


提起 Python 爬虫,大多数人第一反应是 Scrapy、BeautifulSoup 或者 Playwright。但今天要介绍的这个框架 Scrapling,最近在 GitHub 上已悄然拿下 4.3 万颗星,同时被 4 千个开发者 Fork,热度持续攀升。
它的核心理念很直接:一个库,从单次请求到全站爬取,全部搞定。
自适应解析——网站改版也不怕
传统爬虫最大的痛点之一就是网站稍微改个布局,选择器就废了。Scrapling 为此内置了自适应解析引擎,能智能追踪元素,在网站更新后自动重新定位目标内容。
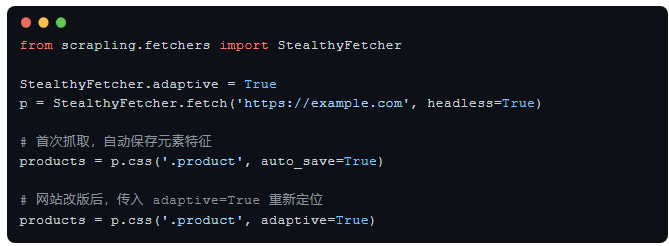
这一特性解决了爬虫维护中最头疼的"改版即失效"问题。
全功能爬虫框架——类 Scrapy 但更强
Scrapling 提供了一套完整的异步爬虫框架,上手方式与 Scrapy 类似,但功能更丰富:
- • 并发爬取:可配置并发数、域名限速、下载延迟
- • 多会话支持:在一个 Spider 中同时使用 HTTP 请求和浏览器自动化
- • 断点续爬:Ctrl+C 优雅暂停,下次启动自动从断点恢复
- • 流式模式:通过 async for item in spider.stream() 实时处理数据
- • Robots.txt 遵守:可选开启,自动遵守禁止规则和抓取频率限制
- • 开发模式:首次运行缓存响应,后续直接回放,无需反复请求目标服务器
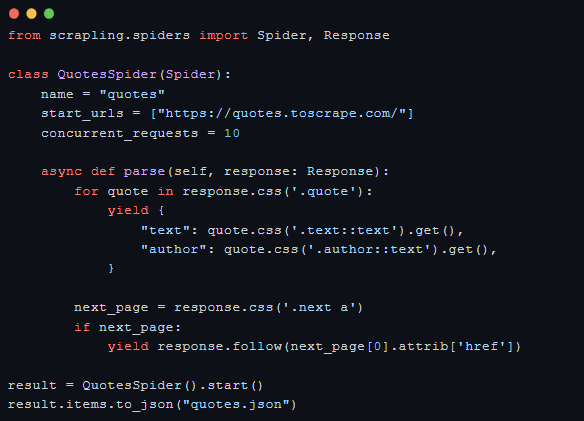
反爬克星——Cloudflare 秒过
Scrapling 内置多种 Fetcher,各有分工:

搭配内置的代理轮换(ProxyRotator)、DNS 泄漏防护(DNS-over-HTTPS)、广告域名屏蔽等功能,基本能应对主流反爬机制。
MCP 服务器——AI 辅助数据提取
Scrapling 还内置了 MCP 服务器,可与 Claude、Cursor 等 AI 工具联动,让 AI 直接调用 Scrapling 的抓取能力来精确定位页面内容,从而大幅减少 token 消耗、加快数据提取速度。
性能实测——快到离谱
官方基准测试中,Scrapling 在 5000 个嵌套元素的文本提取中表现炸裂:
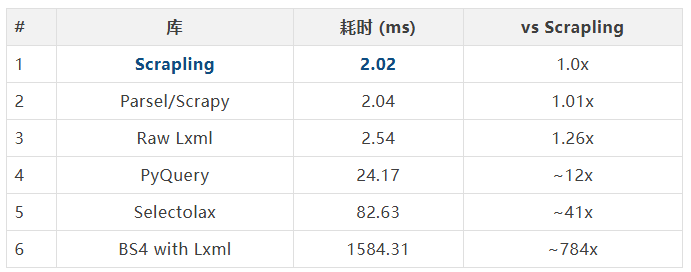
Scrapling 领先 BeautifulSoup 近 800 倍,即使对比同门师兄 Scrapy/Parsel 也毫不逊色。
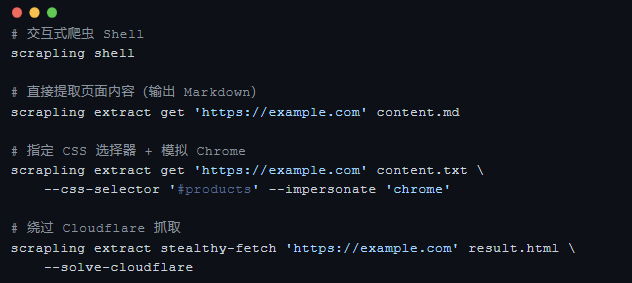
零代码 CLI——命令行直接爬
不想写代码?Scrapling 还提供了强大的命令行工具,无需写一行 Python 即可完成抓取:
安装方式
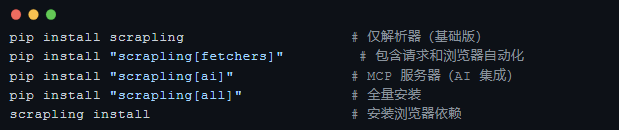
也支持 Docker 一键拉取:

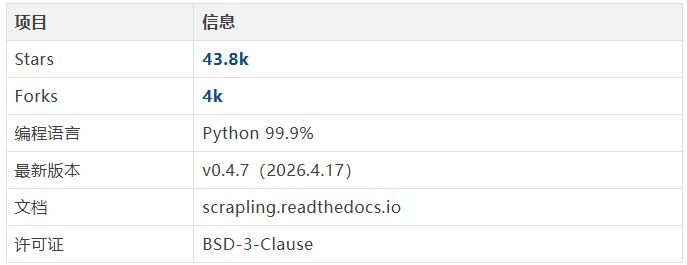
项目信息
总结
Scrapling 不是一个"又一个爬虫库",它真正做到了all-in-one:从轻量级单次抓取到大规模并发爬取,从绕过反爬到 AI 辅助提取,一条命令甚至一行代码就能搞定。再加上傲视群雄的解析性能和实用的 CLI 工具,4.3 万星实至名归。
如果你经常需要和数据打交道,Scrapling 值得加入你的工具箱。
以上就是“4.3 万星!Python 最强爬虫框架升级,支持 MCP 和 AI 辅助抓取”的详细内容,想要了解更多Python教程欢迎持续关注编程学习网。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/14151/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料