
2020
09-27
09-27
Zookeeper的PHP实践 HOT
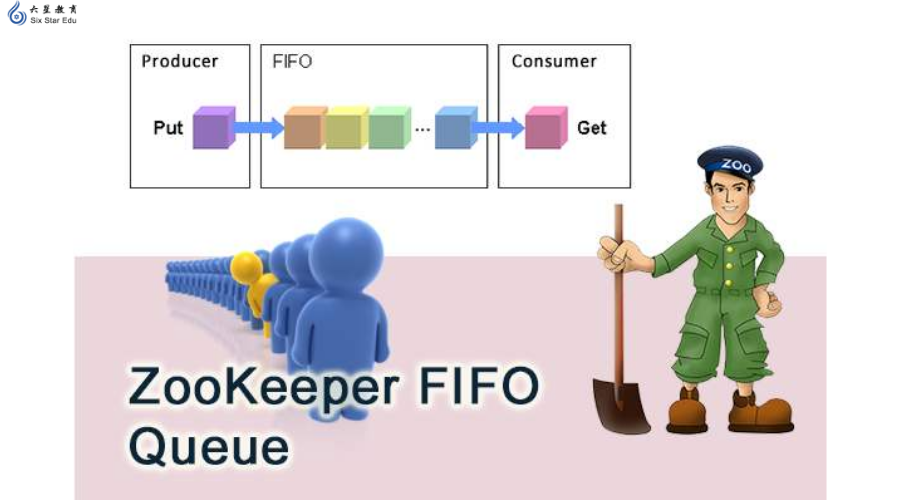 Apache Zookeeper是我最近遇到的最酷的技术,我是在研究Solr Cloud功能的时候发现的。Solr的分布式计算让我印象深刻。你只要开启一个新的实例就能自动在Solr Cloud中找到。它会将自己分派到某个分片中,并确定出自己是一个Leader(源)还是一个副本。不一会儿,你就可以在你的那些服务器上查询到了。即便某些服务器宕机了也可以继续工作。非常动态、聪明、酷。
继续阅读 >
Apache Zookeeper是我最近遇到的最酷的技术,我是在研究Solr Cloud功能的时候发现的。Solr的分布式计算让我印象深刻。你只要开启一个新的实例就能自动在Solr Cloud中找到。它会将自己分派到某个分片中,并确定出自己是一个Leader(源)还是一个副本。不一会儿,你就可以在你的那些服务器上查询到了。即便某些服务器宕机了也可以继续工作。非常动态、聪明、酷。
继续阅读 >
 查看了下阿里 Redis 的性能测试报告如下,能够达到数十万、百万级别的 QPS(暂时忽略阿里对 Redis 所做的优化),我们从 Redis 的设计和实现来分析一下 Redis 是怎么做的。
查看了下阿里 Redis 的性能测试报告如下,能够达到数十万、百万级别的 QPS(暂时忽略阿里对 Redis 所做的优化),我们从 Redis 的设计和实现来分析一下 Redis 是怎么做的。
 我相信大家面试的时候对于 HTTPS 这个问题一定不会陌生,可能你只能简单的说一下与 HTTP 的区别,但是真正的原理是否很清楚呢?他到底如何安全?这一篇让我们用大白话来揭开 HTTPS 的神秘面纱吧!
我相信大家面试的时候对于 HTTPS 这个问题一定不会陌生,可能你只能简单的说一下与 HTTP 的区别,但是真正的原理是否很清楚呢?他到底如何安全?这一篇让我们用大白话来揭开 HTTPS 的神秘面纱吧!
 ping 是个使用频率极高的实用程序,主要用于确定网络的连通性。这对确定网络是否正确连接,以及网络连接的状况十分有用。
ping 是个使用频率极高的实用程序,主要用于确定网络的连通性。这对确定网络是否正确连接,以及网络连接的状况十分有用。
 最常用的数据尽可能放在更高层、更小的存储器中,只有在当前层找不到,才向更低层、更大的存储器中寻找。这也就解释了,当处理大规模数据的时候(指无法将数据一次性存入内存),算法的实际运行时间,往往取决于数据在不同存储级别之间的IO次数。因此,要想提升速度,关键在于减少IO。
最常用的数据尽可能放在更高层、更小的存储器中,只有在当前层找不到,才向更低层、更大的存储器中寻找。这也就解释了,当处理大规模数据的时候(指无法将数据一次性存入内存),算法的实际运行时间,往往取决于数据在不同存储级别之间的IO次数。因此,要想提升速度,关键在于减少IO。
 本文从 Git 与 SVN 的对比入手,介绍如何通过 Git-SVN 开始使用 Git,并总结平时工作高频率使用到的 Git 常用命令。
本文从 Git 与 SVN 的对比入手,介绍如何通过 Git-SVN 开始使用 Git,并总结平时工作高频率使用到的 Git 常用命令。
 Tars是基于名字服务使用Tars协议的高性能RPC开发框架,同时配套一体化的服务治理平台,帮助个人或者企业快速的以微服务的方式构建自己稳定可靠的分布式应用。
Tars是基于名字服务使用Tars协议的高性能RPC开发框架,同时配套一体化的服务治理平台,帮助个人或者企业快速的以微服务的方式构建自己稳定可靠的分布式应用。
 首先跟大家说明一点,我们做 IT 类的外包开发,是非标品开发,所以很有可能在开发过程中会有这样那样的需求修改,而这种需求修改很容易造成扯皮,进而影响到费用支付,甚至出现做完了项目收不到钱的情况。
首先跟大家说明一点,我们做 IT 类的外包开发,是非标品开发,所以很有可能在开发过程中会有这样那样的需求修改,而这种需求修改很容易造成扯皮,进而影响到费用支付,甚至出现做完了项目收不到钱的情况。
 MySQL使用索引时需要索引有序,假设现在建立了"name,age,school"的联合索引,那么索引的排序为: 先按照name排序,如果name相同,则按照age排序,如果age的值也相等,则按照school进行排序。
MySQL使用索引时需要索引有序,假设现在建立了"name,age,school"的联合索引,那么索引的排序为: 先按照name排序,如果name相同,则按照age排序,如果age的值也相等,则按照school进行排序。
 做运维,不怕出问题,怕的是出了问题,抓不到现场,两眼摸黑。所以,依靠强大的监控系统,收集尽可能多的指标,意义重大。但哪些指标才是有意义的呢,本着从实践中来的思想,各位工程师在长期摸爬滚打中总结出来的经验最有价值。
做运维,不怕出问题,怕的是出了问题,抓不到现场,两眼摸黑。所以,依靠强大的监控系统,收集尽可能多的指标,意义重大。但哪些指标才是有意义的呢,本着从实践中来的思想,各位工程师在长期摸爬滚打中总结出来的经验最有价值。
 总体上不是特别困难,因为功能十分简单,下一步的任务是加入注册功能,以及验证码功能。
总体上不是特别困难,因为功能十分简单,下一步的任务是加入注册功能,以及验证码功能。
 常用方法可以采用布隆过滤器方法进行数据拦截,其次可以还有一种解决思路,就是如果请求的数据为空,将空值也进行缓存,就不会发生穿透情况
常用方法可以采用布隆过滤器方法进行数据拦截,其次可以还有一种解决思路,就是如果请求的数据为空,将空值也进行缓存,就不会发生穿透情况
 select …from table where exists (subquery)可以理解为:将主查询的数据。放到子查询中做条件验证,根据验证结果(true or false)来决定主查询的数据是否得以保留
select …from table where exists (subquery)可以理解为:将主查询的数据。放到子查询中做条件验证,根据验证结果(true or false)来决定主查询的数据是否得以保留
 近学习了下kafka,为方便搭建环境,使用docker进行部署。
需要首先安装docker的环境。要求操作系统是linux的64位系统。
近学习了下kafka,为方便搭建环境,使用docker进行部署。
需要首先安装docker的环境。要求操作系统是linux的64位系统。
 本文介绍了 8 款免费的 MySQL 数据库常用建模工具,包括客户端软件和在线工具。客户端软件提供了强大完善的建模功能;在线建模工具无需安装即可使用,功能相对简单一些。除了以上介绍的建模工具之外,你还了解或者使用过那些好用不贵的软件,欢迎推荐!
本文介绍了 8 款免费的 MySQL 数据库常用建模工具,包括客户端软件和在线工具。客户端软件提供了强大完善的建模功能;在线建模工具无需安装即可使用,功能相对简单一些。除了以上介绍的建模工具之外,你还了解或者使用过那些好用不贵的软件,欢迎推荐!
 要明白docker容器内存是如何计算的,首先要明白linux中内存的相关概念。
使用free命令可以查看当前内存使用情况。
要明白docker容器内存是如何计算的,首先要明白linux中内存的相关概念。
使用free命令可以查看当前内存使用情况。
 最近在使用kubeadm时,被各种连接不上搞到崩溃。费了很多力气,基本都解决了。这里统一整理了国内的一些镜像源,apt源,kubeadm源等,以便查阅。
最近在使用kubeadm时,被各种连接不上搞到崩溃。费了很多力气,基本都解决了。这里统一整理了国内的一些镜像源,apt源,kubeadm源等,以便查阅。
 版本说明:本文中docker版本主要基于1.10版本,操作系统为centos7。devicemapper在文中缩写为dm。
版本说明:本文中docker版本主要基于1.10版本,操作系统为centos7。devicemapper在文中缩写为dm。
 近期,线上有个重要Mysql客户的表在从5.6升级到5.7后master上插入过程中出现"Duplicate key"的错误,而且是在主备及RO实例上都出现。以其中一个表为例,迁移前通过“show create table” 命令查看的auto increment id为1758609, 迁移后变成了1758598,实际对迁移生成的新表的自增列用max求最大值为1758609。用户采用的是Innodb引擎,而且据运维同学介绍,之前碰到过类似问题,重启即可恢复正常。
近期,线上有个重要Mysql客户的表在从5.6升级到5.7后master上插入过程中出现"Duplicate key"的错误,而且是在主备及RO实例上都出现。以其中一个表为例,迁移前通过“show create table” 命令查看的auto increment id为1758609, 迁移后变成了1758598,实际对迁移生成的新表的自增列用max求最大值为1758609。用户采用的是Innodb引擎,而且据运维同学介绍,之前碰到过类似问题,重启即可恢复正常。
 理解基本表的性质后,在设计数据库时,就能将基本表与中间表、临时表区分开来。
理解基本表的性质后,在设计数据库时,就能将基本表与中间表、临时表区分开来。
 监控指标
性能指标:Performance
内存指标: Memory
基本活动指标:Basic activity
持久性指标: Persistence
错误指标:Error
监控指标
性能指标:Performance
内存指标: Memory
基本活动指标:Basic activity
持久性指标: Persistence
错误指标:Error
 关于RabbitMQ
出身:诞生于金融行业的消息队列
语言:Erlang
协议:AMQP(Advanced Message Queuing Protocol 高级消息队列协议)
关键词:内存队列,高可用,一条消息
关于RabbitMQ
出身:诞生于金融行业的消息队列
语言:Erlang
协议:AMQP(Advanced Message Queuing Protocol 高级消息队列协议)
关键词:内存队列,高可用,一条消息
 本篇博客首先从开篇的提出问题,建表到使用jdbcTemplate去测试不同id的生成策略在大数据量的数据插入表现,然后分析了id的机制不同在mysql的索引结构以及优缺点,深入的解释了为何uuid和随机不重复id在数据插入中的性能损耗,详细的解释了这个问题。
在实际的开发中还是根据mysql的官方推荐最好使用自增id,mysql博大精深,内部还有很多值得优化的点需要我们学习。
本篇博客首先从开篇的提出问题,建表到使用jdbcTemplate去测试不同id的生成策略在大数据量的数据插入表现,然后分析了id的机制不同在mysql的索引结构以及优缺点,深入的解释了为何uuid和随机不重复id在数据插入中的性能损耗,详细的解释了这个问题。
在实际的开发中还是根据mysql的官方推荐最好使用自增id,mysql博大精深,内部还有很多值得优化的点需要我们学习。
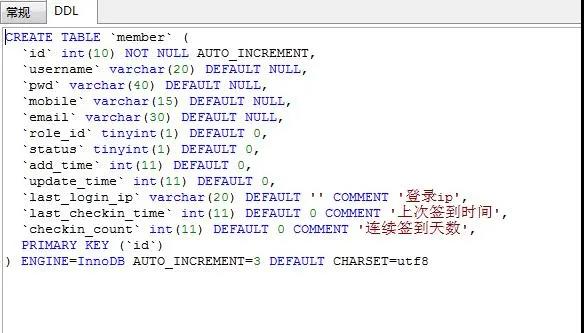 好啦,两种方式介绍完了,各有利弊,你喜欢哪种方式呢?
欢迎讨论!
好啦,两种方式介绍完了,各有利弊,你喜欢哪种方式呢?
欢迎讨论!