

0、导读
主从复制环境中,IO、SQL线程都很正常,也没设置过滤规则,但数据就是无法复制到slave上,什么原因?
1、问题描述
事实上,这个案例发生已经有一阵子了,一直拖到现在我才整理。
发现一个主从环境中,slave上的io_thread、sql_thread状态均正常,relay log也正常接收来自master的event,但slave上却无法正常应用这些event,个别表数据没有复制过来。而且slave上的binlog也没有记录这些表上的操作。
2、原因分析
接到现场后,第一反应是是先检查是否设置了ignore/do规则,发现并不是这个原因引起的。
我自己手动测试创建了个新的测试表,写了几条数据,发现在slave上这个表能被创建,但写入的测试数据仍旧无法复制过来。这说明,slave上的复制并不是完全失效的,只是有特殊情形下才会失效。
结合上面的问题,想到了可能是因为binlog format以及事务隔离级别等原因导致失效的,于是做了下面的尝试。
//首先修改事务隔离级别为RR(此前是RC),尽可能保证主从数据一致性
root@imysql [mydb]> set session transaction isolation level repeatable read;
//测试写入2条数据
root@imysql [mydb]> insert into z select 5,5;
root@imysql [mydb]> insert into z select 6,6;
经过观察,这2条数据不可以复制到slave上。
//修改binlog format为statement(此前是row),再写入2条数据
root@imysql [mydb]> set session binlog_format=’statement’;
root@imysql [mydb]> insert into z select 7,7;
root@imysql [mydb]> insert into z select 8,8;
经过观察,这2条数据则可以复制到slave上。
现在至少表面上看起来,是由于binlog format+事务隔离级别综合因素引起的,所以我们来对比下不同binlog format下的binlog有什么区别吧。

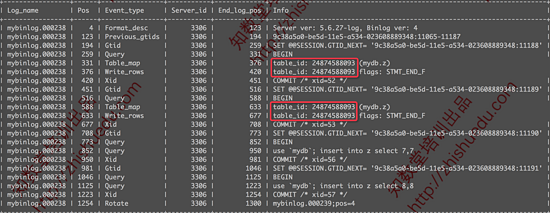
这些日志中,前两条是row模式下的日志,后两条则是statement模式下的。我们注意到红框中内容是:table_id: 24874588093,正是由于这个原因导致了slave无法正常复制数据。
正常情况下,row模式下的binlog event应该是这样的:

在上面的日志中,我们看到的是:table_id: 108,这种情况下就可以正常复制了。
现在问题很明确了,就是由于binlog中table id异常导致无法复制。那么,到底什么原因导致table id出现异常呢。
3、案例建议
搜索了一些资料,发现也有别人遇到同样的问题。我就不多啰嗦了,大家可以看下方参考文章详细了解下。简言之,发生这中问题的原因,主要是因为table cache不够了,导致要频繁打开、关闭table,导致table id急剧增长,因而导致主从数据复制失败。
解决办法有几个:
- 加大 table_cache_size,或者 table_open_cache 值,以及 table_definition_cache 选项。一般设置不低于总table数量的1.5倍,更严谨的话,要看 Open_tables 和 Opened_tables 这两个status值。Open_tables 表示当前正被打开的table数量,而 Opened_tables 表示历史上反复打开table的总次数。如果 Opened_tables 值特别高,表明 table cache 很可能不够用所致。
- 择机重启主库实例,让table id的值再次从0开始计数。
- 临时解决方案:把binlog format改成statement,并且把事务隔离级别改成RR,尽量避免数据不一致的风险。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/5144/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料