用计数、垃圾回收、生成器、弱引用,这些东西掌握了,就能避开大坑。对了,昨天还想起一个梗,我们组小李写了个脚本跑 ETL,忘了用生成器,结果机器内存 64G 直接干满,被运维追着骂。哈哈,所以说,别小看内存管理,写 Python 的人迟早要面临这个考验。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://phpxs.com/post/13584/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料