


Python慢,这是实情。同样的数值计算,C++可能跑0.01秒,Python要跑10秒,差距达到1000倍。但每年GitHub上最流行的语言排行榜里,Python稳居前列,深度学习、数据分析、量化交易……这些对性能极其敏感的领域,偏偏都在用Python。
这不是程序员们集体脑子进水了,而是因为他们知道一件事:Python慢的,是Python解释器。你真正跑的那些运算,根本不在Python里。
先搞清楚:Python为什么慢?
Python是动态类型语言,每次执行一个操作,解释器都要先问:这个变量是什么类型?支持这个操作吗?占多少内存?然后再执行。
C++在编译期就把这些问题都回答了,运行时直接执行机器码。
另一个原因是GIL(全局解释器锁)。CPython(最常用的Python实现)同一时刻只允许一个线程执行Python字节码,多核CPU在纯Python多线程里形同虚设。
但是——Python慢是有边界的。
边界就是:你在哪里跑、跑什么。接下来这5种方法,本质上都是在把"真正的计算"搬出Python,交给更快的执行层去完成。
方法一:用NumPy向量化,消灭Python循环
这是最重要的一条,也是最容易被忽视的。
很多人写Python数值计算,习惯写这样的代码:
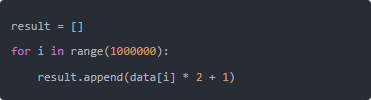
这段代码的每次循环,都在Python层面执行,解释器要处理100万次类型检查、内存分配、对象创建。
换成NumPy:
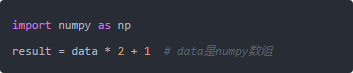
一行代码,速度提升100倍以上,有时甚至更多。
原因是:NumPy的底层是C语言写的,data * 2 + 1 这个操作直接在C层面对整个数组做批量运算,Python只是发出了一条命令,真正的计算不在Python里发生。
规则很简单:能向量化的,绝不写循环。 看到for循环在处理数组数据,先想想能不能用NumPy的广播机制或内置函数替代。
方法二:Numba——给Python函数贴上JIT的翅膀
有些计算逻辑确实没法向量化,必须写循环,比如需要根据上一步结果决定下一步的迭代计算。
这时候可以用Numba。
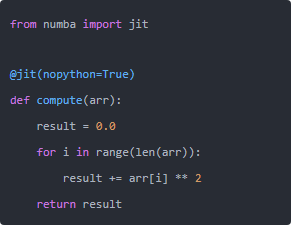
加了@jit(nopython=True)这个装饰器,Numba会在函数第一次被调用时,把它即时编译(JIT)成机器码。
第一次调用会慢(编译开销),之后每次调用,跑的都是编译好的机器码,速度可以接近C语言。
几行Python代码,加一个装饰器,数值循环的速度直接上升一到两个数量级。Numba对NumPy数组的支持非常好,对科学计算场景几乎是零成本加速。
注意:nopython=True会强制Numba使用纯机器码模式,不回退到Python解释器,性能最好,但对代码有一些约束(比如不能使用任意Python对象)。
方法三:多进程——绕过GIL,真正用满多核
前面提到Python的GIL让多线程在CPU密集型任务上帮不上忙,但多进程(multiprocessing)不受GIL限制——每个进程有独立的Python解释器和内存空间。
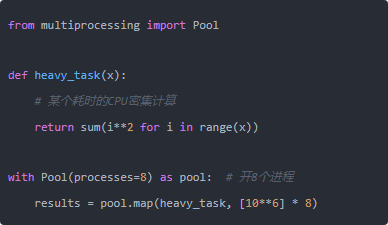
8核CPU,理论加速比接近8倍。
多进程的开销主要在进程启动和数据在进程间传递(序列化/反序列化)上。所以这个方法适合"任务颗粒度大、数据量不太大"的场景——每个子任务要跑几秒以上的计算,多进程的加速效果很明显;如果每个任务只需几毫秒,进程通信的开销会把收益吃掉。
对于I/O密集型任务(网络请求、文件读写),GIL不是瓶颈,用asyncio异步并发即可,不需要多进程。
方法四:Cython——把Python编译成C扩展
Cython是一种Python的超集语言:你可以写几乎正常的Python代码,加上类型注解,然后把它编译成C扩展模块。
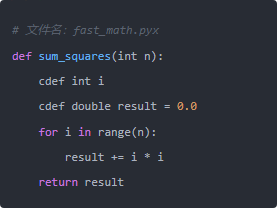
用cdef声明变量类型之后,Cython知道这些变量不需要动态类型检查,直接生成对应的C代码。编译后,这个函数以C扩展的形式被Python调用,速度可以提升几十到几百倍。
Cython的上手成本比Numba高一些,需要配置编译环境(setup.py),但它的控制粒度更细,对于需要精细调优的底层模块(比如自己写的数据结构或算法库),是很好的选择。很多Python的知名库,比如pandas的某些核心部分、scikit-learn的关键算法,底层就是Cython写的。
方法五:直接调用C/C++库——让Python做指挥,让C做苦力
这是终极方案,也是Python生态里用得最普遍的模式。
Python不擅长计算,但它擅长做"胶水"——把调用各种高性能库的接口粘合起来。
几个常用方式:
ctypes:Python标准库自带,可以直接加载.so(Linux)或.dll(Windows)动态链接库,调用C函数。无需编译扩展,适合调用已有的C库。
cffi:比ctypes更现代,接口更友好,PyPy解释器推荐使用。
pybind11:专门用来把C++代码封装成Python模块,类型映射和异常处理都做得很完善,是C++扩展的主流选择。
事实上,NumPy、PyTorch、TensorFlow、OpenCV……你用的几乎所有"快"的Python库,内核都是C或C++,Python只是它们的调用层。
所以"Python慢"这件事,某种程度上是个伪命题:Python程序的性能上限,由它调用的底层库决定,不由Python解释器决定。一个PyTorch训练程序,99%的GPU计算时间都在CUDA里,Python代码只是在安排"谁先跑、结果存哪里"。
什么时候这些方法都不够用?
有些场景,这5种方法确实力所不及:
- 实时系统,需要微秒级响应,GC(垃圾回收)的停顿都不能接受——用C++或Rust;
- 嵌入式硬件,内存和算力极度受限——用C;
- 需要精确控制内存布局和生命周期——用Rust;
这不是Python的失败,这是工具的边界。好的工程师不是把所有问题都用同一种工具解决,而是知道什么问题用什么工具。
以上就是“Python虽然慢,但这5种方法能让它媲美C++!”的详细内容,想要了解更多Python教程欢迎持续关注编程学习网。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/14032/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料