

在本系列的第一篇文章中,我们研究了2阶段提交协议,以及Ignite如何处理各种类型的集群节点,下面是在剩下的文章中要覆盖的主题:
- 并发模型和隔离级别
- 故障转移和恢复
- Ignite持久化层中的事务处理(WAL、检查点及其他);
- 第三方持久化中的事务处理
在本文中,我们会聚焦并发模型和隔离级别。 大多数现代多用户应用允许并发数据访问和修改。为了管理此功能,并确保系统从一个一致状态切换到另一个一致状态,使用了事务的概念。事务依赖于锁,它可以在事务开始时(悲观锁)获得,也可以在事务结束提交之前(乐观锁)获得。 Ignite支持两种并发模型: 悲观 和 乐观 ,下面先讲悲观并发模型。
悲观并发模型
悲观并发模型的一个例子是两个银行账户之间的转账,需要确保两个银行账户的借贷状态正确记录。这时需要给两个账户加锁来确保更新全部完成并且余额正确。 在悲观并发模型中,应用需要在事务开始时锁定即将要读、写或者修改的所有数据。Ignite还支持一组悲观并发模型的 隔离级别 ,在读写数据时提供了灵活性:
- 读提交
- 可重复读
- 序列化
在读提交模型中,锁是在写操作对数据进行任何改变之前获得的,比如 put() 或者 putAll() ,而可重复读以及序列化模型用于读写操作都需要获得锁的场景。Ignite还有些内置的功能,使得调试和解决分布式死锁问题更容易。 下面的代码示例展示了可重复读的悲观事务,因为应用需要对一个特定银行账户进行读和写的操作:
try (Transaction tx = Ignition.ignite().transactions().txStart(PESSIMISTIC, REPEATABLE_READ)) {
Account acct = cache.get(acctId);
assert acct != null;
...
// Deposit into account.
acct.update(amount);
// Store updated account in cache.
cache.put(acctId, acct);
tx.commit();
}
本例中,通过**txStart() 和 tx.commit() 方法分别来进行事务的开启和提交。 txStart() 方法传递了PESSIMISTIC和REPEATABLE READ参数,在try块体中,代码在 acctId 键上执行了一个 cache.get() 操作,之后,一些资金存入账户并且缓存使用 cache.put()**进行了更新。 下面的代码示例展示了读提交并且带有死锁处理的悲观事务:
try (Transaction tx = ignite.transactions().txStart(TransactionConcurrency.PESSIMISTIC, TransactionIsolation.READ_COMMITTED, TX_TIMEOUT, 0)) {
// More code here.
tx.commit();
} catch (CacheException e) {
if (e.getCause() instanceof TransactionTimeoutException &&
e.getCause().getCause() instanceof TransactionDeadlockException)
System.out.println(e.getCause().getCause().getMessage());
}
本例中,代码展示了如何使用Ignite的 死锁检测机制 ,这简化了可能由应用代码导致的分布式死锁的调试。要开启这个特性,需要开启一个超时时间非0的Ignite事务(TX_TIMEOUT > 0),还需要捕获包含死锁详细信息的TransactionDeadlockException。 下面再看一下不同隔离级别的消息流,对于读提交,如图1所示,在这个隔离模型中,Ignite对于读操作不会获得锁,比如 get() 或者 getAll() ,这对很多场景可能更适合。
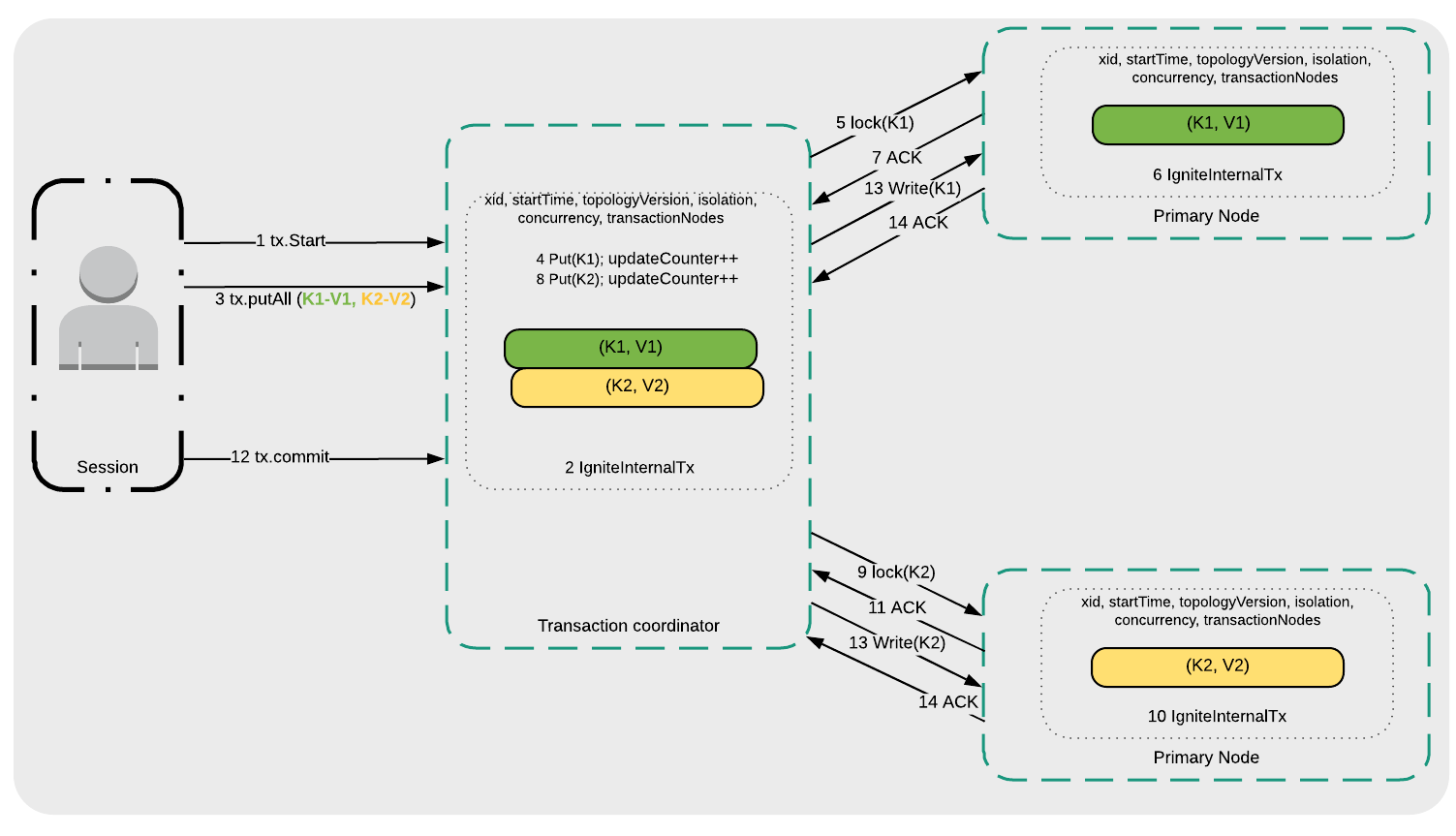
- 事务开始( 1 tx.Start );
- 事务协调器在内部管理事务请求( 2 IgniteInternalTx );
- 应用写入键K1和K2( 3 tx.putAll(K1-V1, K2-V2) );
- 事务协调器将K1写入本地事务映射( 4 Put(K1) );
- 事务协调器向存储K1的主节点发起一个锁请求( 5 lock(K1) );
- 主节点在内部管理事务请求( 6 IgniteInternalTx );
- 主节点向事务协调者发送一个已经准备好的确认( 7 ACK );
- 对于K2重复如图1的4-7步骤;
- 发起事务提交请求( 12 tx.commit );
- K1和K2写入相应的主节点( 13 Write(K1)和13 Write(K2) );
- 主节点确认事务提交( 14 ACK );
下一步,看一下可重复读和序列化的消息流,如图2所示:
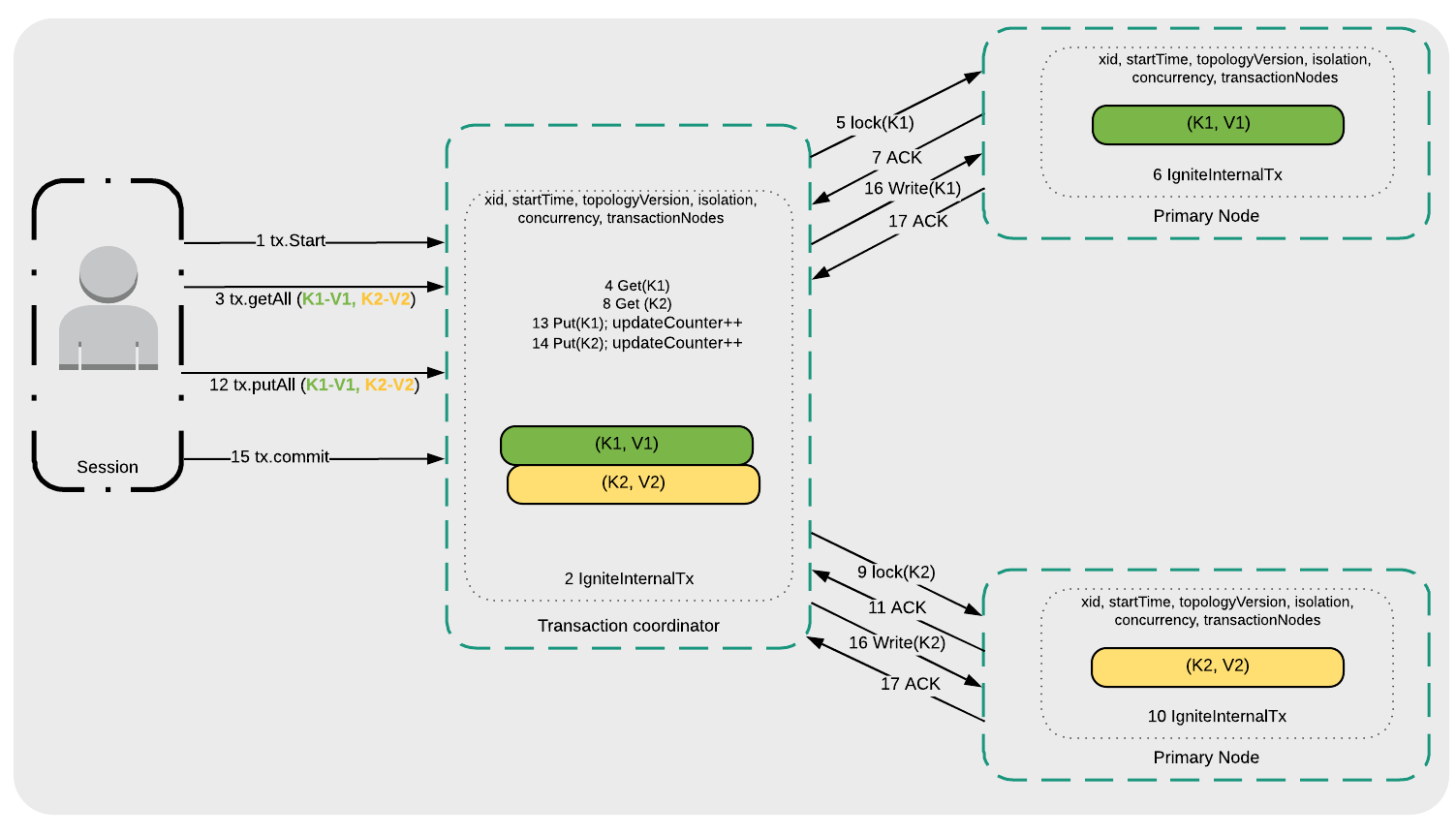
- 事务开始( 1 tx.Start );
- 事务协调器在内部管理事务请求( 2 IgniteInternalTx );
- 应用读取键K1和K2( 3 tx.getAll(K1-V1, K2-V2) );
- 事务协调器开始键K1的读请求处理( 4 Get(K1) );
- 事务协调器向存储K1的主节点发起一个锁请求( 5 lock(K1) );
- 主节点在内部管理事务请求( 6 IgniteInternalTx );
- 主节点向事务协调者发送一个已经准备好的确认( 7 ACK )并且返回K1的值;
- 对于K2重复如图2的4-7步骤;
- 应用写入K1和K2( 12 tx.putAll(K1-V2, K2-V2) );
- 事务协调器将K1的更新写入本地事务映射( 13 Put(K1) );
- 事务协调器将K2的更新写入本地事务映射( 14 Put(K2) );
- 发起事务提交请求( 15 tx.commit );
- K1和K2写入相应的主节点( 16 Write(K1)和16 Write(K2) );
- 主节点确认事务提交( 17 ACK );
总结一下,在悲观模型中,在事务完成之前锁一直持有,并且锁会阻止其他事务对数据的访问。 下一步看一下乐观并发模型。
乐观并发模型
乐观并发模型的一个例子是计算机辅助设计(CAD),这里一个设计师工作于整个设计的一部分,通常会将设计从中央仓库中检出到本地工作区,然后进行部分更新之后将成果检入中央仓库,因为设计师只负责整个设计的一部分,所以不可能与其他部分的更新产生冲突。 与悲观并发模型相反,乐观并发模型延迟了锁的获取,这样更适合于资源争用较少的应用,比如上面描述的CAD的例子。Ignite还支持一些乐观并发模型的 隔离级别 ,这提供了读写数据方面的灵活性:
- 读提交
- 可重复读
- 序列化( 无死锁 )
回顾一下前文中关于2阶段提交中各个阶段的讨论,当使用乐观并发模型时,在准备阶段,锁是在主节点获取的。在使用序列化模式时,如果通过事务请求的数据已经改变,在准备阶段事务会失败。这时,开发者需要编程控制应用的行为,即是否需要重启事务。而其他的两个模式,可重复读和读提交,不会检查数据是否改变。虽然这会带来性能方面的好处,但是没有了数据的原子性保证,因此,这两个模式在生产中很少用到。 下面的代码示例展示了序列化的乐观事务,因为应用需要对一个特定银行账户进行读和写的操作:
while (true) {
try (Transaction tx = ignite.transactions().txStart(TransactionConcurrency.OPTIMISTIC, TransactionIsolation.SERIALIZABLE)) {
Account acct = cache.get(acctId);
assert acct != null;
...
// Deposit into account.
acct.update(amount);
// Store updated account in cache.
cache.put(acctId, acct);
tx.commit();
// Transaction succeeded. Exiting the loop.
break;
} catch (TransactionOptimisticException e) {
// Transaction has failed. Retry.
}
}
本例中,在外侧有个while循环,判断事务是否失败,它可以重试。下一步,有**txStart() 和 tx.commit()**方法,分别用于事务的开始和提交。**txStart() 方法传递了OPTIMISTIC和SERIALIZABLE参数,在try块体中,代码先在acctId键上执行了 cache.get() 操作,之后,一些资金存入账户并且缓存使用 cache.put()**进行了更新。如果事务成功,代码会从循环中中断,如果事务不成功,会抛出异常然后事务重试。对于乐观的序列化事务,访问键的顺序不受限制,因为Ignite为了 避免死锁 ,事务锁是通过一个额外的检查并行地获得的。 下面看一下不同隔离级别下的消息流,先从序列化开始,如图3所示:
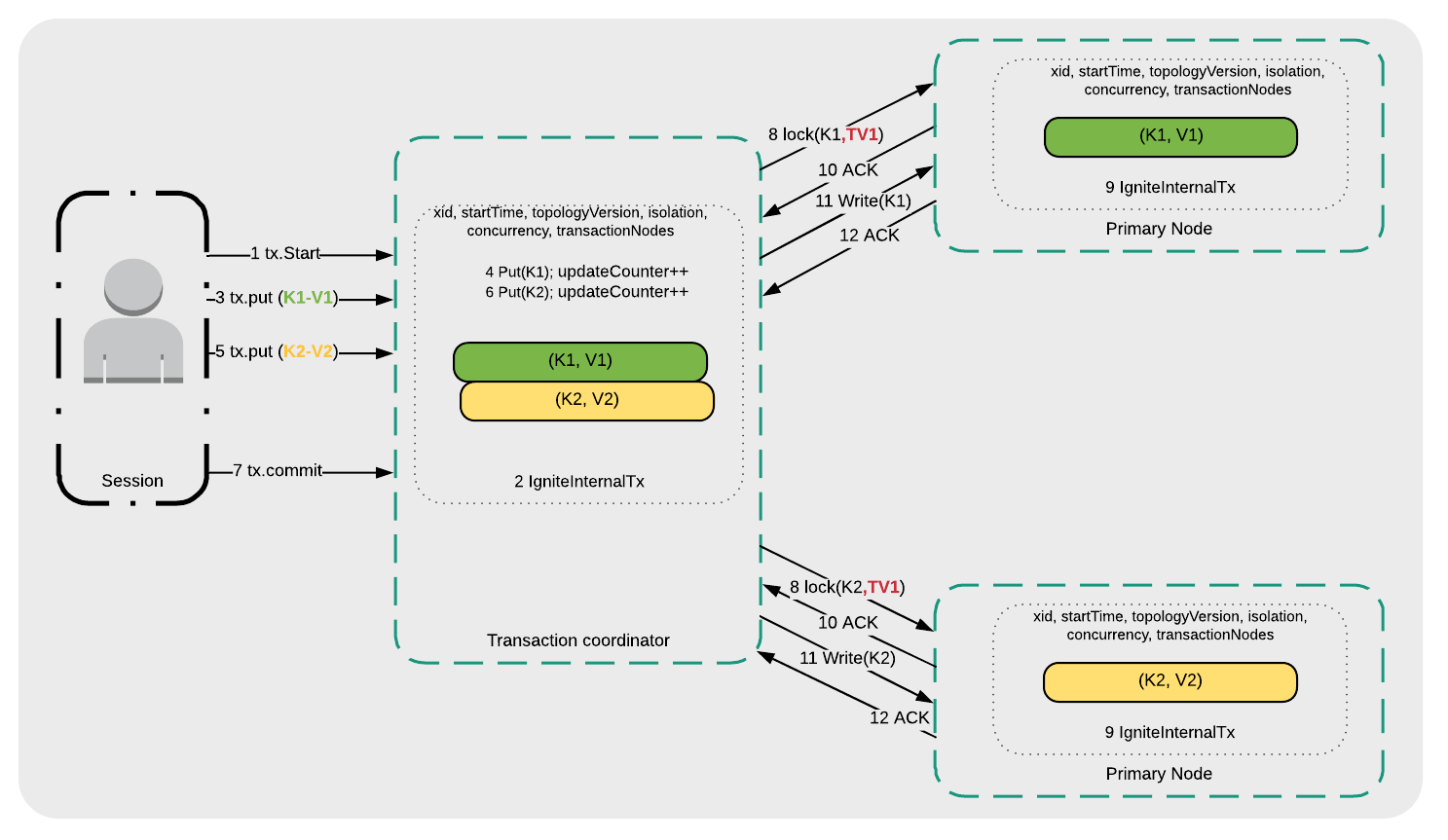
- 事务开始( 1 tx.Start );
- 事务协调器在内部管理事务请求( 2 IgniteInternalTx );
- 应用写入键K1( 3 tx.put(K1-V1) );
- 事务协调器将K1写入本地事务映射( 4 Put(K1) );
- 应用写入键K2( 5 tx.put(K2-V2) );
- 事务协调器将K2写入本地事务映射( 6 Put(K2) );
- 发起事务提交请求( 7 tx.commit );
- 事务协调器向存储K1和K2的主节点发起锁请求( 8 lock(K1, TV1) and 8 lock(K2, TV1) );
- 主节点在内部管理事务请求( 9 IgniteInternalTx );
- 主节点向事务协调者发送一个已经准备好的确认( 10 ACK );
- K1和K2写入相应的主节点( 11 Write(K1)和11 Write(K2) );
- 如果没有数据冲突(即K1和K2没有被其他的应用更新),主节点确认事务提交( 12 ACK )。
最后,看一下可重复读和读提交的消息流,如图4所示:
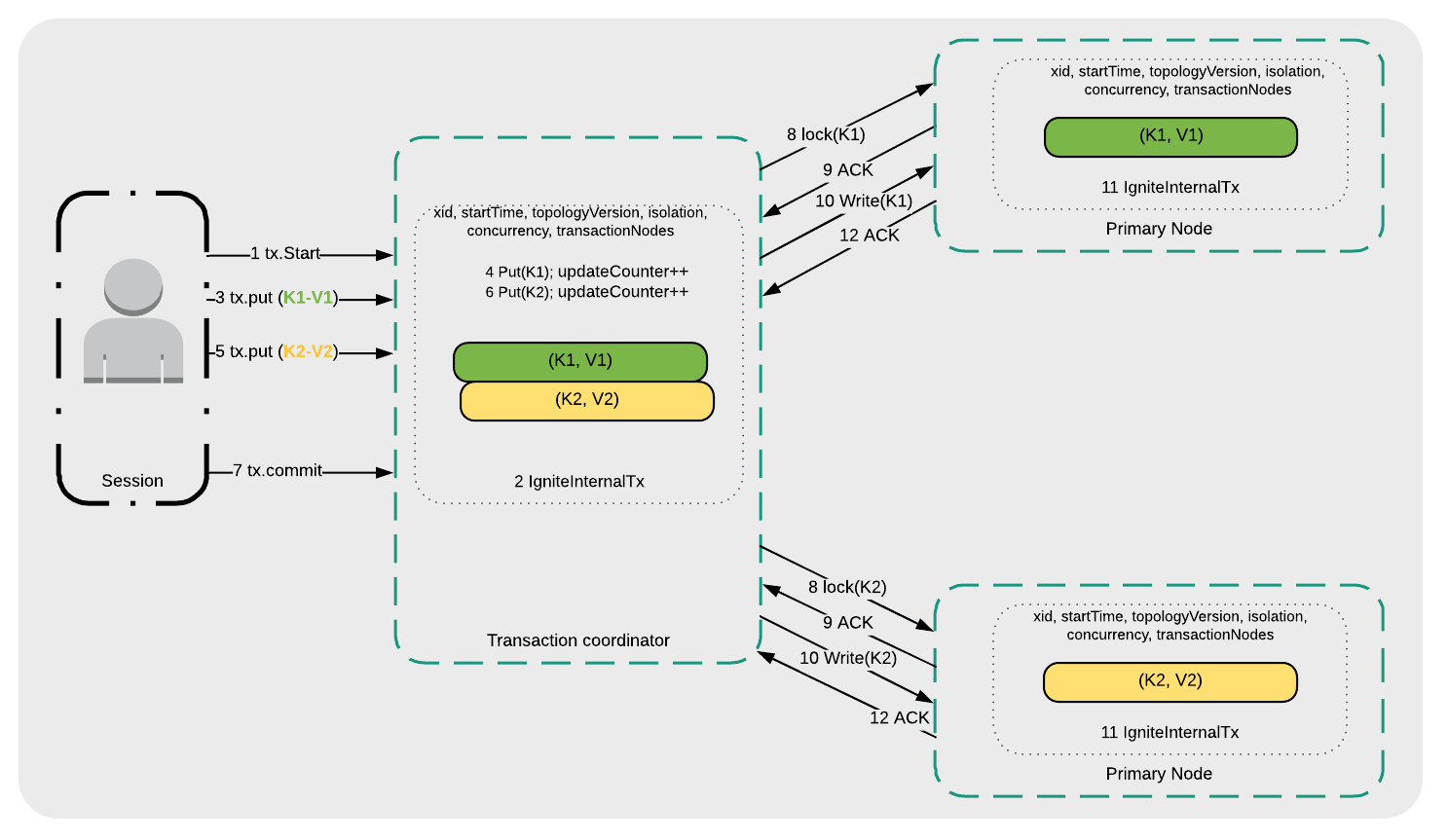
- 事务开始( 1 tx.Start );
- 事务协调器在内部管理事务请求( 2 IgniteInternalTx );
- 应用写入键K1( 3 tx.put(K1-V1) );
- 事务协调器将K1写入本地事务映射( 4 Put(K1) );
- 应用写入键K2( 5 tx.put(K2-V2) );
- 事务协调器将K2写入本地事务映射( 6 Put(K2) );
- 发起事务提交请求( 7 tx.commit );
- 事务协调器向存储K1和K2的主节点发起锁请求( 8 lock(K1, TV1) and 8 lock(K2, TV1) );
- 主节点向事务协调者发送一个已经准备好的确认( 9 ACK );
- K1和K2写入相应的主节点( 10 Write(K1)和10 Write(K2) );
- 主节点在内部管理事务请求( 11 IgniteInternalTx );
- 主节点确认事务提交( 12 ACK )。
总结
在本文中,研究了Ignite支持的主要的锁模型和隔离级别,我们看到,有很大的灵活性和选择空间,本系列的后面文章中,会研究故障转移和恢复。
本文译自GridGain技术布道师Akmal B. Chaudhri的 博客 。
来自:https://my.oschina.net/liyuj/blog/1627248
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/5942/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料