

一个高性能的数据访问层需要很多关于数据库的内部结构、JDBC、JPA、Hibernate以及很多优化商业应用的技术建议。
SQL Statement Logging:SQL语句日志如果你正在使用譬如Hibernate或者MyBatis这样的ORM框架,那么可以参考 验证执行语句的效率 。另外推荐一个 测试中断言机制 可以帮你在提交代码之前就发现很多的查询问题。
Connection management:连接管理数据库连接一直是数据库中比较耗时的操作,因此建议是务必使用数据库连接池 机制。另外,数据库连接还受到数据库底层的限制,因此也需要合理有效地释放无用的数据库连接。在性能调优中,我们经常需要测试并且设置合理的连接池大小。这里推荐一个FlexyPool工具可以帮助你选择生产环境下合适的连接池大小。
JDBC Batching:批量JDBC操作JDBC Batching允许在单次数据库连接中发送多个SQL语句。 这篇博客里进行了对比可以看出Batch操作的性能提升非常巨大 ,无论是在客户端还是数据库端。 PreparedStatements 是不错的用于Batching操作的选择,像Oracle也仅支持基于PreparedStatements的Batching操作。
JDBC中已经基于PreparedStataement.addBatch 与 PreparedStataement.executeBatch)提供了Batching操作的辅助,不过如果打算手动的构造Batching操作,那么在设计阶段就要考虑到是否需要引入Batching。如果你用的是Hibernate,那么可以用简单的配置就开启Batching,Hibernate 5.2 提供了 Session级别的Batching, 也是非常方便的。
Statement Caching:语句缓存Statement Caching算是最不常用的几种优化手段之一了,你可以利用PreparedStatements同时在客户端(Driver)或者数据库端同时缓存语句。
Hibernate Identifiers如果你是使用Hibernate作为ORM工具,那么IDENTITY生成器可能会影响到你的性能,因为它会禁止掉JDBC Batching。Table生成器也不是啥好选择,它会使用独立的事务上下文进行捕获操作,而导致底层的事务日志承受额外的压力,并且导致了每次连接池中的新的请求都需要一个新的Identifier。因此笔者还是推荐SEQUENCE生成器,SQL Server在2012版本之后也开始支持了该生成器。
选择合适的列类型在数据库设计的时候,我们应该尽可能地选用合适的列类型,这样可以让你的数据库以最合适的方式去索引存储你的数据。譬如在PostgreSQL中你应该使用inet来存放IPv4的地址,特别是Hibernate还允许你自定义数据类型,这样方面和数据库中的列类型一一对应。
Relationships:映射关联Hibernate提供了很多的关系映射,不过并不是所有的映射都是性能优化的。
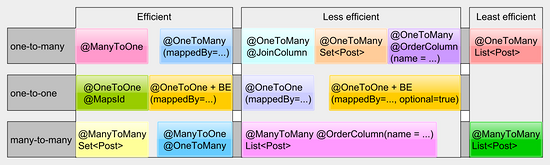
我们在开发的过程中需要注意避免单向的关系映射,以及@ManyToMany这种映射。对于集合查询而言,双向的@OneToMany关系才是值得推荐的。
Inheritance:继承继承是面向对象的语言中的不可或缺的一部分,但这也是关系型数据库与面向对象的语言之间的不协调最甚的地方。JPA提供了譬如SINGLE_TABLE、JOIN以及TABLE_PER_CLASS来处理继承映射的问题,而这几个办法都是各有千秋。
- SINGLE_TABLE在SQL语句中的表现最好,不过不能使用NOT NULL约束,数据完整性的控制较差。
- JOIN 通过更复杂的语句控制来保证了数据的完整性,只要你不使用多态查询或者@OneToMany关系注解,那一切还好。
- 应该避免使用TABLE_PER_CLASS,它基本上无法生成高效的SQL语句。
在使用JPA或者Hibernate时候,应该随时注意持久化上下文的大小,避免同时管理过多的实体类。通过限制受管实体类的数量,我们可以更好地进行内存管理,而默认的脏检测机制也会有更好的效果。
只获取必要的数据获取过多的冗余数据可能是导致数据访问层性能下降的原因之一,即使是包含了投影等操作,对于实体的查询应该也是排外的,即不会引入冗余数据的。我们应该只获取那些业务逻辑需要到的数据,这里推荐使用DTO Projections。过早的数据获取以及Open Session In View这种反模式都是要被避免的。
Caching:缓存 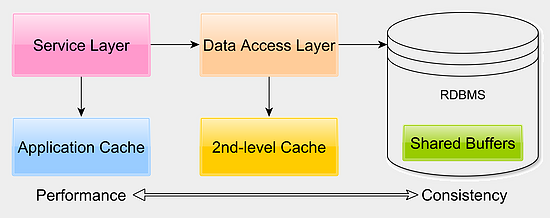
关系型数据库使用了很多的内存缓冲结构体来避免大量的磁盘访问,但是我们往往忽略了数据库缓存。我们可以通过调整数据库查询引擎,将更多的内容留于内存中以避免磁盘查询最终明显的减少响应耗时。应用层的缓存则利用高速副本的方式来保证低响应时间。而Second-Level缓存能够有效减少读写事务的响应时间,特别是在主从复制架构中。根据不同的应用取钱,Hibernate提供了 READ_ONLY, NONSTRICT_READ_WRITE, READ_WRITE, 以及 TRANSACTIONAL这几种方式。
Concurrency Control:并发控制在考虑性能和数据完整性的时候,事务隔离层 就变得至关重要。对于并发较高的应用,需要避免更新失败, 可以使用 乐观锁或者扩展的持久化上下文.
而为了避免 乐观锁中的 false positives, 可以使用 无版本的乐观控制 或者 基于写属性集的实体划分 。
提高数据库查询能力虽然你是用了JPA或者Hibernate,但是你可以用一些原生查询,建议是好好利用 Window Functions , CTE (Common Table Expressions), CONNECT BY, PIVOT等等。这些工具能够避免你一次性传输过多的数据进入应用层,如果你可以把这个操作托付给数据库层进行,那么可以仅关心最终的结果,从而节约了磁盘IO与网络带宽。
集群扩展关系型数据库能够方便地进行扩展,像Facebook、Twitter、Pinterest这些大公司都扩展了数据库系统:
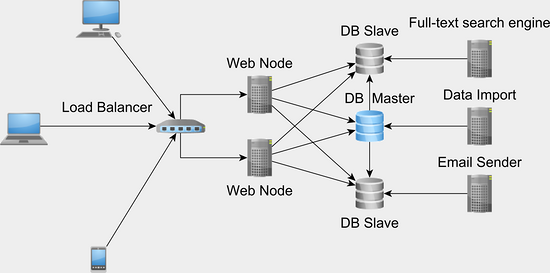
是两种常用的增加吞吐量的扩展方式,你应该合理的组合应用这些方式从而提高你的商业应用的能力。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/5124/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料