

爬虫,几家欢喜几人愁。爬者,拿到有利数据,分析行为,产生价值。被爬者,一是损失数据,二是遇到不怀好意的爬虫往往被全站复制或服务器受冲击而无法服务。今天说的是一只友好的爬虫是如何构建出来的,请勿用它伤害他人。
爬虫一生所遇
俗话说,如果我比别人看得远些,那是因为我站在巨人们的肩上。前人之鉴,后人之师。小爬虫在胎教的时候就该传授它的前辈参悟的人生经验,了解网络的可怕之处。看看我提供的胎教课程:
-
被爬网站偶然出现服务无法响应,需重试
-
网站检查某些header,特别是referer这个参数,请警惕
-
访问频率限制,短时间单IP或者单帐号内往往有频率限制。更高级的还可能用近段时间访问频率,时间段请求频率来识别爬虫行为。
-
目标爬取网站需要登录
-
网站采用js运算产生最终页面
小爬虫身份成谜
爬虫如此泛滥,网站安能不防备,识别之,封禁之爬虫就无可奈何了。你问该如何做?我们从tcp/ip的角度来看,网站可以识别到ip地址。那么如此说来,网站封的很有可能就是ip地址。网络上可是有代理服务器这种可怕东西存在的,爬虫依靠代理服务器伪装身份,一旦被封禁,换代理又可以愉快的玩耍了。
代理服务器那里来?这种东西,用搜索引擎一搜索就有了。如果你想省时省力,直接购买。然而在手头拮据的时候,只能寻找一些免费的代理。一般来说每个网站都会提供一点点免费代理,我们只要勤快定时定后抓取入库即可,集腋成仇。
千万不要相信代理服务器就是可用的,要定时检查入库的代理是否有用,除了定时检查之外,我们还可以借助squid,我们只要把代理往里面一丢,爬虫代理直接设置成squid的ip和端口,这货就会自动挑选可用代理来使用,省了自己定时检测。
题外话:免费的往往是最贵的,特别ip,带宽这种资源。网上提供的代理往往会注入一些广告js等东西,这个自己想解决方案了。
一个坚持不懈的爬虫
一只爬虫的最高境界就是全自动化,无需人为干预,不过这种事情想想即可,不可能实现的。但是小爬虫也有自己的修养的,最起码在各种异常面前不能一次就退缩了吧,出错重试多次是必须的,最重要的是出现异常进程不能中断,任务还是得接着完成的。
最简单的方法是什么呢?在循环里面搞一个try catch,是不是完美呢?大伙来看看这个例子:
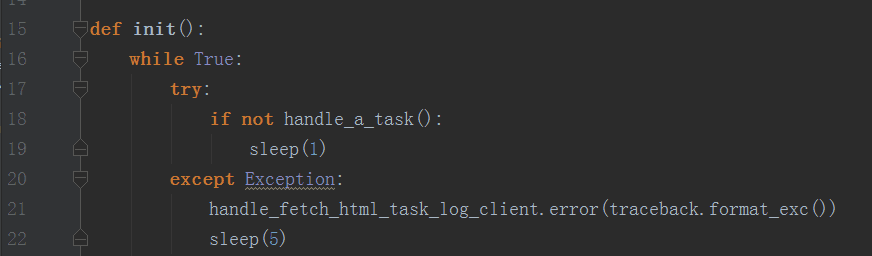
然而这样子写是不道德,最重要的还不够优雅,所以再看看下面这个例子:
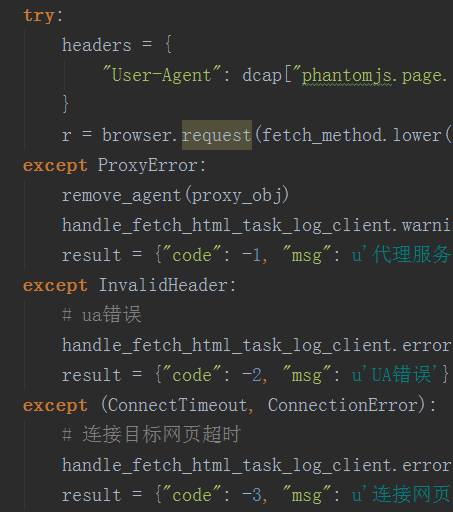
应该分别抓取各种错误来分别处理,因为各种出错的应对策略是不一样的。
小爬虫也需要团队作战
假如说,某一天爬虫接到任务,一天之内要爬取100万个网页。假设一个网页需要10秒,单进程单线程的爬虫是没法实现的。这个时候我们可以利用下面几个方案:
-
多线程(然而对于python来说有GIL问题,所以优势不明显)
-
多进程,一旦使用多进程就需要解决任务分配问题,和进程管理问题,这个时候我们可以使用消息中间件来分配任务,简简单单上一个redis队列,问题就迎刃而解了。
-
爬虫集群,任务分配依旧可以使用消息中间件,而部署我们可以使用伟大的docker,环境都无需配置了。
爬虫与浏览器的爱恨情愁
有很多网站呢,要么登录的时候需要提交一些js计算后的值。有些数据还要js处理生成,如果我们的爬虫要模拟js来运算,还得针对每一个网站进行处理,这可一点都不优雅。
那么咋办呢?最简单的方案是,既然我们的浏览器能渲染,那么我们就去调用浏览器来拿到最终页面嘛,平时那些稀奇古怪的交互也一并解决了。对于python来说,调用浏览器一点难度都没有,因为有神器selenium。
selenium可以很方便的使用python与谷歌呀火狐呀PhantomJS等这些浏览器交互,缺点是只是模拟了GET请求,也许你会说不是可以执行ajax,听我一句劝,你会被跨域请求坑住的。为了实现其它请求请再上一个库selenium-requests,然而这库的使用方法请查考requests,文档这样子也是无奈。
小爬虫优雅架构
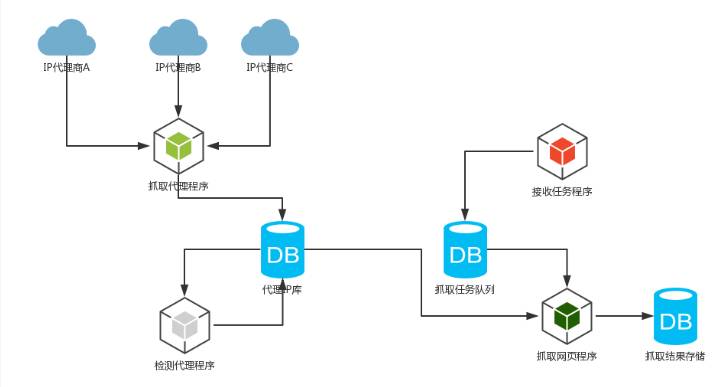
爬虫与反爬虫的较量是长久的,爬取过程千万要注意抓取页面异常的情况,触发反爬虫预警达到一定次数,帐号或者IP就会被冻结。模拟登陆验证码识别可以借助第三方平台,起码比自己写的验证码识别高效得多。
看了这么多文章,是不是觉得我们的文章质量高呢?怎么说我们都是原创文章,然而我们是不定时更新的,如果你愿意等待就关注我们,谢谢您的阅读。
来自:http://mp.weixin.qq.com/s/TFOruaVaZ_VVJHENrLX_Eg
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/5639/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料