

谈到设计Twitter, 我们首先要问一个本质问题: 设计Twitter的基本方法论是什么?
其实是我们计算机设计最基本的方法: 分治法(Divide and Conquer)。
什么是分治法呢?就是把问题不断的拆解,拆解到你可以解决为止,它的艺术在于,从哪个维度来拆解非常考验我们能力。


如果要求一周开发出Twitter,你会怎么做?
你的架构是什么样的呢?
相信你一定不会给出复杂的架构。前端是各种各样的业务逻辑,后端是MySQL数据库,这样就够了。因为这已经解决了当时的问题,满足了一周开发出来的要求。
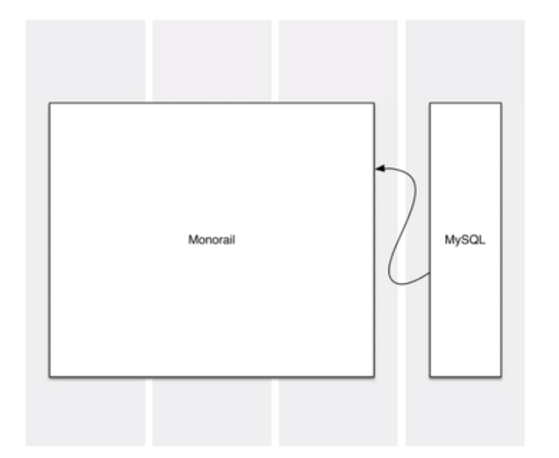

但随着Twitter的成长,我们会遇到各种各样新的挑战:
-
MySQL难扩展。
为什么难扩展?因为它把同样的一个数据分成各种关系存在里面,每次取的时候,都要通过Join来进行复杂的操作,这个Join当数据被切分的时候存在更多的服务器上,会变得越来越复杂,所以很难扩展。
-
小变化也要全部部署。
任何变化都需要部署到所有机器上,因为服务不断升级,就变成了每天不断部署,变成了daily deployment。所以每次部署的时候耽误时间很长。
-
性能差。
因为所有服务都要部署在一起,造成了它的内存占用率大,而且部分核心模块还因为最初当时的单线程设计成为了各种瓶颈。
-
架构混乱。
因为所有模块在一起很混乱。

那要怎么破解这些问题?
答案是将问题拆解开来。

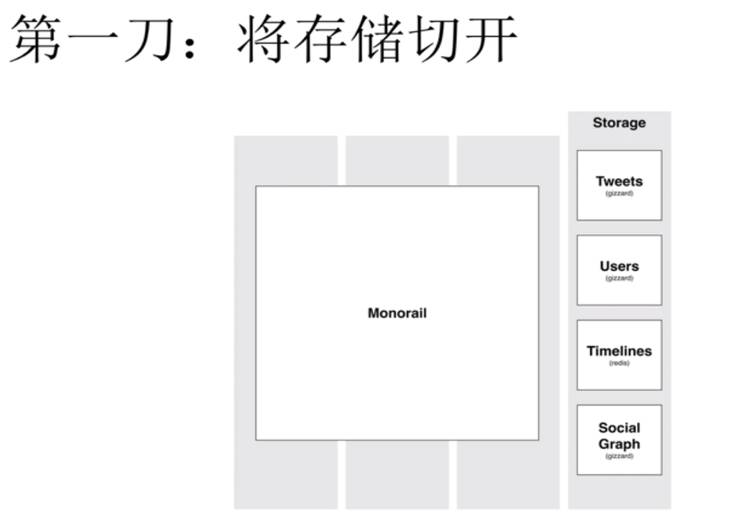
第一刀将存储切开。
我们看后台,可以拆成存Tweets,存User,存Timeline,存Social Graph不同内容,Timeline可以拿Redis这样的数据库来保存,而对于其它的数据比如Gizzard其实是一个分布式的MySQL数据库。并不是所有数据都不适合用MySQL分布,我们可以把这些适合的用MySQL来shutting一下,而不适合的用别的数据库来存,就是一个存储切开的方法。
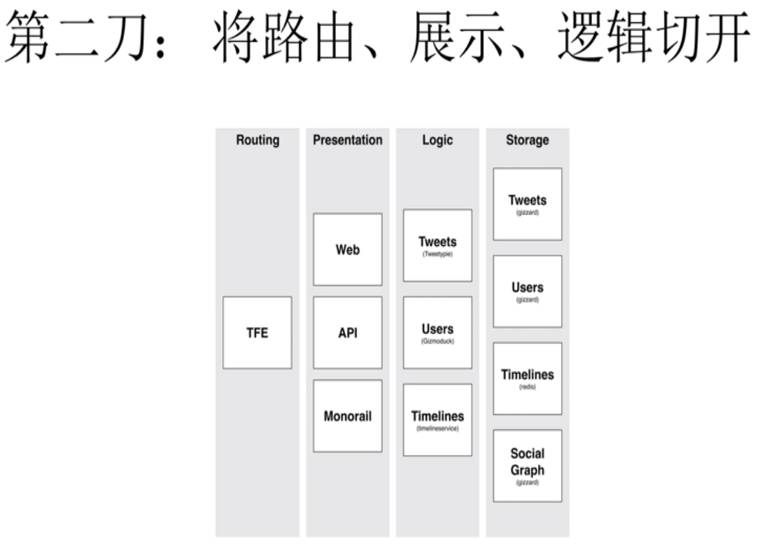
第二刀是将路由、展示、逻辑切开。
我们可以看到又多出了一层,逻辑层。Tweets,User,Timeline它们分别对应后边的各种数据存储。前端会有外部访问的接口,API访问接口,并且它还保存了以前数据的整个架构,用来进行一些小规模的使用。最前面需要有一个Routing,来将不同的请求分布到不同的API上。所以之后Twitter就变成了上百上千个小小的数据模块,包括它的服务模块,他们通过之间的相互调用来完成具体的请求。

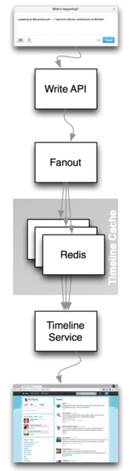
如果Lady Gaga发了个推文,会发生什么呢?
首先她发出一个推文,会到达最上面一层的外部模块,负责把推文写出来;接着到了API模块,负责接收这个推文;再往后是Fanout,Fanout将推文的ID推荐给所有订阅这个用户的信息收件箱里,收件箱就是Timeline,比如有400万人订阅了Lady Gaga,就会有400万的收件箱收到这个消息;紧接着由于我们Timeline要发到收件箱里,收件箱必然是一个最复杂的操作,为了优化它的性能,就把它们用分布式的方式存储在Redis里面,Redis是偏向内存的数据库,所以能够很快的存储这些信息;但Redis里存的只是ID,所以当一个用户具体要她推文的时候,实际上要通过Timeline服务去找到这个用户对应的是哪个Redis服务器上存了推文的 Timeline list,接着找到所有ID,然后这个Timeline service把ID的具体内容通过另外的数据库装载进来,最终得到结果反馈给用户。这些保证了我们推整个数据的时候速度最快,能够达到每秒30万次的性能。

虽然有了这样的过程,如何支持搜索呢?
很简单的想法是当我们写入API,它Fanout到每个用户的Timeline list的时候,我们可以拿另外的Ingester把这个推文放到里面,Ingesert最后把它放到Earlybird,就是所谓的倒排索引中。比如有个推文发过来“我喜欢太阳”,就把我,喜欢,太阳,拆成三个词,把这些单词,进行倒排索引,存到Search index里面。这时候实际会用到很多很多Earlybird,这样就能建立很多倒排索引,能够并行的去做。当用户一个请求过来之后,比如搜索“早上吃饭”,就会把morning和eat作为两个关键词发到我的Earlybird集群里,得到结果后Blender会把它组合到一块,并反馈结果。当然很多用户可以并行的向Blender发送请求,从而得到最终结果,这就是我们的搜索服务。
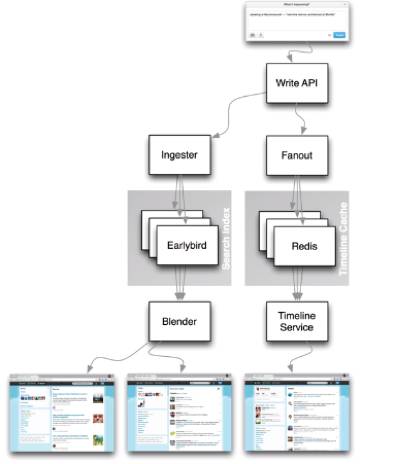

如何通知用户新消息到达呢?
第一个方法是另外再开一个Write API,在有新东西发生以后,我把它放到一个Push的服务里,那所有用户只要都连到这个后台里,HTTP PUSH,就会通知他有新消息产生了。同理对Mobile ,会有Mobile Push,当然大家对不同的信息有不同的对接方法,大家可以去仔细考虑下怎么能做到这个样子。
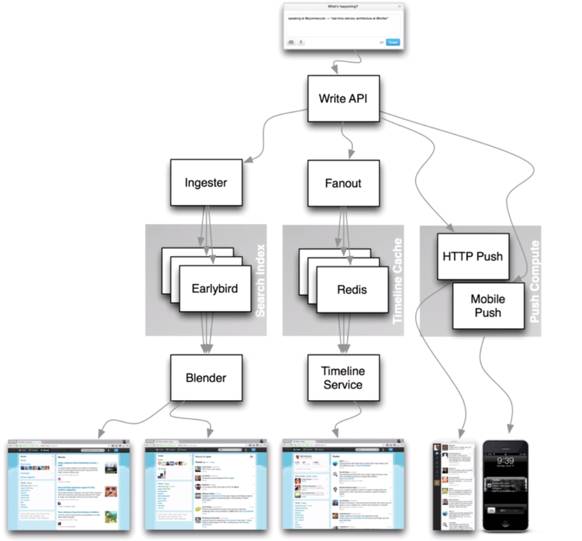

如何搭建这样的服务呢?
最基本的是开源项目Twitter-Server。
-
配置服务,IP之类;
-
管理服务,哪些down了、控制、启动等;
-
日志服务,运行怎么样,以后出问题找谁等;
-
生命周期服务,什么时候启,什么时候关,什么时候控制;
-
监控服务,到底有没有出错,出错以后怎么办,互相报警等
这些东西合到一起,就构成了这样服务的基本架构。

各个服务之间如何交流?
这就是传统的RPC(远程的进程调用),大家能够通讯的不仅是数据,而且可以通讯命令或请求之类的。这时需要开源项目Finagle。
-
能够提供服务发现,因为有很多服务,所以要找谁发送这个请求呢;
-
负载均衡,可能有十个人提供服务,先放到谁那儿?
-
重试,如果失败了怎么办,是否需要重试?
-
基本的线程池和链接池,大家可以复用,不用每次去创建,浪费资源了;
-
统计信息的收集;
-
分布式调试。

如何调用一个服务?
因为从A调用B,大家之间各种远程,写代码上要怎么做呢?可以使用函数来调用(Service as a Function),背后实际上是Function programming的思想。
可以看下这个基本例子:trait Service[Req,Rep]extends(Req=>Future[Rep])
简单理解为:我有一个请求想得到一个Response,就是Request到Response。这里面实际上可以先面向未来实现,之后当它执行的时候,就会得到相对应的结果。

多个服务的调用如何整合在一起?
我们看一看它要如何运行?比如我们有一个请求是得到一个用户的所有Timeline数据。它其实有很多步,第一步是得到User ID;第二步得到User timeline list里的那些消息ID;下一步是针对每一个消息,得到它的每一个具体内容,比如“我早上吃饭”这些内容,这些内容里面可能还有图片,还需要得到图片的数据。这是一个很复杂的过程,但这个箭头表达了它们最基本的执行顺序。
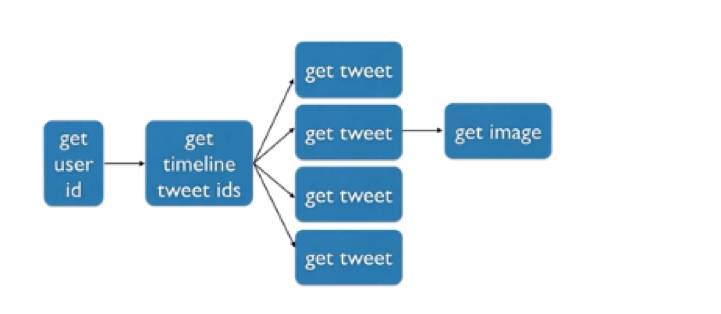

最佳的执行路径是什么?
首先是得到ID,再得到Timeline以后可以并行地读取每个tweet,可能会有的快有的慢,然后又得到一些它的具体信息,比如说图片之类,所以这就是最优策略。

下面我们来看一看代码:
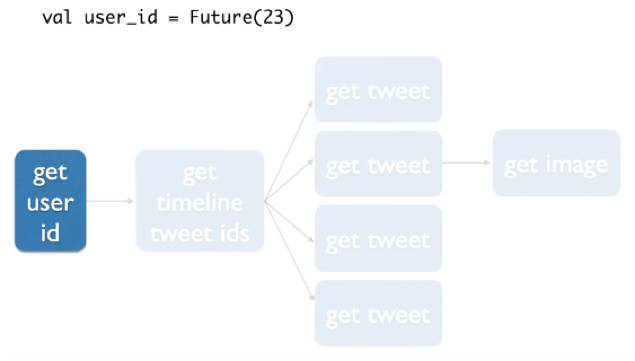
第一行是得到用户ID,用一个面向未来的方程得到一个用户ID。
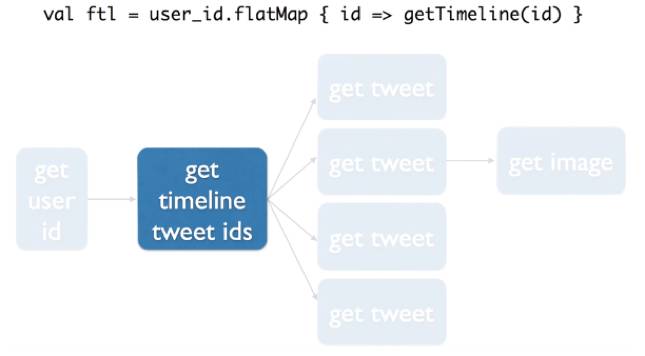
第二行根据ID拿FlatMap,FlatMap其实是后面针对每一个ID执行的函数,这个函数来得到这个ID用户的Timeline list。所以这也是我们Function programming,或者如果用Spark也会经常碰见的函数。
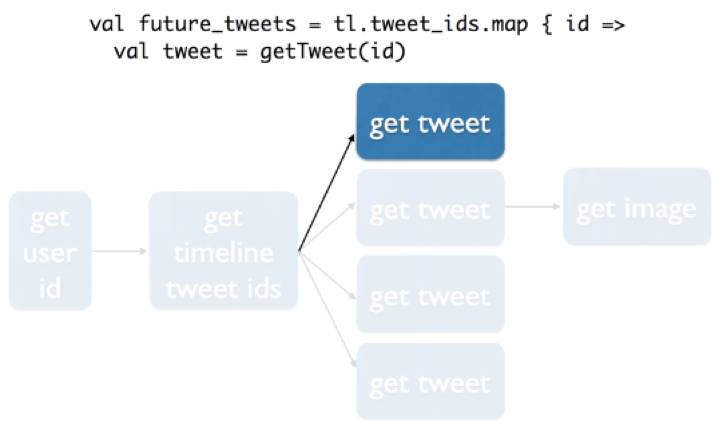
得到每一个ID以后,实际上要针对每个ID执行,所以需要Map。Map每一个ID是做什么的,得到这个Tweet的具体信息。代码第二行就是根据ID得到他的具体内容。
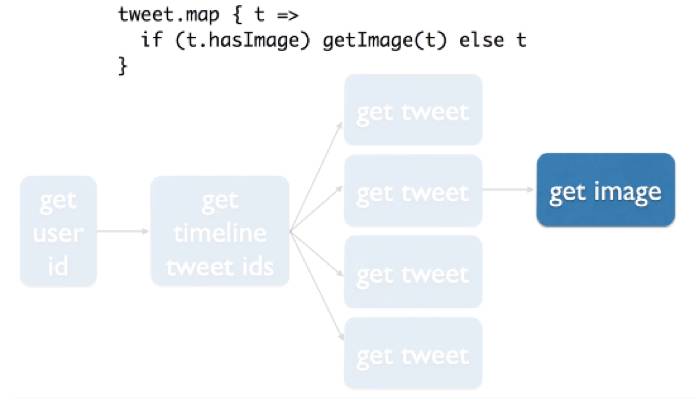
当然如果这个东西有图片,那需要得到图片。
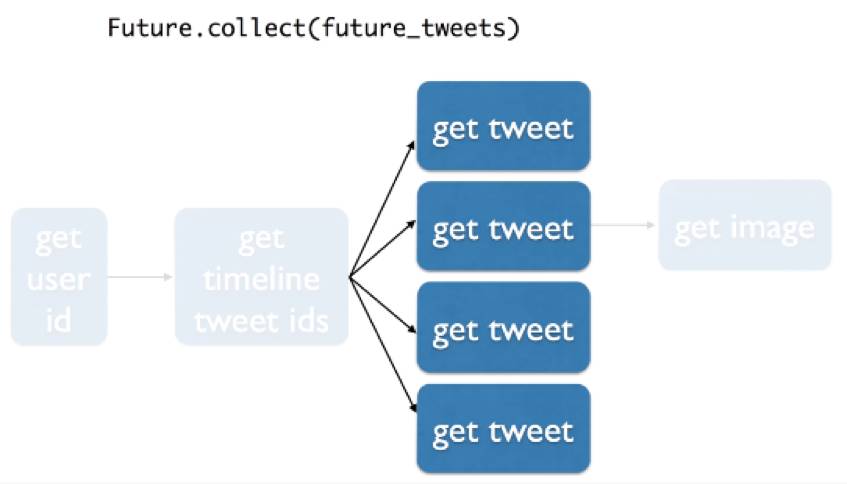
中间一步还需要把这些东西并行起来,大家都去单独得到Tweet,并且把它集合放到一块儿去。整个过程我们就得到了最终的代码。

这其实就是 第三刀:切开“做什么”和“怎么做”。 在这个代码过程中,所谓面向函数的编程,只是写了想做什么事儿,但具体怎么做,比如从哪个机器找、连接服务器、从谁那儿抓取,怎么并行等都没有写,实际上这些东西都被封装到了一个底层的库里面。所以现在Twitter就可以有两个团队,一个团队负责写代码,“做什么”;另一个团队负责写底层是怎么实现的。这样就能实现并行开发,这也是Function programming的一个好处。

一个服务器的架构长什么样呢?
上方是你的服务,下方就是你的服务器,包括一些集群的管理、内存、Java的虚拟机、操作系统和硬件。
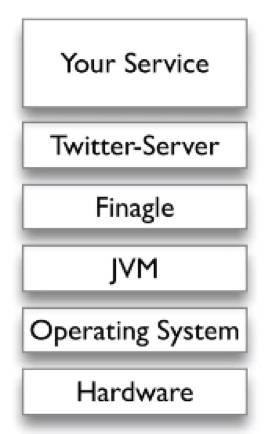

有很多服务如何整合?
结果整合到一起就是很多层,底层都是一样的,但上层跑了不同的服务:HTTP、聚集器、时间timeline服务等。我们所有东西加在一起,系统就会跑上千个不同的小服务器,而且之间会有各种各样的备份。
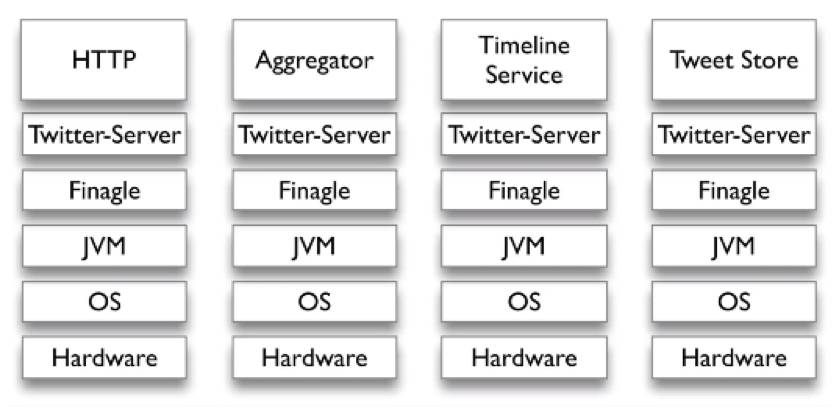

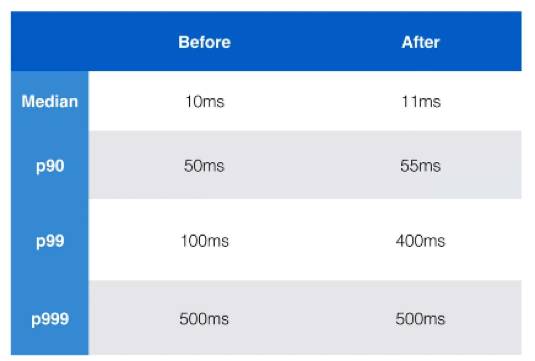
那如何来统计出现的服务器情况呢?
比如会统计平均延迟,或统计一些信息来验证服务器是不是出问题了,实际上,在这种大规模里面,一个比较好的方法就是不要拿平均值统计,因为特殊情况会拉低所有情况。举个例子,假设北京有一个人,他年收入是100万,另外99个人每个人年收入都是1元。那平均下来每个人收入都是1万块钱,但实际上大多数人是很穷困的。所以不能拿平均数来算,尤其是在服务器的情况下。所以大家一般都会取中位数(median),百分之90的点,百分之99的点和百分之999的点。我们可以看到,下图是一个服务发生故障的前后。在服务故障发生前,百分之99点的平均延迟是100毫秒,但故障发生后变成400毫秒,发现这个问题以后就会去抓。但如果用平均值,很可能就发现不了这个问题。
这样还有一个好处,当我们做到上面整合的架构以后,每一个负责写代码的团队,只负责处理跟它相关的上下层就行,而不用做那么多交互,所以每个人的东西都非常简单,这也是所谓微服务的一个好处。

如何监控一个服务呢?
实际上针对这个服务在整个栈里面用的时间,会有一个图表达出来。

如何监控一个请求呢?
实际上,基于一个请求,会有一个整个运行的最佳策略,这就需要运行的整个过程的图。这就是我们之前讲的,得到一个用户所有Timeline内容信息的锯齿图,Zipkin,这也是一个开源项目。
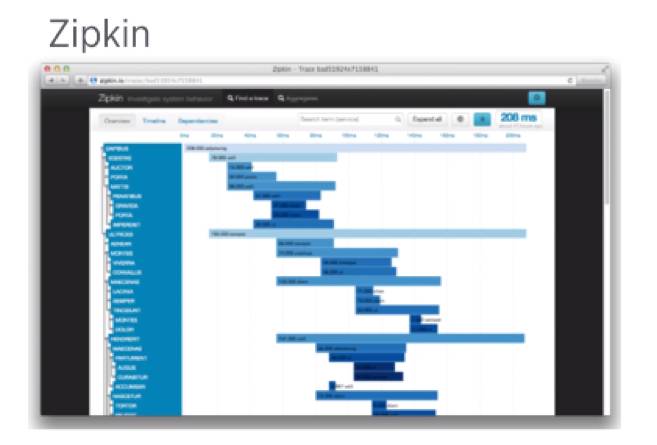

如何监控系统的运行情况呢?
因为这个时候失败已经成为常事了。举个例子,假设每秒有30万的请求,有99.99%的成功率,那每秒一定会有30个失败的,所以不能说每次失败怎么样,统计失败率会比单独的失败更重要,而且写代码的时候要为这个失败来进行自动重试。大家不用纠结每次的失败,只要大部分过去就行了。

最后做下总结
-
学好分治法,走遍天下都不怕。
-
函数式设计切分做什么和怎么做。做什么是由函数式设计来写,而怎么做由底层的语言和编译器来优化。
-
面向错误让我们使用了统计域监控。99.9%的点出什么问题了,这样就叫做基于统计域的监控方式。
参考资料:《Real-Time Systems at Twitter》
来自:http://mp.weixin.qq.com/s/c9mFDmHRLbuKbqS6aGUdiQ
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/5856/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料