

今天主要和大家说的是分类检测过程中,一些稀疏和集成学习的相关知识,首先和大家说下图像目标定位与检测的方法分类。
众所周知,当前是信息时代,信息的获得、加工、处理以及应用都有了飞跃发展。人们认识世界的重要知识来源就是图像信息,在很多场合,图像所传送的信息比其他形式的信息更丰富、真切和具体。人眼与大脑的协作使得人们可以获取、处理以及理解视觉信息,人类利用视觉感知外界环境信息的效率很高。事实上,据一些国外学者所做的统计,人类所获得外界信息有 80% 左右是来自眼睛摄取的图像。由此可见,视觉作为人类获取外界信息的主要载体,计算机要实现智能化,就必须能够处理图像信息。尤其是近年来,以图形、图像、视频等大容量为特征的图像数据处理广泛应用于医学、交通、工业自动化等领域。
自然界的一切图像都是连续变化的模拟图像,在日常生活中,这些图像中的运动目标往往是我们比较关心的,如:行人、行驶的交通工具以及其他的物体。目标检测和识别是计算机视觉和数字图像处理的一个热门方向,广泛应用于机器人导航、智能视频监控、工业检测、航空航天等诸多领域。因此,目标识别也就成为了近年来理论和应用的研究热点,它是图像处理和计算机视觉学科的重要分支,也是智能监控系统的核心部分。它的目的就是如何快速、准确地检测出监控视频中的目标,即从序列图像中将目标提取出来。
随着社会经济的不断发展,城市化步伐的不断加速,城市的工作、生活秩序显得越来越紊乱,实时的人数统计有着重要意义。如:可以通过统计等候电梯的人数来优化调度电梯,以此提高电梯的利用率,减少用户的等待时间。可以通过统计经过十字路口、丁字路口人群流动繁忙的交通场合的人数,可以合理安排交通警察或保安人员的工作时间和工作额度。
目标识别 是指用计算机实现人的视觉功能,它的研究目标就是使计算机具有从一幅或多幅图像或者是视频中认知周围环境的能力(包括对客观世界三维环境的感知、识别与理解)。目标识别作为视觉技术的一个分支,就是对视场内的物体进行识别,如人或交通工具,先进行检测,检测完后进行识别,然后分析他们的行为。目前,国际上许多高校和研究所,如麻省理工学学院、牛津大学等都专门设立了针对目标检测和识别的研究组或者研究实验室。美英等国家已经研究了大量的相关项目。一些著名公司和研究机构,如 IBM 、 Microsoft 、麻省理工学院等近几年来投入了大量的人力物力来进行智能监控系统的研究,部分成果已经转化为产品投入了市场。
目前在国内的研究机构中,中国科学院自动化研究所下属的模式识别国家重点实验室视觉监控研究处于领先地位。自动化所在交通场景视觉监控、人的运动视觉监控和行为模式识别方面进行了深入研究。另外他们也总结了英国雷丁大学 VIEWS 的车辆交通监控原型系统的研究经验,在之前的理论研究的基础上,自行设计并初步实现了一个拥有完全自主知识产权的交通监控原型系统 vstart(Visual surveillance star) 。国内其他高校如上海交通大学、北京航空航天大学也对这方面进行了研究。
目标识别
目标识别的任务
识别出图像中有什么物体,并报告出这个物体在图像表示的场景中的位置和方向。对一个给定的图片进行目标识别,首先要判断目标有没有,如果目标没有,则检测和识别结束,如果有目标,就要进一步判断有几个目标,目标分别所在的位置,然后对目标进行分割,判断哪些像素点属于该目标。
目标识别的过程
目标的识别大体框架:
目标识别往包含以下几个阶段:预处理,特征提取,特征选择,建模,匹配,定位。目前物体识别方法可以归为两类:一类是基于模型的或者基于上下文识别的方法,另一类是二维物体识别或者三维物体识别方法。对于物体识别方法的评价标准, Grimson 总结出了大多数研究者主要认可的 4 个标准:健壮性( robustness )、正确性( correctness )、效率( efficiency )和范围( scope )。
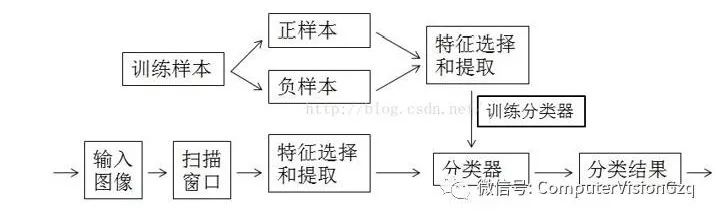
训练分类器所需训练样本的创建
训练样本包括正样本和负样本;其中正例样本是指待检目标样本 ( 例如人脸或汽车等 ) ,负样本指其它不包含目标的任意图片(如背景等),所有的样本图片都被归一化为同样的尺寸大小 ( 例如, 20x20) 。
预处理
预处理是尽可能在不改变图像承载的本质信息的前提下,使得每张图像的表观特性(如颜色分布,整体明暗,尺寸大小等)尽可能的一致,以便于之后的处理过程。预处理有生物学的对应。瞳孔,虹膜和视网膜上的一些细胞的行为类似于某些预处理步骤,如自适应调节入射光的动态区域等等。预处理和特征提取之间的界线不完全分明。有时两者交叉在一起。它主要完成模式的采集、模数转换、滤波、消除模糊、减少噪声、纠正几何失真等预处理操作。因此也要求相应的设备来实现。
预处理经常与具体的采样设备和所处理的问题有关。例如,从图象中将汽车车牌的号码识别出来,就需要先将车牌从图像中找出来,再对车牌进行划分,将每个数字分别划分开。做到这一步以后,才能对每个数字进行识别。以上工作都应该在预处理阶段完成。
从理论上说,像预处理这种先验式的操作是不应该有的。因为它并不为任何目的服务,所以完全可以随意为之而没有 “ 应该怎么做 ” 的标准,大部分情况下预处理是看着实验结果说话。这是因为计算机视觉目前没有一个整体的理论框架,无法从全局的高度来指导每一个步骤应该如何进行。在物体识别中所用到的典型的预处理方法不外乎直方图均衡及滤波几种。像高斯模糊可以用来使得之后的梯度计算更为准确;而直方图均衡可以克服一定程度的光照影响。值得注意的是,有些特征本身已经带有预处理的属性,因此不需要再进行预处理操作。
预处理通常包括五种基本运算:
(1) 编码:实现模式的有效描述,适合计算机运算。
(2) 阀值或者滤波运算:按需要选出某些函数,抑制另一些。
(3) 模式改善:排除或修正模式中的错误,或不必要的函数值。
(4) 正规化:使某些参数值适应标准值,或标准值域。
(5) 离散模式运算:离散模式处理中的特殊运算。
特征提取
由图像或波形所获得的数据量是相当大的。例如,一个文字图像可以有几千个数据,一个心电图波形也可能有几千个数据。为了有效地实现分类识别,就要对原始数据进行变换,得到最能反映分类本质的特征。这就是特征选择和提取的过程。一般我们把原始数据组成的空间叫测量空间,把分类识别赖以进行的空间叫做特征空间,通过变换,可把在维数较高的测量空间中表示的模式变为在维数较低的特征空间中表示的模式。特征提取是物体识别的第一步,也是识别方法的一个重要组成部分,好的图像特征使得不同的物体对象在高维特征空间中有着较好的分离性,从而能够有效地减轻识别算法后续步骤的负担,达到事半功倍的效果,下面是对一些常用的特征提取方法:
( 1 )颜色特征。颜色特征描述了图像或图像区域所对应的景物的表面性质,常用的颜色特征有图像片特征、颜色通道直方图特征等。
( 2 )纹理特征。纹理通常定义为图像的某种局部性质,或是对局部区域中像素之间关系的一种度量。纹理特征提取的一种有效方法是以灰度级的空间相关矩阵即共生矩阵为基础的,其他方法还有基于图像友度差值直方图的特征提取和基于图像灰度共生矩阵的特征提取。
( 3 )形状特征。形状是刻画物体的基本特征之一,用形状特征区别物体非常直观,利用形状特征检索图像可以提高检索的准确性和效率,形状特征分析在模式识别和视觉检测中具有重要的作用。通常情况下,形状特征有两类表示方法,一类是形状轮廓特征描述,另一类是形状区域特征。形状轮廓特征主要有:直线段描述、样条拟合曲线、博立叶描述子、内角直方图以及高斯参数曲线等等,形状区域特征主要有:形状的无关矩、区域的面积、形状的纵横比等。
( 4 )空间特征。空间特征是指图像中分割出来的多个目标之间的相互的空间位置或者相对方向关系,有相对位置信息,比如上下左右,也有绝对位置信息,常用的提取空间特征的方法的基本思想为对图像进行分割后,提取出特征后,对这些特征建立索引。
目标比较盛行的有: Haar 特征、 LBP 特征、 HOG 特征和 Shif 特征等;他们各有千秋,得视你要检测的目标情况而定。
特征选择
再好的机器学习算法,没有良好的特征都是不行的 ; 然而有了特征之后,机器学习算法便开始发挥自己的优势。在提取了所要的特征之后,接下来的一个可选步骤是特征选择。特别是在特征种类很多或者物体类别很多,需要找到各自的最适应特征的场合。严格地来说,任何能够在被选出特征集上工作正常的模型都能在原特征集上工作正常,反过来进行了特征选择则可能会丢掉一些有用的特征;不过由于计算上的巨大开销,在把特征放进模型里训练之前进行特征选择仍然是相当重要的。
建模
一般物体识别系统赖以成功的关键基础在于,属于同一类的物体总是有一些地方是相同的。而给定特征集合,提取相同点,分辨不同点就成了模型要解决的问题。因此可以说模型是整个识别系统的成败之所在。对于物体识别这个特定课题,模型主要建模的对象是特征与特征之间的空间结构关系;主要的选择准则,一是模型的假设是否适用于当前问题;二是模型所需的计算复杂度是否能够承受,或者是否有尽可能高效精确或者近似的算法。
模型表示涉及到物体具有那些重要属性或特征以及这些特征如何在模型库中表示,有些物体模型定义为一系列局部的统计特征,即 generative 模型,有些是采用物体的特征以及物体特征之间的相互关系定义的,比如位置关系等,即 discriminative 模型,或者是二者的混合模型。对于大多数物体来说,几何特征描述是可以很有效的;但对于另外一些物体,可能需要更一般的特征或函数来表示。物体的表示应该包含所有相关信息,但没用任何冗余信息,并且将这些信息以某种方式组织起来,使得物体识别系统的不同组元能够容易访问这些信息。
用训练样本来训练分类器
这得先明白分类器是什么?百度百科的解释是: “ 使待分对象被划归某一类而使用的分类装置或数学模型。 ” 可以这样理解,举个例子:人脑本身也算一个分类器,只是它强大到超乎想象而已,人对事物的识别本身也是一个分类的过程。人在成长或者学习过程中,会通过观察 A 类事物的多个具体事例来得到对 A 类事物性质和特点的认识,然后以后遇到一个新的物体时,人脑会根据这个事物的特征是否符合 A 类事物性质和特点,而将其分类为 A 类或者非 A 类。(这里只是用简单的二分类问题来说明)。那么训练分类器可以理解为分类器(大脑)通过对正样本和负样本的观察(学习),使其具有对该目标的检测能力(未来遇到该目标能认出来)。
分类器按特征类型分为数值型分类器和符号型两大类。数值型分类器包括统计分类器(统计理论为基础)、模糊分类器(模糊集理论为基础)、人工神经元网络(模拟生物神经系统的电子系统,也可以用软件在计算机上实现)、人工智能分类器(基于逻辑推理或专家系统结构)。符号型分类器包括句法分类器(基于句法分析和自动机理论)、人工智能分类器(基于逻辑推理或专家系统结构)。其中符号型分类器具有更大的灵活性,所以能处理较为复杂的模式分类问题。但是目前对符号型分类器的研究远没有数值型分类器成熟。为了使分类检测准确率较好,训练样本一般都是成千上万的,然后每个样本又提取出了很多个特征,这样就产生了很多的的训练数据,所以训练的过程一般都很耗时的。
目标比较盛行的分类器有: SVM 支持向量机、 AdaBoost 算法等。 其中:
-
检测行人的一般是 HOG 特征 +SVM ;
-
OpenCV 中检测人脸的一般是 Haar+AdaBoost ;
-
OpenCV 中检测拳头一般是 LBP+ AdaBoost 。
随着深度学习的兴起,现在深度学习在物体识别上取得了相当好的成果。
匹配
在得到训练结果之后(在描述、生成或者区分模型中常表现为一簇参数的取值,在其它模型中表现为一组特征的获得与存储),接下来的任务是运用目前的模型去识别新的图像属于哪一类物体,并且有可能的话,给出边界,将物体与图像的其它部分分割开。一般当模型取定后,匹配算法也就自然而然地出现。在描述模型中,通常是对每类物体建模,然后使用极大似然或是贝叶斯推理得到类别信息;生成模型大致与此相同,只是通常要先估出隐变量的值,或者将隐变量积分,这一步往往导致极大的计算负荷;区分模型则更为简单,将特征取值代入分类器即得结果。
一般匹配过程是这样的:用一个扫描子窗口在待检测的图像中不断的移位滑动,子窗口每到一个位置,就会计算出该区域的特征,然后用我们训练好的分类器对该特征进行筛选,判定该区域是否为目标。然后因为目标在图像的大小可能和你训练分类器时使用的样本图片大小不一样,所以就需要对这个扫描的子窗口变大或者变小(或者将图像变小),再在图像中滑动,再匹配一遍。
目标识别方法
物体识别方法就是使用各种匹配算法,根据从图像已提取出的特征,寻找出与物体模型库中最佳的匹配,它的输入为图像与要识别物体的模型库,输出为物体的名称、姿态、位置等等。大多数情况下,为了能够识别出图像中的一个物体,物体识别方法一般由 5 个步骤组成:特征提取;知觉组织;索引;匹配;验证。
经典的物体识别方法:
1 ) Bag of words ( BoW )方法 。 BoW 方法主要是采用分类方法来识别物体, BoW 方法是来自于自然语言处理,在自然语言处理中是用来表示一篇文档是有一袋子词语组成的,在计算机视觉的物体识别方法中,将图像比作文档,将从图像中提取的特征比作词语,即一幅图像是有一袋子特征组成的,如图 1 所示。 BoW 方法首先需要一个特征库,特征库中的特征之间是相互独立的,然后图像可以表示为特征库中所有特征的一个直方图,最后采用一些生成性( generative )方法的学习与识别来识别物体。
2 ) Partsand structure 方法 。 BoW 方法的一个主要缺点为特征之间是相互独立的,丢失了位置信息, Parts and structure 方法采用了特征之间的关系,比如位置信息和底层的图像特征,将提取出的特征联系起来。 Pictorial Structure ( PS )提出的弹簧模型,物体部件之间的关系用伸缩的弹簧表示,对于特征之间的关系的模型表示,还有星型结构、层次结构、树状结构等。
3 ) 生成性( generative )方法与鉴别性( Discriminative )方法 。生成性方法检查在给定物体类别的条件下,图像中出现物体的可能性,并以此判定作为检测结果的得分,鉴别性方法检查图像中包含某个类别出现的可能性与其他类的可能性之比,从而将物体归为某一类。
分割
一旦在图像中潜在目标的位置找到了,就要从背景中尽可能准确的将目标提取出来,即将目标从背景中分割出来。当存在噪声和杂波干扰时,信噪比可能很低,这是将会给分割造成困难。
目标的分割算法有很多。每个分割算法都要解决两个问题:分割准则和执行方法。
( 1 ) MeanShift 聚类
Meanshift 聚类也可以用在边缘检测、图像规则化、跟踪等方面。基于 meanshift 的分割需要精密的参数调整以得到较好的分割效果,如颜色和空间核带宽的选择,区域尺寸最小值的阈值设定。
( 2 ) Graph-cut
图像分割可以建模为 graph-cut 问题。图 G 的顶点 V 由图像像素点构成;通过剪除加权的边分割为 N 个不相连的子图。两个子图间被剪除的边的权和称为 cut 。权值由颜色、光照、纹理等因素计算得到。通常应用在跟踪目标轮廓上;与 MeanShift 相比,它所需要参数较少,但计算开销和内存开销较大。
( 3 )主动轮廓
主动轮廓曲线将一个闭合轮廓曲线推演为目标边界,从而实现图像分割。这个过程由轮廓的能量函数来操纵。这个问题需要解决三个方面问题:一是能量函数的确定,二是轮廓曲线的初始化,三是轮廓表达方式的选择。
存在问题
虽然目标识别已经被广泛研究了很多年,研究出大量的技术和算法,识别方法的健壮性、正确性、效率以及范围得到了很大的提升,但在目标检测和识别这方面仍然存在着许多不足,体现在一下几个方面。
( 1 )目标之间互遮挡和人体自遮挡问题,尤其是在拥挤状态下,多人的检测更是难处理。
( 2 )获取物体的观测数据时会受到多方面的影响。在不同的视角对同一物体也会得到不同的图像,物体所处的场景的背景以及物体会被遮挡,背景杂物一直是影响物体识别性能的重要因素,场景中的诸多因素,如光源、表面颜色、摄像机等也会影响到图像的像素灰度,要确定各种因素对像素灰度的作用大小是很困难的,这些使得图像本身在很多时候并不能提供足够的信息来恢复景物。
( 3 )同样的图像在不同的知识导引下,会产生不同的识别结果,知识库的建立不仅要使用物体的自身知识,如颜色、纹理、形状等,也需要物体间关系的知识,知识库的有效性与准备性直接影响了物体识别的准确性。
( 4 )物体本身是一个高维信息的载体,但是图像中的物体只是物体的一个二维呈现,并且在人类目前对自己如何识别物体尚未了解清楚,也就无法给物体识别的研究提供直接的指导。
( 5 )目前人们所建立的各种视觉系统绝大多数是只适用于某一特定环境或应用场合的专用系统,而要建立一个可与人的视觉系统相比的通用视觉系统是非常困难的,虽然存在着很多困难。
( 6 )目标之间互遮挡,尤其是在拥挤状态下,目标检测很不稳定,检测结果也很不理想,这个问题还需要进一步的研究解决。
未来研究思路
目标检测和识别仍然存在着诸多的问题,以后目标识别可以从以下几个方面改进:
( 1 )形状特征的研究。目前大部分的形状特征仍然是基于有向梯度,这是否是足够的,形状是否应该有更高一层的抽象表示,还值得进一步的研究。
( 2 )物体的表示与描述。如何描述物体,物体不应该是独立的,物体与物体之间的交互应该考虑进来。物体不应该是一组独立的特征的集合,物体识别应该放在一个更大的上下文环境中来重新考察。
*注:参考http://blog.csdn.net/liuheng0111/article/details/52348874
本次分享的主要分类方案: (中国科学院计算技术研究所多媒体计算研究组——唐胜 副研究员)
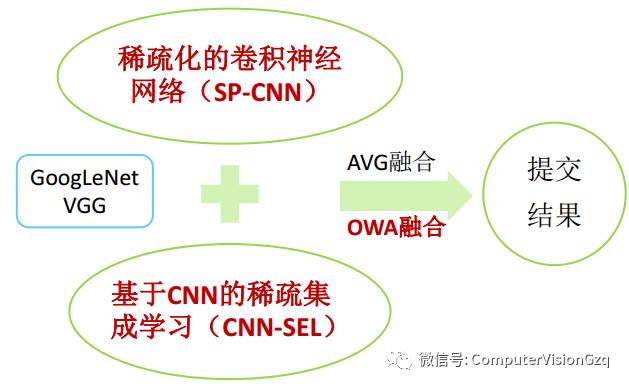
稀疏化的卷积神经网络(SP-CNN)
-
神经科学研究表明[1] :神经元之间
– 稀疏激活(Sparse Activity)
– 稀疏连接(Sparse Connectivity)
-
一个类别可以用类别基元稀疏表达
-
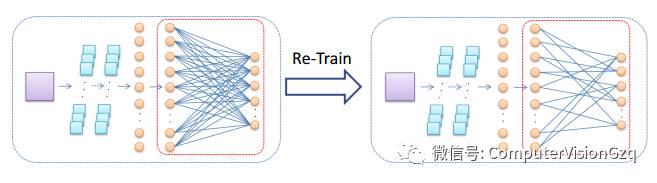
在全连接层中自适应地断开不重要的连接,仅保留重要连接
– 去除不重要的连接引入的干扰噪声
– 精简模型,更适合于移动终端和嵌入式设备
注:[1] Thom M, Palm G. Sparse activity and sparse connectivity in supervised learning[J].
The Journal of Machine Learning Research, 2013, 14(1): 1091-1143.
SP-CNN:验证集结果
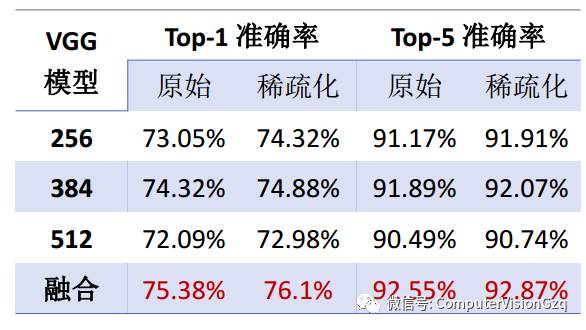
在最后一个全连接层参数数量仅为原模型 9.12% 的情况下:Top-1和Top-5准确率分别提高了 0.72% 、 0.32% 。
CNN-SEL:Motivation
语义多态性
-
类内差异大,需要大量样本,以尽可能囊括可能的样本情况
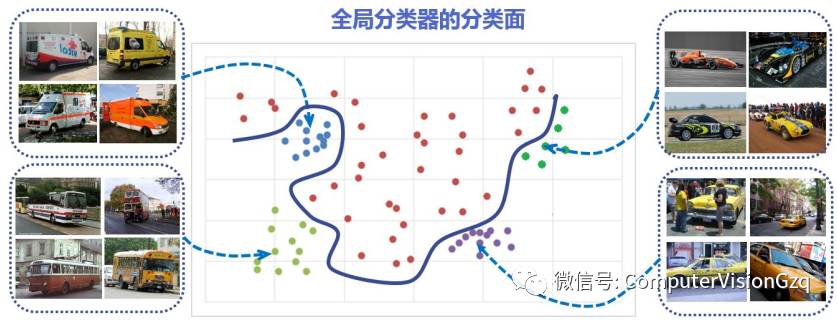
全局分类方法
-
训练复杂度高, 训练RBF核SVM复杂度O(n2)-O(n3)
-
分类面复杂,模型大,识别效率低
CNN-SEL:系统框架
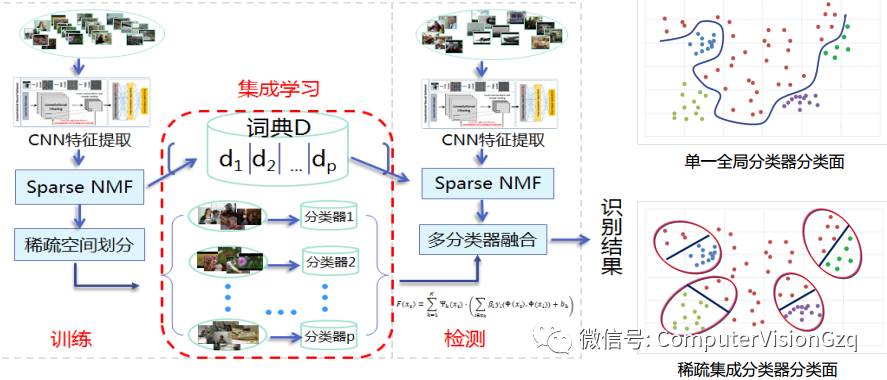
基于CNN特征的稀疏集成学习[2]
-
稀疏划分:训练时用稀疏编码划分子空间,大幅提高训练效率
-
稀疏融合:测试时用稀疏编码进行多分类器融合,提高测试效率
-
子分类面简单、激发的子分类器个数少、 互为补充、提高分类精度
[2] Sheng Tang, Yan-Tao Zheng, Yu Wang, Tat-Seng Chua, “Sparse Ensemble Learning for Concept
13 Detection”, IEEE Transactions on Multimedia, 14 (1): 43-54, February 2012
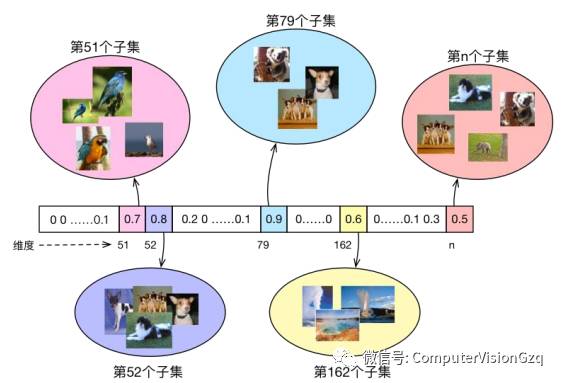
CNN-SEL:稀疏划分
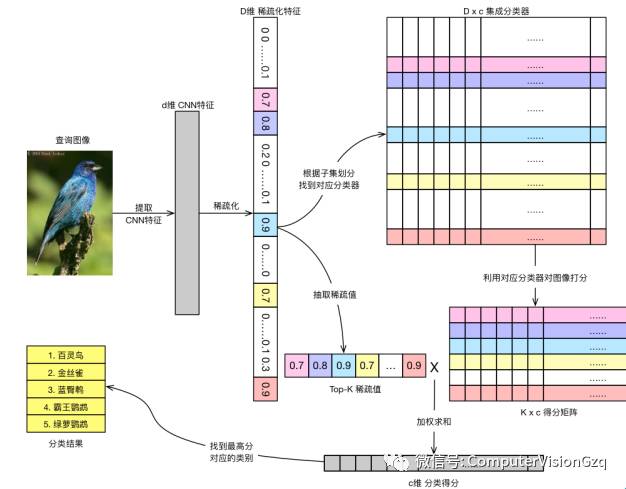
CNN-SEL:稀疏融合
CNN-SEL:验证集实验
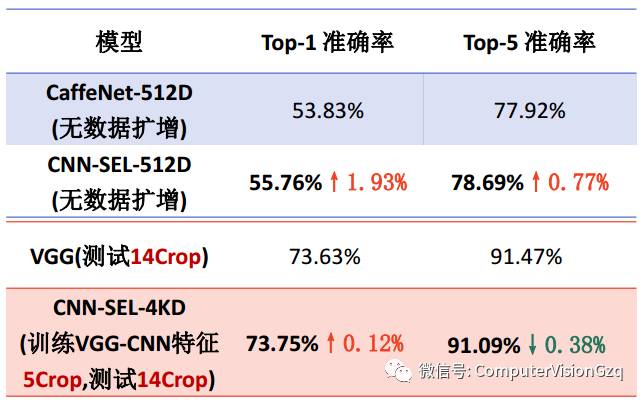
在CaffeNet能明显提高准确率,在VGG上因为训练SVM子分类器只用了5个不同位置的Crop,没有考虑更为复杂的数据扩增方法,如多尺度、镜像翻转、对比度和颜色变化等,因而提高不明显。
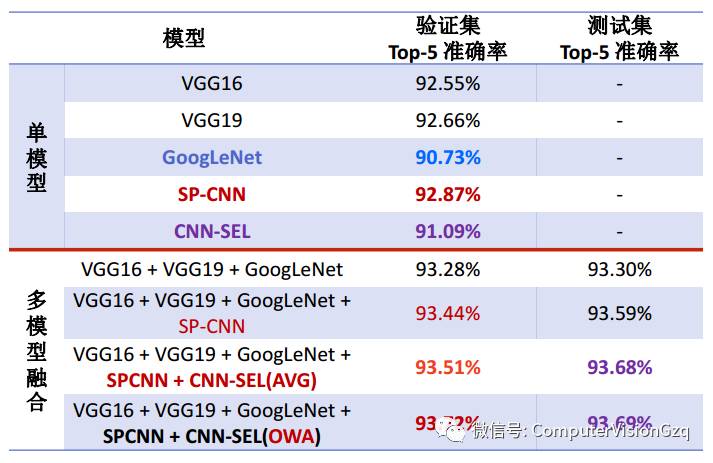
模型融合结果
目标定位方案
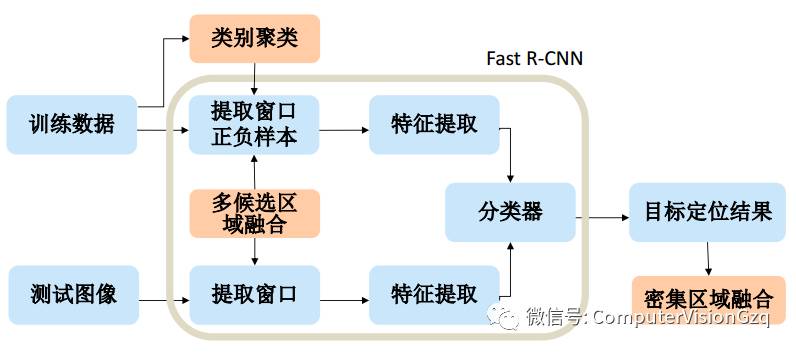
候选区域 :多种候选区域(Region Proposals)融合
密集区域融合 :利用最终结果的密集区域对目标位置进行回归
类别聚类 :提出了使用CNN特征类别聚类的目标定位方法
目标定位: 多候选区域融合

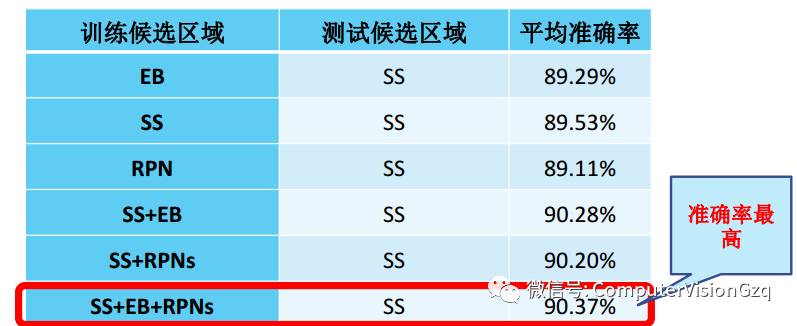
多候选区域融合验证集实验
-
为快速验证,从1000个类别随机选取50个类别
-
为避免分类影响,假设分类准确度为100%,即取验证集上的真实类别标签(Ground truth)
-
多候选区域融合有效提高了目标定位任务的准确率
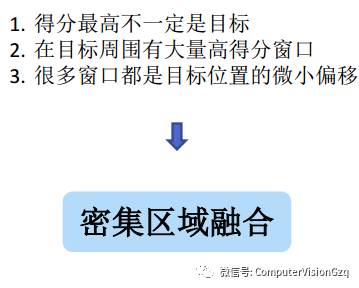
密集区域融合:Motivation

白框为标注窗口;红框为密集融合窗口;绿色框得分大于等于0.6;黄色框得分低于0.6大于0.3
LOC: 密集区域融合
-
密集区域指在同一个目标附近大量类似的候选区域,可以看作同一目标位置的偏移。
-
密集区域的判别函数通过计算两个窗口的中心点距离和窗口之间的IoU来确定。




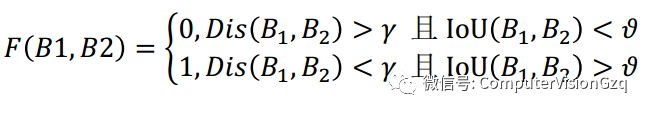
• 密集区域融合(DRF)
Dense Region Fusion
• 区域融合:将两个区域的坐标取平均值。
• 得分融合:高得分窗口分数加上低得分窗口分数的一半。

LOC: 密集区域融合实验结果
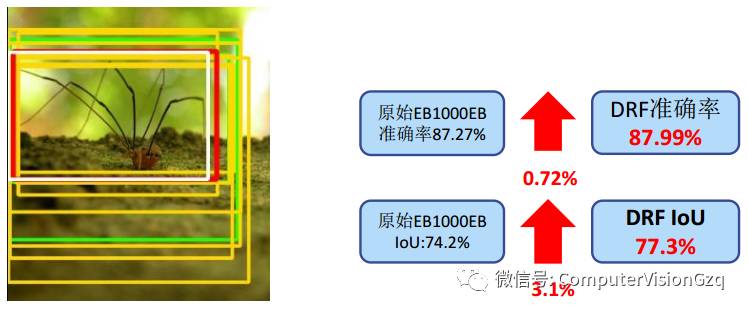
1.准确率提高,排除了高得分非目标窗口
2.重叠率提高,目标位置的偏移得到回归
LOC: 基于CNN聚类的目标定位
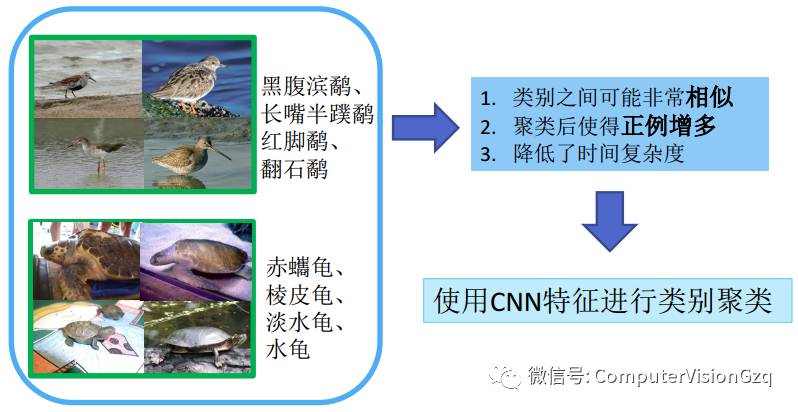
将聚类后的类别作为一个大类训练Fast R-CNN模型得到定位结果
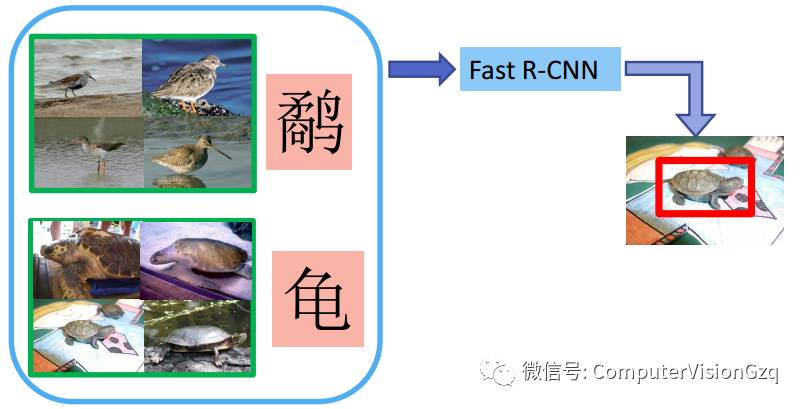
目标定位系统框架-训练
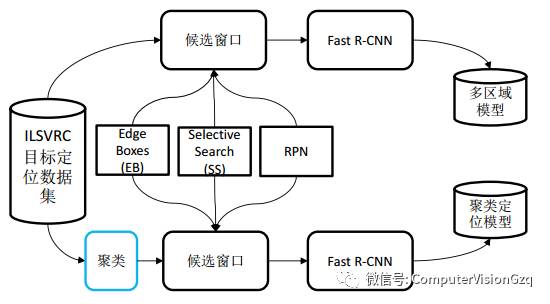
训练:
1. 多区域模型:基于多候选区域融合的定位方法
2. 聚类定位模型:基于CNN特征特征类别聚类的定位方法
目标定位系统框架-测试
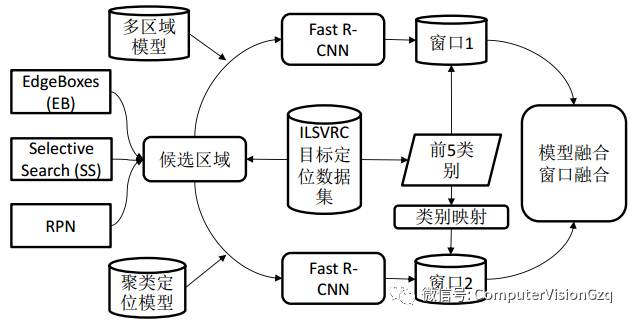
测试:
1. 模型融合:两个模型在不同类别上准确率不同,根据验证集上图片类别的结果,选用准确度高的模型
2. 窗口融合:使用密集区域融合对定位位置进行回归
来自:http://mp.weixin.qq.com/s/0E4VpN9z2sNvsGCvOI5RVA
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/5854/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料