

如果数据库需要进行水平拆分,这其实是一件很开心的事情,因为它代表公司的业务正在迅猛的增长,对于开发人员而言那就是有不尽的项目可以做,虽然会感觉很忙,但是人过的充实,心里也踏实。
数据库水平拆分简单说来就是先将原数据库里的一张表在做垂直拆分出来放置在单独的数据库和单独的表里后更进一步的把本来是一个整体的表进一步拆分成多张表,每一张表都用独立的数据库进行存储。当表被水平拆分后,原数据表成为了一个逻辑的概念,而这个逻辑表的业务含义需要多张物理表协同完成,因此数据库的表被水平拆分后,那么我们对这张表的操作已经超出了数据库本身提供给我们现有的手段,换句话说我们对表的操作会超出数据库本身所拥有的处理能力,这个时候我就需要设计相关的方案来弥补数据库缺失的能力,这就是数据库水平拆分最大的技术难点所在。
数据库的水平拆分是数据库垂直拆分的升级版,它和垂直拆分更像继承机制里的父子关系,因此水平拆分后,垂直拆分所遇到的join查询的问题以及分布式事务的问题任然存在,由于表被物理拆解增加了逻辑表的维度,这也给垂直拆分里碰到的两个难题增加了更多的维度,因此水平拆分里join查询的问题和分布式事务会变得更加复杂。水平拆分除了垂直拆分两个难题外,它还会产生新的技术难题,这些难题具体如下:
难题一:数据库的表被水平拆分后,该表的主键设计会变得十分困难;
难题二:原来单表的查询逻辑会面临挑战。
在准备本篇文章时候,我看到一些资料里还提到了一些难题,这些难题是:
难题三:水平拆分表后,外键的设计也会变得十分困难;
难题四:这个难题是针对数据的新增操作的,大致的意思是,我们到底按什么规则把需要存储的数据存储在拆分出的那个具体的物理数据表里。
难题三的问题,我在上篇已经给出了解答,这里我进行一定的补充,其实外键问题在垂直拆分就已经存在,不过在讲垂直拆分时候我们没有讲到这个问题,这主要是我设定了一个前提,就是数据表在最原始的数据建模阶段就要抛弃所有外键的设计,并将外键的逻辑抛给服务层去完成,我们要尽全力减轻数据库承担的运算压力,其实除了减轻数据库运算压力外,我们还要将作为存储原子的表保持相对的独立性,互不关联,那么要做到这点最直接的办法就是去掉表与表之间关联的象征:外键,这样我们就可以从根基上为将来数据库做垂直拆分和水平拆分打下坚实的基础。
至于难题四,其实问题的本质是分库分表后具体的数据在哪里落地的问题,而数据存储在表里的关键障碍其实就是主键,试想一下,我们设计张表,所有字段我们都准许可以为空,但是表里有个字段是绝对不能为空的,那就是主键,主键是数据在数据库里身份的象征,因此我们在主键设计上是可以体现出该数据的落地规则,那么难题四也会随之解决。因此下文我会重点讲解前两个水平拆分的难题。
首先是水平拆分里的主键设计问题,抛开所有主键所能代表的业务含义,数据库里标的主键本质是表达表里的某一条记录的唯一性,在设计数据库的时候我们可以由一个绝对不可重复的字段表示主键,也可以使用多个字段组合起来表达这种唯一性,使用一个字段表示主键,这已经是很原子级的操作,没法做进一步的修改,但是如果使用多个字段表示一个主键对于水平拆分而言就会碰到问题了,这个问题主要是体现在数据到底落地于哪个数据库,关于主键对数据落地的影响我会在把相关知识讲解完毕后再着重阐述,这里要提的是当碰到联合主键时候我们可以设定一个没有任何业务含义的字段来替代,不过这个要看场景了,我倾向于将联合主键各个字段里的值合并为一个字段来表示主键,如果有的朋友认为这样会导致数据冗余,那么可以干脆去掉原来做联合主键的相关字段就是用一个字段表示,只不过归并字段时候使用一个分隔符,这样方便服务层进行业务上的拆分。
由上所述,这里我给出水平拆分主键设计的第一个原则:被水平拆分的表的主键设计最好使用一个字段表示。
如果我们的主键只是表达记录唯一性的话,那么水平拆分时候相对要简单的多,例如在Oracle数据库里有一个sequence机制,这其实就是一个自增数的算法,自增机制几乎所有关系数据库都有,也是我们平时最喜欢使用的主键字段设计方案,如果我们要拆分的表,使用了自增字段,同时这个自增字段只是用来表达记录唯一性,那么水平拆分时候处理起来就简单多了,我这里给出两个经典方案,方案如下:
方案一:自增列都有设定步长的特性,假如我们打算把一张表只拆分为两个物理表,那么我们可以在其中一张表里把主键的自增列的步长设计为2,起始值为1,那么它的自增规律就是1,3,5,7依次类推,另外一张物理表的步长我们也可以设置为2,如果起始值为2,那么自增规律就是2,4,6,8以此类推,这样两张表的主键就绝对不会重复了,而且我们也不用另外做两张物理表相应的逻辑关联了。这种方案还有个潜在的好处,那就是步长的大小和水平数据拆分的粒度关联,也是我们为水平拆分的扩容留有余量,例如我们把步长设计为9,那么理论上水平拆分的物理表可以扩容到9个。
方案二:拆分出的物理表我们允许它最多存储多少数据,我们其实事先通过一定业务技术规则大致估算出来,假如我们估算一张表我们最多让它存储2亿条,那么我们可以这么设定自增列的规律,第一张物理表自增列从1开始,步长就设为1,第二种物理表的自增列则从2亿开始,步长也设为1,自增列都做最大值的限制,其他的依次类推。
那么如果表的主键不是使用自增列,而是业务设计的唯一字段,那么我们又如何处理主键分布问题了?这种场景很典型,例如交易网站里一定会有订单表,流水表这样的设计,订单表里有订单号,流水表里有流水号,这些编号都是按一定业务规则定义并且保证它的唯一性,那么前面的自增列的解决方案就没法完成它们做水平拆分的主键问题,那么碰到这个情况我们又该如何解决了?我们仔细回味下数据库的水平拆分,它其实和分布式缓存何其的类似,数据库的主键就相当于分布式缓存里的键值,那么我们可以按照分布式缓存的方案来设计主键的模型,方案如下:
方案一:使用整数哈希求余的算法,字符串如果进行哈希运算会得出一个值,这个值是该字符串的唯一标志,如果我们稍微改变下字符串的内容,计算的哈希值肯定是不同,两个不同的哈希值对应两个不同字符串,一个哈希值有且只对应唯一一个字符串,加密算法里的MD5,SHA都是使用哈希算法的原理计算出一个唯一标示的哈希值,通过哈希值的匹配可以判断数据是否被篡改过。不过大多数哈希算法最后得出的值都是一个字符加数字的组合,这里我使用整数哈希算法,这样计算出的哈希值就是一个整数。接下来我们就要统计下我们用于做水平拆分的服务器的数量,假如服务器的数量是3个,那么接着我们将计算的整数哈希值除以服务器的数量即取模计算,通过得到的余数来选择服务器,该算法的原理图如下所示:
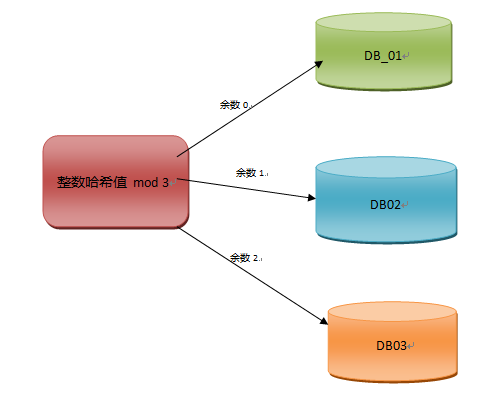
方案二:就是方案一的升级版一致性哈希,一致性哈希最大的作用是保证当我们要扩展物理数据表的数量时候以及物理表集群中某台服务器失效时候才会体现,这个问题我后续文章会详细讨论物理数据库扩容的问题,因此这里先不展开讨论了。
由上所述,我们发现在数据库进行水平拆分时候,我们设定的算法都是通过主键唯一性进行的,根据主键唯一性设计的特点,最终数据落地于哪个物理数据库也是由主键的设计原则所决定的,回到上文里我提到的如果原库的数据表使用联合字段设计主键,那么我们就必须首先合并联合主键字段,然后通过上面的算法来确定数据的落地规则,虽然不合并一个字段看起来也不是太麻烦,但是在我多年开发里,把唯一性的字段分割成多个字段,就等于给主键增加了维度,字段越多,维度也就越大,到了具体的业务计算了我们不得不时刻留心这些维度,结果就很容易出错,我个人认为如果数据库已经到了水平拆分阶段了,那么就说明数据库的存储的重要性大大增强,为了让数据库的存储特性变得纯粹干净,我们就得尽力避免增加数据库设计的复杂性,例如去掉外键,还有这里的合并联合字段为一个字段,其实为了降低难度,哪怕做点必要的冗余也是值得。
解决数据库表的水平拆分后的主键唯一性问题有一个更加直接的方案,这也是很多人碰到此类问题很自然想到的方法,那就是把主键生成规则做成一个主键生成系统,放置在单独一台服务器上统一生成,每次新增数据主键都从这个服务器里获取,主键生成的算法其实很简单,很多语言都有计算UUID的功能,UUID是根据所在服务器的相关的硬件信息计算出的全球唯一的标示,但是这里我并没有首先拿出这个方案,因为它相比如我前面的方案缺点太多了,下面我要细数下它的缺点,具体如下:
缺点一:把主键生成放到外部服务器进行,这样我们就不得不通过网络通信完成主键值的传递,而网络是计算机体系里效率最低效的方式,因此它会影响数据新增的效率,特别是数据量很大时候,新增操作很频繁时候,该缺点会被放大很多;
缺点二:如果我们使用UUID算法做主键生成的算法,因为UUID是依赖单台服务器进行,那么整个水平拆分的物理数据库集群,主键生成器就变成整个体系的短板,而且是关键短板,主键生成服务器如果失效,整个系统都会无法使用,而一张表需要被水平拆分,而且拆分的表是业务表的时候,那么这张表在整个系统里的重要度自然很高,它如果做了水平拆分后出现单点故障,这对于整个系统都是致命的。当然有人肯定说,既然有单点故障,那么我们就做个集群系统,问题不是解决了吗?这个想法的确可以解决我上面阐述的问题,但是我前文讲到过,现实的软件系统开发里我们要坚守一个原则那就是有简单方案尽量选择简单的方案解决问题,引入集群就是引入了分布式系统,这样就为系统开发增加了开发难度和运维风险,如果我们上文的方案就能解决我们的问题,我们何必自讨苦吃做这么复杂的方案呢?
缺点三:使用外部系统生成主键使得我们的水平拆分数据库的方案增加了状态性,而我上面提到的方案都是无状态的,有状态的系统会相互影响,例如使用外部系统生成主键,那么当数据操作增大时候,必然会造成在主键系统上资源竞争的事情发生,如果我们对主键系统上的竞争状态处理不好,很有可能造成主键系统被死锁,这也就会产生我前文里说到的503错误,而无状态的系统是不存在资源竞争和死锁的问题,这洋就提升了系统的健壮性,无状态系统另一个优势就是水平扩展很方便。
这里我列出单独主键生成系统的缺点不是想说明我觉得这种解决方案完全不可取,这个要看具体的业务场景,根据作者我的经验还没有找到一个很合适使用单独主键生成器的场景。
上文里我提出的方案还有个特点就是能保证数据在不同的物理表里均匀的分布,均匀分布能保证不同物理表的负载均衡,这样就不会产生系统热点,也不会让某台服务器比其他服务器做的事情少而闲置资源,均匀分配资源可以有效的利用资源,降低生产的成本提高生产的效率,但是均匀分布式数据往往会给我们业务运算带来很多麻烦。
水平拆分数据库后我们还要考虑水平扩展问题,例如如果我们事先使用了3台服务器完成了水平拆分,如果系统运行到一定阶段,该表又遇到存储瓶颈了,我们就得水平扩容数据库,那么如果我们的水平拆分方案开始设计的不好,那么扩容时候就会碰到很多的麻烦。
注:本文转自夏天的森林
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://phpxs.com/post/3065/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料