

使用in的sql:select * from A where id in (select id from B)
等价于:
for select id from Bfor select * from A where A.id = B.id
当B表的数据小于A表的数据集时,用in
使用exists的sql:select * from A where exists (select 1 from B where B.id=A.id)
等价于:
for select id from Afor select * from B where B.id = A.id
当A表的数据小于B表的数据集时,用exists
EXISTS:
select …from table where exists (subquery)可以理解为:将主查询的数据。放到子查询中做条件验证,根据验证结果(true or false)来决定主查询的数据是否得以保留
提示:
- exists(subquery)只返回true或者false,因此子查询的select *可以使select 1或其他,实际执行时候会忽略掉select清单,因此没有区别
- exists子查询的实际执行过程可能经历了优化而不是我们理解上的逐条对比,如果担忧效率问题,可进行实际检验以确认效率是否有问题
- exists子查询往往也可以用条件表达式、其他子查询或者join来代替
索引的作用,除了查找还有一个就是排序

可以看到Extra里有一个Using filesort用来排序,mysql里面排序的有filesort和索引自带的排序,当然我们建立的有复合索引,如果能用到索引的排序,那么效率将会提升很多,下面我们来看看怎么用上索引排序



结论:where后面跟的索引和order by后面的排序字段满足最佳最前缀原则,并且也是范围之后就失效
oder by后面的子段自己满足左前缀原则也可以



结论:order by后面的字段可以不考虑where用到的索引,自己满足做前缀法则来使用复合索引即可用到索引排序,那么第三个为什么没用到呢?当用到name asc的时候,组合索引用的是升序,但是后面的age来也用这个索引排序的时候发现是升序用不了,就产生了个filesort的降序排序。证明如下:

第一个name满足做前缀来使用复合索引的升序排序,第二个name也满足做前缀法则,使用了复合索引的降序排序,这样其实用了两次索引,一次用索引的升序,一次用降序



这两个出现的原因就是,前面where已经创建了一个索引,age>20导致索引age后面的pos失效,但是order by从age开始的排序还是可以用的;但是order by pos失效(因为pos失效了),索引图二产生了filesort;图三,order by age pos虽然pos失效了,但是再从age开始,pos也又可以用了
结论:我们得出首先where后面如果用上索引会开一个索引来查找,下一个字段如果满足条件就接着用这个索引来查找;到了order by后面的字段如果能和where后的字段满足做前缀法则就可以接着用where后面开的的索引来进行排序;否则就自己在开一个(升序或者降序)索引来排序,如果order by有多个字段也是一样的,能用到前面字段开的索引就用,否则自己就在开一个

sql慢查询分析
慢查询日志开启方法一:
在配置文件my.cnf或my.ini中在[mysqld]一行下面加入两个配置参数log-slow-queries=/data/mysqldata/slow-query.loglong_query_time=2注:log-slow-queries参数为慢查询日志存放的位置,一般这个目录要有mysql的运行帐号的可写权限,一般都将这个目录设置为mysql的数据存放目录;long_query_time=2中的2表示查询超过两秒才记录;在my.cnf或者my.ini中添加log-queries-not-using-indexes参数,表示记录下没有使用索引的查询。log-slow-queries=/data/mysqldata/slow-query.loglong_query_time=10log-queries-not-using-indexes
慢查询日志开启方法二:
我们可以通过命令行设置变量来即时启动慢日志查询。由下图可知慢日志没有打开,slow_launch_time=# 表示如果建立线程花费了比这个值更长的时间,slow_launch_threads 计数器将增加
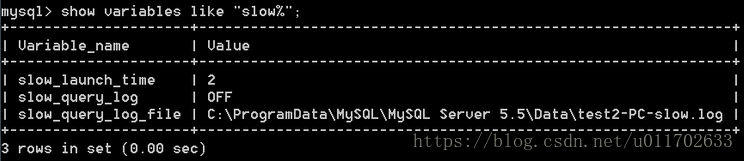
设置慢日志开启
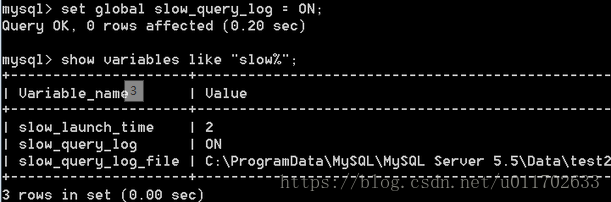
MySQL后可以查询long_query_time 的值
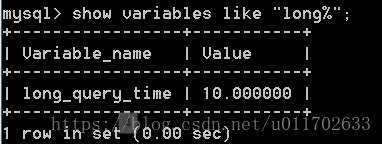
为了方便测试,可以将修改慢查询时间为5秒
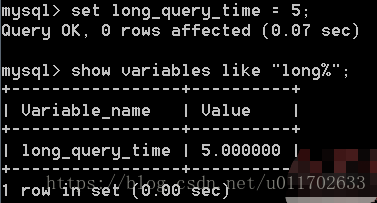
执行select sleep(6)睡眠6秒,在慢查询日志文件下面就有一条记录了
当然mysql自带一个分析工具,具体命令见下:


show profile
- 查看命令:show variables like ‘profiling%’;默认关闭,使用前需要开启;
- 开启命令:set profiling=on;
- 开启之后,运行sql会被mysql记录
- 查看执行sql记录结果(带有sql的id和执行时间):Show profiles;
- 诊断sql :show profile cpu, block io for query 问题sql的id;
日常开发需要注意的结论:
converting HEAP to MyISAM :查询结果太大,内存都不够用了,往磁盘上搬了;
creating tmp table :创建临时表,拷贝数据到临时表,然后再删除;
copying to tmp table on disk :把内存中临时表复制到磁盘,危险!!!
locked
注:以上四个中若出现一个或多个,表示sql 语句 必须优化。
输出内容里面的字段表示含义:
- ALL: 显示所有的开销信息
- BLOCK IO :显示块IO相关开销
- CONTEXT SWITCHS: 上下文切换相关开销
- CPU : 显示cpu 相关开销
- IPC: 显示发送和接收相关开销
- MEMORY:显示内存相关开销
- PAGE FAULTS:显示页面错误相关开销信息
- SOURCE :显示和Source_function ,Source_file,Source_line 相关的开销信息
- SWAPS:显示交换次数相关的开销信息
- Status :sql 语句执行的状态
- Duration: sql 执行过程中每一个步骤的耗时
- CPU_user: 当前用户占有的cpu
- CPU_system: 系统占有的cpu
- Block_ops_in : I/O 输入
- Block_ops_out : I/O 输出
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/7538/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料