

一、理论概念
1、定义
进程(Process 也可以称为重量级进程)是程序的一次执行。在每个进程中都有自己的地址空间、内存、数据栈以及记录运行的辅助数据,它是系统进行资源分配和调度的一个独立单位。
2、并行和并发
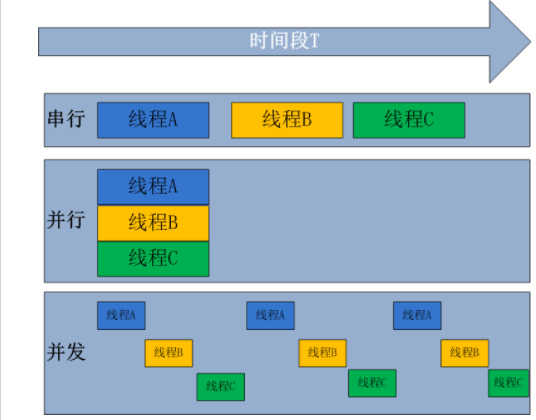
并行:并行是指多个任务同一时间执行;
并发:是指在资源有限的情况下,两个任务相互交替着使用资源;
3、同步和异常
同步是指多个任务在执行时有一个先后的顺序,必须是一个任务执行完成另外一个任务才能执行;
异步是指多个任务在执行时没有先后顺序,多个任务可以同时执行;
4、同步/异步/阻塞/非阻塞/
同步阻塞:这个阻塞的形成效率是最低的;比如你在下载一个东西是,你一直盯着下载进度条,到达100%时下载完成;
同步体现在:你等待下载完成通知;
阻塞体现在:等待下载的过程中,不能做别的事情
同步非阻塞:你在下载东西时,你把任务提交后就去干别的事情了,只是每过一段时间就看一下是不是下载完成;
同步体现在:等待下载完成通知;
非阻塞提现在:等待下载完成通知过程中,去干别的事情了,只是时不时会瞄一眼进度条;
异步阻塞:你在下载东西时换了一个现在使用的客户端比如迅雷,下载完成后会有一个提示音,但是这时候你仍然一直在等待那个完成后的提示音;
异步体现在:下载完成时有提示音;
阻塞体现在:等待下载完成提示音时,不做任何事情;
异步非阻塞:你然然使用的是迅雷下载软件,这时候你把下载任务提交后就去干别的事情去了,当你听到‘叮’以后就知道下载完成;
异步体现在:下载完成叮一声完成通知
非阻塞体现在:等待下载完成“叮”一声通知过程中,去干别的任务了,只需要接收“叮”声通知即可;
二、进程的创建与结束
multiprocessing模块:multiprocess不是一个模块而是python中一个操作、管理进程的包。 之所以叫multi是取自multiple的多功能的意思,在这个包中几乎包含了和进程有关的所有子模块。由于提供的子模块非常多,为了方便大家归类记忆,我将这部分大致分为四个部分:创建进程部分,进程同步部分,进程池部分,进程之间数据共享。
Process模块的各种方法介绍
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动)
强调:
1. 需要使用关键字的方式来指定参数
2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
参数介绍:
group参数未使用,值始终为None
target表示调用对象,即子进程要执行的任务
args表示调用对象的位置参数元组,args=(1,2,'egon',)
kwargs表示调用对象的字典,kwargs={'name':'egon','age':18}
name为子进程的名称
p.start():启动进程,并调用该子进程中的p.run()
p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
p.is_alive():如果p仍然运行,返回True
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
在windows中使用process注意事项:
在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。所以必须把创建子进程的部分使用if __name__ ==‘__main__’ 判断保护起来,import 的时候 ,就不会递归运行了。
process模块创建进程:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: caoyf
import time
from multiprocessing import Process
def func(name):
print('hello %s'%name)
print('我是子进程')
if __name__ == '__main__':
p = Process(target=func,args=('caoyf',)) #在实例化时候,args的参数必须是一个元祖形式(注册一个子进程)
p.start() #启动一个子进程
time.sleep(3)
print('执行主进程内容了')
创建第一个进程
多个进程同时运行,子进程的执行顺序不是根据启动的顺序来决定的;
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: caoyf
import time
from multiprocessing import Process
def func(name):
print('hello %s'%name)
time.sleep(2)
if __name__ == '__main__':
p_lst = []
for i in range(10):
p = Process(target=func, args=('caoyf',))
p.start()
p_lst.append(p)
for p in p_lst: p.join() # 是感知一个子进程的结束,将异步的程序改为同步
print('父进程在运行')
多个进程同时运行
另一种开启进程的方法,继承process的形式
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: caoyf
import time
import os
from multiprocessing import Process
class Func(Process):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print(os.getpid())
print('%s正在和小明聊天'%self.name)
if __name__ == '__main__':
p1 = Func('caoyf')
p2 = Func('Zhao')
p1.start()
p2.start()
p1.join()
p2.join()
继承的方式开启进程
守护进程:会随着主进程的结束而结束,进程之间是相互独立的,主进程的代码运行结束,守护进程也会随即结束
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: caoyf
import time
import os
from multiprocessing import Process
def foo():
print('start123')
time.sleep(2)
print('end123')
def func():
print('start456')
time.sleep(5)
print('end456')
if __name__ == '__main__':
p1 = Process(target=foo)
p2 = Process(target=func)
p1.daemon = True
p1.start()
p2.start()
time.sleep(0.1)
print('main------------')#打印该行则主进程代码结束,则守护进程p1应该被终止.#可能会有p1任务执行的打印信息123,因为主进程打印main---
# -时,p1也执行了,但是随即被终止.
守护进程
三、进程同步(multiprocessing.Lock\Spemaphore\Event)
锁(Lock):
资源是有限的,多个进程如果对同一个对象进行操作,则有可能造成资源的争用,甚至导致死锁,在并发进程中就可以利用锁进行操作来避免访问的冲突;
加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,但是速度就变慢了,但牺牲了速度却保证了数据安全。
虽然可以用文件共享数据实现进程间通信,但问题是:
1.效率低(共享数据基于文件,而文件是硬盘上的数据)
2.需要自己加锁处理
我们可以模拟一个火车抢票的过程,当过个客户同时对一个程序发起访问时,假设此时有5张票,有10个人抢
from multiprocessing import Process,Lock
import time,json,random
def search():
dic=json.load(open('db'))
print('\033[43m剩余票数%s\033[0m' %dic['count'])
def get():
dic=json.load(open('db'))
time.sleep(random.random()) #模拟读数据的网络延迟
if dic['count'] >0:
dic['count']-=1
time.sleep(random.random()) #模拟写数据的网络延迟
json.dump(dic,open('db','w'))
print('\033[32m购票成功\033[0m')
else:
print('\033[31m购票失败\033[0m')
def task(lock):
search()
lock.acquire()
get()
lock.release()
if __name__ == '__main__':
lock = Lock()
for i in range(100): #模拟并发100个客户端抢票
p=Process(target=task,args=(lock,))
p.start()
抢火车票
信号量:
信号量Semaphore是同时允许一定数量的线程更改数据 。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: caoyf
import time
import random
from multiprocessing import Semaphore
from multiprocessing import Process
def f(i,a):
a.acquire()
print('%s走进了房间'%i)
time.sleep(random.randint(1,5))
print('%s走出了房间'%i)
a.release()
if __name__ == '__main__':
a = Semaphore(5)
for i in range(10):
p = Process(target=f,args=(i,a))
p.start()
信号量
事件:
用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
clear:将“Flag”设置为False
set:将“Flag”设置为True
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: caoyf
from multiprocessing import Event,Process
import random
import time
def cars(a,i):
if not a.is_set():
print('car%s在等待'%i)
a.wait()
print('\033[31mcar%s通过\033[0m' % i)
def f(a):
while True:
if a.is_set():
a.clear()
print('\033[31m红灯亮了\033[0m')
else:
a.set()
print('\033[32m绿灯亮了\033[0m')
time.sleep(2)
if __name__ == '__main__':
a = Event()
p = Process(target=f,args=(a,))
p.start()
for i in range(20):
car = Process(target=cars,args=(a,i))
car.start()
time.sleep(random.random())
事件/红绿灯实例
四、进程间通信---队列和管道
队列Queue:适用于多线程编程的先进先出数据结构,可以用来安全的传递多线程信息。
通过队列实现了 主进程与子进程的通信 子进程与子进程之间的通信
q=Queue(10) #实例化一个对象,允许队列对多10个元素
q.put() #放入队列
q.get() #从队列中取出
假设现在有一个队伍,队伍里最多只能站5个人,但是有15个人想要进去
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: caoyf
from multiprocessing import Process
from multiprocessing import Queue
def getin(q): #进入队伍的子进程
for i in range(15):
q.put(i)
# print(q)
def getout(q): #离开队伍的子进程
for i in range(6):
print(q.get())
if __name__=='__main__':
q=Queue(5) #队伍内最多可以容纳的人数
p=Process(target=getin,args=(q,)) #进入队伍的进程
p.start()
p2=Process(target=getout,args=(q,)) #离开队伍的进程
p2.start()
队列实例
管道(Pipes)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: caoyf
from multiprocessing import Process,Pipe,Manager,Lock
import time
import random
# 管道 进程之间创建的一条管道,默认是全双工模式,两头都可以进和出,
# 注意 必须在产生Process对象之前产生管道
# 如果在Pipe括号里面填写False后就变成了单双工,
# 左边的只能收,右边的只能发,recv(接收),send(发送)
#如果没有消息可以接收,recv会一直阻塞,如果连接的另外一段关闭后,
#recv会抛出EOFError错误
# close 关闭连接
#下面的实例是在Pipe的括号里填写和不填写False的区别
# from multiprocessing import Process,Pipe
# def func(pro):
# pro.send('hello')
# pro.close()
#
# if __name__=='__main__':
# con,pro = Pipe(False)
# p = Process(target=func,args=(pro,))
# p.start()
# print(con.recv())
# p.join()
# 模拟recv阻塞情况
# def func(con,pro):
# con.close()
# while 1:
# try:
# print(pro.recv())
# except EOFError:
# pro.close()
# break
#
#
# if __name__=='__main__':
# con,pro = Pipe()
# p = Process(target=func,args=(con,pro,))
# p.start()
# pro.close()
# con.send('aaaaa')
# con.close()
# p.join()
# 利用管道实现生产者和消费者
# def sc(con,pro,name,food):
# con.close()
# for i in range(5):
# time.sleep(random.random())
# f = '%s生产了%s%s'%(name,food,i)
# print(f)
# pro.send(f)
# def xf(con,pro,name):
# pro.close()
# while 1:
# try:
# baozi = con.recv()
# print('%s消费了%s'%(name,baozi))
# except EOFError:
# break
# if __name__=='__main__':
# con,pro = Pipe()
# p1 = Process(target=sc,args=(con,pro,'caoyf','包子'))
# c1 = Process(target=xf,args=(con,pro,'zhoaf'))
# p1.start()
# c1.start()
# con.close()
# pro.close()
# p1.join()
管道
数据共享:
队列和管道只是实现了数据的传递,还没有实现数据的共享,如实现数据共享,就要用到Managers( 注:进程间通信应该尽量避免使用共享数据的方式 )
from multiprocessing import Process,Manager
import os
def f(dict1,list1):
dict1[os.getpid()] = os.getpid() # 往字典里放当前PID
list1.append(os.getpid()) # 往列表里放当前PID
print(list1)
if __name__ == "__main__":
with Manager() as manager:
d = manager.dict() #生成一个字典,可在多个进程间共享和传递
l = manager.list(range(5)) #生成一个列表,可在多个进程间共享和传递
p_list = []
for i in range(10):
p = Process(target=f,args=(d,l))
p.start()
p_list.append(p) # 存进程列表
for res in p_list:
res.join()
print('\n%s' %d) #若要保证数据安全,需要加锁lock=Lock()
进程池
对于需要使用几个甚至十几个进程时,我们使用Process还是比较方便的,但是如果要成百上千个进程,用Process显然太笨了,multiprocessing提供了Pool类,即现在要讲的进程池,能够将众多进程放在一起,设置一个运行进程上限,每次只运行设置的进程数,等有进程结束,再添加新的进程
- Pool(processes =num):设置运行进程数,当一个进程运行完,会添加新的进程进去
- apply_async:异步,串行
- apply:同步,并行
- close():关闭pool,不能再添加新的任务
import os
import time
import random
from multiprocessing import Pool
from multiprocessing import Process
def func(i):
i += 1
if __name__ == '__main__':
p = Pool(5) # 创建了5个进程
start = time.time()
p.map(func,range(1000))
p.close() # 是不允许再向进程池中添加任务
p.join() #阻塞等待 执行进程池中的所有任务直到执行结束
print(time.time() - start)
start = time.time()
l = []
for i in range(1000):
p = Process(target=func,args=(i,)) # 创建了一百个进程
p.start()
l.append(p)
[i.join() for i in l]
print(time.time() - start)
回调函数:
import os
import time
from multiprocessing import Pool
# 参数 概念 回调函数
def func(i): # 多进程中的io多,分出去一部分
print('子进程%s:%s'%(i,os.getpid()))
return i*'*'
def call(arg): # 回调函数是在主进程中完成的,不能传参数,只能接受多进程中函数的返回值
print('回调 :',os.getpid())
print(arg)
if __name__ == '__main__':
print('主进程',os.getpid())
p = Pool(5)
for i in range(10):
p.apply_async(func,args=(i,),callback=call) #callback 回调函数 :主进程执行 参数是子进程执行的函数的返回值
p.close()
p.join()
来自:http://www.cnblogs.com/caoyf1992/p/8687352.html?utm_source=tuicool&utm_medium=referral
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/5972/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料