


那天早上我刚泡好一杯咖啡,准备摸鱼看看新闻,结果我们组那个实习生小唐跑过来,说他在面试的时候被问了一个看似很简单的问题:“用 Python 写个逻辑,统计文件里大写字母的数量。” 听起来是不是特轻松?一句话搞定的那种。但你真要写得“漂亮又稳”,还真没那么一锤子买卖的简单。
我当时笑着跟他说,别急着敲,先想清楚题目到底想考啥。其实这种面试题八成不是让你数个大写字母那么直白,它背后想看你是不是对文件操作、字符串处理,还有异常控制有个完整的理解。 就是说,看你是“会写”还是“会想”。
先别急着上代码,咱脑子里过一遍逻辑。题目说“计算一个文件中的大写字母数量”,那肯定分成两件事: 一个是“读文件”,另一个是“数大写字母”。 这两步拆开看就清楚多了。
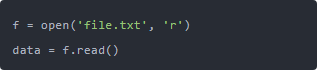
第一步,“读文件”怎么读? Python 打开文件最常见的方式就是用 open() 函数,比如:

这里 with open(...) 是一个上下文管理器,意思是你读完文件后它会自动帮你关掉,不用自己 f.close()。 为什么这一点重要? 因为面试官最喜欢抓你这些细节。很多人写:
然后就忘记 f.close(),这其实会让文件句柄长时间占用不释放,在真实工程里是很危险的。 所以 with open 基本就是标准写法,不用多想。
第二步,拿到文件内容之后,我们得想清楚“怎么判断一个字符是不是大写字母”。 Python 有现成的判断方法:str.isupper()。 比如 "A".isupper() 返回 True,"a".isupper() 返回 False。 那最直接的写法当然就是遍历整个字符串,遇到大写字母就加一。
我当时随手写了个最直观的版本给小唐看:
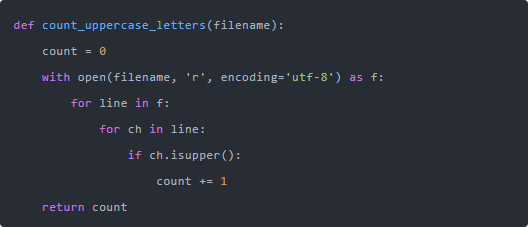
这版本其实就够用了,也挺“教科书式”的。 每一行读出来,再每个字符判断一遍,是不是大写。 最后返回统计结果。
不过我跟他说,这题要真在面试里这样写,可能还不够亮眼。 要想让面试官多看你两眼,你得表现出一点“考虑问题全面”的感觉,比如你要问自己:1.文件是不是可能特别大?2.有没有非英文字符?3.有没有可能打开失败?
第一个问题挺关键的。 如果文件特别大,比如几百 MB,那 .read() 一下全读进内存就很浪费,甚至可能爆内存。 上面那种逐行读取的写法,其实就是为了解决这个问题的。 它是一边读一边处理,每次只加载一行到内存,不会崩。
第二个问题也挺容易踩坑。 你别忘了 .isupper() 在 Unicode 环境下也认别的语言,比如“Ç”、“Ü” 这种。 有时候面试官就会趁你不注意丢一句:“如果文件里有法语大写字母怎么办?” 其实 Python 处理得挺好,isupper() 对 Unicode 字符也适用,但如果他们要求只算英文大写,比如 A-Z,那你得自己判断一下字符是不是在 'A' 到 'Z' 之间。 这就像:
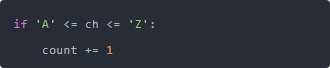
这种写法更直接,也更安全。
第三个问题,异常。 文件操作是最容易出错的,比如文件路径错了、权限不够、编码格式不对之类的。 如果不加任何异常处理,一旦出错,程序就直接崩溃。 所以比较严谨的做法是加个 try...except:
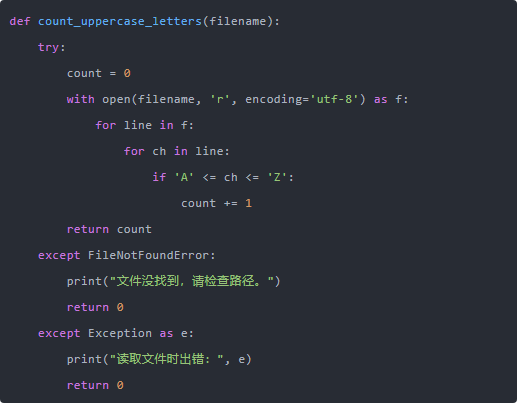
你看,加上这几行以后就显得成熟很多,不管遇到啥情况程序都不会炸。 在面试场景里,这就是“代码质量感”。
那有同学可能会问:有没有更“简洁”的写法? 有。Python 讲究一行能解决的绝不写两行。 比如你可以用生成器表达式来一口气完成统计:

这一行看着就挺优雅的吧? 不过我一般不会在面试里直接写成一行。 因为面试官更想看你的逻辑思路,而不是你会不会玩语法技巧。 这种写法可以作为“附加说明”,比如你写完基础版后说:“其实这个还可以压成一行,效果一样。” 这样反而会加分。
后来我们还聊到了性能的问题。 其实在这个题目里性能没啥瓶颈,但如果真有几百兆的大文件,也可以稍微优化。 比如可以用 collections.Counter,一边读一边统计,不用每个字符都判断一次。
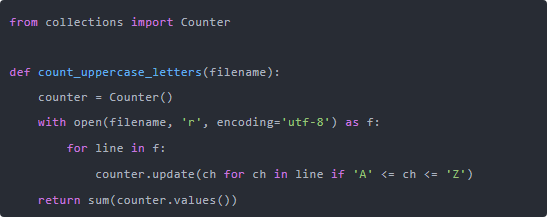
这个写法逻辑上没啥变化,就是用 Counter 统计所有大写字母出现的次数,然后再加总。 看起来更工程一点,也方便你后面扩展,比如想看看哪个字母出现最多。
小唐当时一边点头一边记,结果我问他:“你觉得这题要考你啥?” 他想了半天说:“考字符串函数?” 我摇头。其实这题真正考的,是你对“文件读取过程”和“程序健壮性”的理解。 大多数候选人一看到题就想上手写几行能跑的代码,能跑固然重要,但能“想清楚怎么跑得更安全”,那才是面试官想看到的。
比如,如果面试官接着问你: “那如果文件很大怎么办?” 你能说出“逐行读取比一次性 read 效率更高”; 又比如他说“如果文件是二进制的呢?” 你能解释“那就需要判断字节流,可能要 decode 一下”。 这种答法一下就体现你经验的广度。
其实很多基础题都能玩出深度。 这题就是一个经典例子,看似简单,细节一堆。 你写得再短,只要逻辑完整、考虑全面,它就是一段“好代码”。 反过来说,你要是写出个 .read() 然后一行 .count("A") + .count("B") + ...,面试官多半会笑着摇头。
那天小唐回去之后真写了一版改进版,还特地加了命令行参数,让用户输入文件路径。我看完笑着说:“不错,下次面试就靠它吧。” 他问我能不能再加个统计小写字母的功能,我说可以啊,把条件改成 'a' <= ch <= 'z',再封装一下函数名。 其实这种小题就是积累的好机会,每改一点,理解就更深一层。
后来我在地铁上还想着这题,其实要写成一篇文章也挺有意思的。 因为从“怎么打开文件”到“怎么防错”,这一路下来,几乎把 Python 文件操作最常见的坑都走了一遍。 写算法不难,难的是你能不能在一个简单问题里展示出自己的思考深度。
所以啊,如果你下次也遇到这种“看起来三行能搞定”的题,别急着动手。 先想: 我要怎么写,既能让别人读得懂,又能让自己看得舒服? 要是能做到这点,哪怕只是数个大写字母,也能写出风格。
以上就是“请写一个 Python 逻辑,计算一个文件中的大写字母数量。”的详细内容,想要了解更多Python教程欢迎持续关注编程学习网。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/13660/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料