


NVIDIA在GTC 2026发布了CUDA Python新一代工具栈演讲,核心是实现纯Python编写光速CUDA,通过cuda.compute、cuda.tile、cuda.core等组件,达成比肩甚至超越CUDA C++的性能,SAXPY在B200上带宽利用率达91.8%,并以Awkward Array为案例验证,推动GPU库生态走向Python All The Way Down,简化开发、降低维护成本、提升打包效率。本文带来本次演讲的解读。
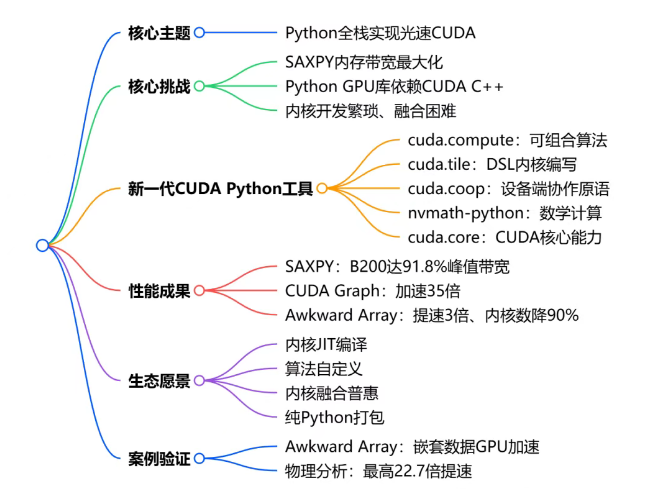
一、当前痛点
长期以来,PyTorch、CuPy 等主流 Python GPU 库必须依托 CUDA C++ 实现核心功能,因为 CUDA 的关键基础模块仅面向 C++ 提供,开发者无法直接在 Python 中调用底层高性能能力。
二、思维导图
三、详细总结
1. 演讲背景与目标
本次演讲由NVIDIA与普林斯顿大学联合发布,面向Python库开发者与使用者,目标是纯Python环境下实现光速CUDA加速,革新GPU Python生态。
2. 核心性能挑战:SAXPY基准测试
以经典内存受限操作SAXPY(y=α*x+y) 为基准,验证不同方案的峰值内存带宽利用率。
- 测试硬件:RTX A6000(864 GB/s)、B200(7152 GB/s)
- 最优方案:cuda.tile、cuda.compute,B200平台利用率达91.8%,超过CUDA C++与PyTorch编译模式。
- 关键结论:内核融合是性能核心,新硬件下带宽利用更关键。
3. 现有Python GPU库的局限
- 主流库(PyTorch eager、CuPy)依赖CUDA C++核心,Python仅做绑定。
- 新型框架(PyTorch编译、JAX)基于编译器,但非通用、开发门槛高。
- 内核编写需手写CUDA C++,设备端原语缺失、维护成本高。
4. 新一代CUDA Python核心组件
| 组件 | 核心能力 | 替代传统方案 |
|---|---|---|
| cuda.compute | 可组合算法(排序、规约、变换),支持自定义算子 | Thrust、手写CUDA C++算法 |
| cuda.tile | 基于DSL的分块内核编写,自动优化线程与数据 | CuTe、Triton、手动内核 |
| cuda.coop | 设备端协作原语(块规约) | CUB库 |
| nvmath-python | 设备端矩阵乘等科学计算 | cuBLASDx |
| cuda.core | 设备管理、CUDA Graph、流同步 | 原生CUDA Runtime |
5. 关键技术突破
- 普惠式内核融合
- 编译器融合(torch.compile):自动但受限。
- 开发者显式融合(cuda.compute迭代器):1个内核替代2个,耗时从40us→8us。
- CUDA Core全访问
- Python直接调用CUDA Runtime,CUDA Graph实现固定流程35倍加速。
- 纯Python分发
- 告别多CUDA版本、多架构复杂打包,仅需py3-none-any.whl。
6. 案例:Awkward Array GPU加速
- 旧方案:CuPy+Raw CUDA C++,约260次内核启动,代码冗余、维护难。
- 新方案:cuda.compute,内核数降至~30个,速度提升3倍,物理分析场景最高22.7倍提速。
- 价值:嵌套不规则数据无需手写C++,纯Python实现光速分段规约。
7. 生态愿景:Python All The Way Down
- 计算内核JIT编译为主流。
- 算法与数据类型高度自定义。
- 内核融合简单可控。
- 打包分发纯Python化。
四、关键问题与答案
-
新一代CUDA Python相比传统方案的核心优势是什么?答:一是性能比肩CUDA C++,SAXPY在B200带宽利用率达91.8%;二是纯Python开发,无需手写CUDA C++;三是内核融合更灵活,开发者可显式控制;四是打包极简,纯Python包跨平台兼容。
-
cuda.compute如何解决Awkward Array的嵌套数据加速难题?答:cuda.compute原生支持分段规约等不规则数据操作,自动处理偏移与边界;将原260个内核融合为~30个,代码量大幅减少,性能提升3倍,物理分析场景最高22.7倍。
-
本次演讲提出的Python All The Way Down对GPU生态有何影响?答:重构Python GPU库架构,摆脱对CUDA C++核心的依赖;降低高性能CUDA开发门槛,让Python用户直接编写光速内核;简化打包与维护,推动JIT编译成为主流,适配新一代NVIDIA GPU硬件。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/14076/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料