


我先说结论哈:一个破 groupby.apply,我从 40 分钟干到 4 秒,真的不是标题党…就是那种干到怀疑人生的那种优化。
那天晚上我刚准备关电脑回家,运营同学在工位后面拍我一下说:东哥,那个用户行为报表,你这脚本是不是挂了?跑了半小时了还没出。 我心里咯噔一下:完了,又是我那坨 pandas 屎山在作妖。
数据量不算吓人,大概两三千万行,一张日志表,长这样:
- user_id 用户
- event 事件类型
- cost 花了多少钱
- ts 时间戳
业务小哥的需求也很朴素: 每个用户统计一下各种事件次数、总金额、首末时间,顺带算个留存啥的。听起来就像“很适合用 groupby 啊,对吧”,于是年轻时候的我就写出了下面这坨——典型的“学会了一个 groupby,然后用到死”的代码:
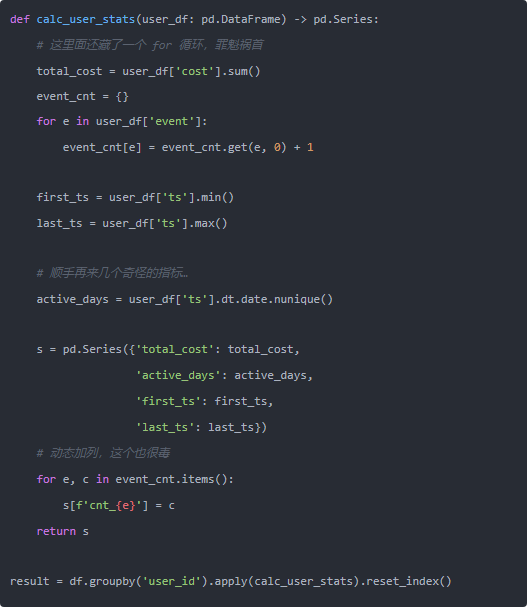
这个玩意在我们那台 8 核 32G 的机器上,跑全量数据大概 40 分钟。 而且最离谱的是:越到晚上数据越多,报表就越慢,运营越烦我,我就越想转行卖煎饼。
后来我冷静下来,把这段代码翻来覆去看了几遍,问题其实特别“pandas 教科书式”:
- groupby.apply 把每个 user_id 的小 DataFrame 丢给 Python 层函数去算,完全吃不到底层 C 的红利。
- 函数里面再套一个 for e in user_df['event'],双重 Python 循环,GIL 锁死。
- 动态往 Series 上加字段,pandas 一直在帮你“扩容”,非常费。
就好比你明明有个搅拌机,非要自己拿筷子一点点搅。
我当时的想法就是:能不能把所有逻辑都塞回 pandas 自己的算发里,让它里面那些 C 写的轮子转起来? 于是开始一点点拆那个函数,先把最简单的统计抽出来,看能不能用 agg 搞定:
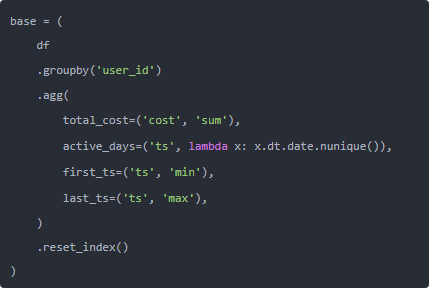
这里有两个点:
- 把“一个 groupby 做一堆事”写进 agg 里,一次扫描就把总金额、首末时间都算完;
- active_days 实在没现成函数,只能来个小 lambda,但它只跑一次,不是每个事件都跑,损失还行。
然后是那个 event_cnt,原来我在 apply 里手动 dict 计数。这个完全没必要,人家 groupby + size 就能办到,而且顺带还能帮你 pivot:
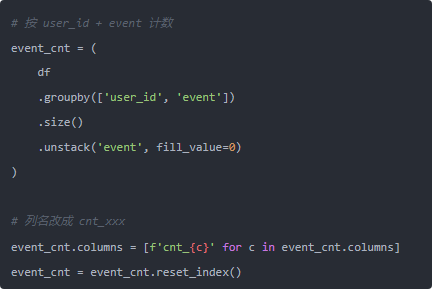
到这一步,其实我们已经把那个大 calc_user_stats 拆成了两块纯 pandas 的矢量操作:
- base:每个用户的整体统计
- event_cnt:每个用户各种事件的次数
最后再拼回来就行了:
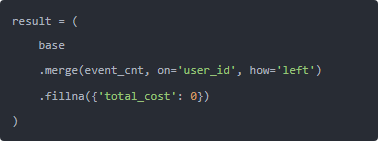
看起来也没多高深对吧,就是从“一个 apply 全干”变成“两个 groupby + 一次 merge”。 但是——就是这一手,直接从 40 分钟干到了 7 秒多。 我当时在终端敲了个 %%time,愣是又跑了三遍确认自己没看错。
后来又手贱往里加了几个小优化,就从 7 秒挤到了 4 秒,顺便说下都是啥:
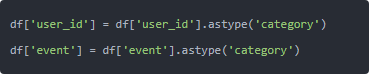
第一,小字段提前转 category。 我们的 user_id、event 其实重复率特别高,转换下能减少分组成本:
第二,groupby 的时候关掉没必要的排序:

第三,那个 active_days 其实可以提前算好,不用在 agg 里再来个 lambda:
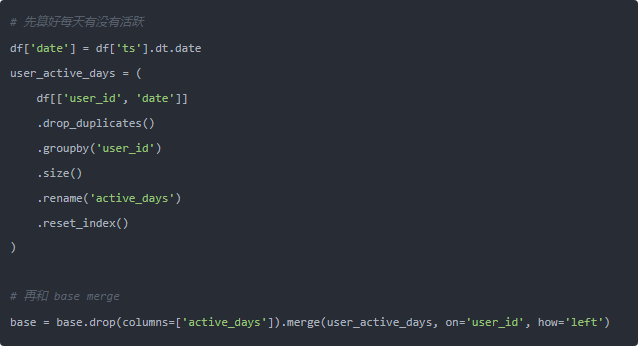
把 agg 里最后一个自定义函数也弄没了,整条链路就全是“底层有 C 实现”的操作了。
有同学在群里问我:“东哥,我这不也是 groupby 嘛,为什么你那就能从 40 分钟到 4 秒?” 我就一句话:你用的是“groupby + Python 函数”,我用的是“groupby + 内置 agg/size/unstack/merge”,看起来都叫 groupby,实则一个骑共享单车,一个开高铁。
还有几个小点我顺嘴说一下,你们可以对照自己代码挨个查:
- 一个字段多次 groupby:很多人写业务逻辑的时候,先按 user_id 分一次算 A 指标,再分一次算 B 指标,其实可以一次 groupby 用多个聚合函数搞定。
- 在 groupby 里拼字符串、做正则:这玩意放外面,提前算好一个列,用 map 或 merge 回填;
- 在循环里频繁 df[df.xxx == ...] 再 groupby:这是真·内耗,我见过有人 for 每个用户再切一片 DataFrame…当场 CPU 热得能煎蛋。
那次优化完之后,运营那边报表页面刷新直接从“点完先去倒杯水”变成了“刚准备打开微信就出结果了”, 我自己看着监控面板上那条 CPU 曲线从山脉变成小土包,心情非常复杂:一半是爽,一半是想抽几年前写这段代码的自己。
顺带感慨一句,这种“默认写法坑死人”的事,我在别的技术栈也干过,比如 SpringBoot 那堆默认配置不改,线上迟早出事 pandas 也一样,你只要手欠写了个 groupby.apply(lambda df: …) + for,它就会默默陪你 CPU 炖 40 分钟。
以上就是“Pandas GroupBy提速神技:40分钟到4秒!”的详细内容,想要了解更多Python教程欢迎持续关注编程学习网。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://phpxs.com/post/13984/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料