


在日常的后端开发或运维工作中,日志分析是必不可少的一环。比如,我们需要统计各个 API 接口的响应时间分布:有多少请求在 100ms 内?有多少超过了 1s?
通常,我们可能会写一堆 if-else 来判断时间范围,再用普通的字典来计数。代码写多了,不仅冗长,还容易出错。
今天,我们通过一段真实的代码案例,来学习如何利用 Python 的 Enum、MutableMapping 和 魔法方法,手写一个“智能”字典,让数据统计变得既类型安全又优雅。
场景与需求
假设我们有一个日志文件 logs.txt,每一行记录了一个接口路径和响应时间(毫秒):
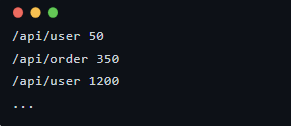
我们的目标是:
- 1. 自动将响应时间归类(如:<100ms, 100-300ms 等)。
- 2. 按路径分组统计。
- 3. 输出时保持性能等级从快到慢的顺序。
代码核心解析
让我们逐层拆解这段代码,看看它到底“智能”在哪里。
1. 定义性能等级枚举 (Enum)
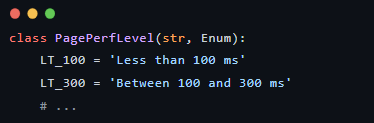
亮点:
- • 类型安全:使用 Enum 避免了魔法字符串(Magic Strings)。你不会再手误写成 'Less than 100' 少个 ms。
- • 可迭代:list(PagePerfLevel) 可以直接获取所有等级,方便后续排序。
- • 继承 str:这让枚举值在打印或作为字典键时,行为更像字符串,兼容性更好。
2. 核心魔法:自定义字典 (MutableMapping)
这是整段代码最精彩的部分。作者没有直接继承 dict,而是实现了 collections.abc.MutableMapping 抽象基类。
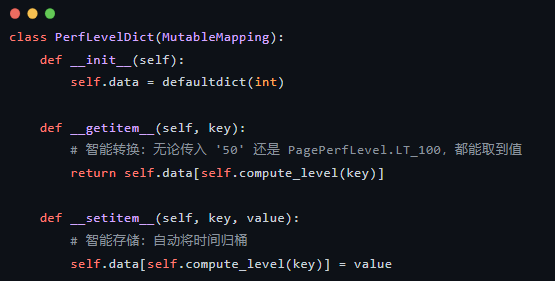
为什么要用 MutableMapping 而不是继承 dict?
- • 避免副作用:dict 的内部实现非常复杂,直接继承容易因为重写某些方法而破坏底层逻辑(比如 update 方法可能绕过 __setitem__)。
- • 接口规范:MutableMapping 强制你实现 5 个核心方法(__getitem__, __setitem__, __delitem__, __iter__, __len__),一旦实现,你的类就拥有了字典的所有功能(如 keys(), values(), in 操作符等)。
“智能”体现在哪?
注意 __setitem__。当你执行 perf_dict['50'] += 1 时,它不会把 '50' 当作键,而是通过 compute_level 自动转换成 PagePerfLevel.LT_100 存储。调用者无需关心分类逻辑,字典自己会处理。
3. 自定义排序输出
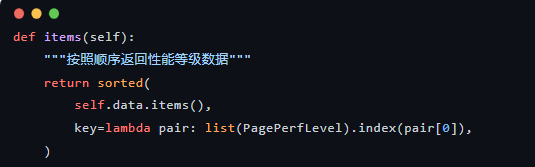
普通的字典(即使在 Python 3.7+ 有序)是按照插入顺序排列的。但在性能报告中,我们通常希望看到 从快到慢 的固定顺序。通过重写 items() 方法,我们保证了输出永远符合 PagePerfLevel 定义的顺序。
代码审查与优化建议 (Code Review)
虽然这段代码设计思路很棒,但在生产环境中,还有几个细节值得优化。这也是我们学习进阶的关键点。
1. __delitem__ 的 Bug
原代码:
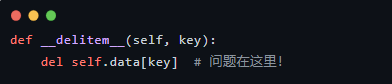
分析:__setitem__ 存储时使用了 compute_level(key) 转换后的枚举值,但 __delitem__ 却直接删除原始 key。
后果:如果你尝试 del perf_dict['50'],会报错 KeyError,因为 self.data 里存的是 PagePerfLevel.LT_100。
修复:

2. 异常处理
compute_level 中直接 int(time_cost_str)。如果日志文件里混入了非数字字符(比如 timeout),程序会直接崩溃。
建议:增加 try-except 块,将异常数据归类为 UNKNOWN 或跳过并记录错误日志。
3. 性能优化
items() 方法中每次调用都执行 list(PagePerfLevel).index(...)。
- • list(PagePerfLevel) 每次都会创建新列表。
-
• index 是 O(N) 查找。
优化:可以在类外部预计算一个 {level: index} 的映射字典,将查找复杂度降为 O(1)。
4. 类型提示 (Type Hinting)
现代 Python 项目强烈推荐加上类型提示,增加代码可读性和 IDE 支持。

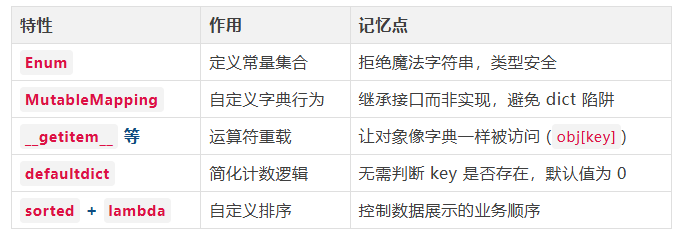
知识点总结
通过这段代码,我们复习了以下 Python 高级特性:
结语
这段代码展示了 面向对象编程 (OOP) 与 Python 数据模型 的完美结合。
它不仅仅是在统计日志,更是在封装业务逻辑。通过将“时间归桶”的逻辑隐藏在字典的 __setitem__ 中,主流程 analyze_v2 变得极其干净,只关注“读取”和“打印”,而不关注“如何分类”。
这就是高内聚、低耦合的体现。
希望大家在未来的开发中,遇到类似“带逻辑的数据容器”需求时,能想起 MutableMapping 这个强大的工具,写出更优雅的 Python 代码!
以上就是“Python 魔法方法实战:手写一个“智能”字典,让日志分析更优雅!”的详细内容,想要了解更多Python教程欢迎持续关注编程学习网。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/14024/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料