

对于iOS程序员来说,内存管理是入门的必修课。引用计数、自动释放等概念,都是与C语言完全不同的。搞明白这些,代码才有可能不crash。然而就是这么牛逼的内存管理,着实让我这个从 C 转过来的老程序员头疼了一段时间。
[C++ 程序员的迷惑和愤怒]
iOS 内存管理的核心是引用计数。与众多五年甚至更多以上开发经验的程序员一样,笔者当初是从 C/C++转到的 OC,接触到 MRC。当时遇到最头疼的问题就是:为什么那么多 release?到底什么地方会 release?同样初始化一个字符串的两个方法为什么不同?上边一个不需要调用 release,后边一个就需要调用 release?
NSString * str1 = [NSString stringWithFormat:”qqstock“];
NSString * str2 = [[NSString alloc] initWithData:recvData encoding:NSUTF8StringEncoding];
再加上一个属性赋值与成员变量赋值,一个导致计数器加一,一个就不会!真他妈奇葩了!
self.name = @“qqstock”;
_name = @“qqstock”;
不知道是不是所有从 C/C++ 转过来的程序员都遇到过类似的迷惑和愤怒。
[MRC 的初衷和实现方式]
那么,苹果为什么要做这个?
首先,C/C++ 传统的内存管理方式,所有的内存都需要业务代码自己处理,程序员自己一定要知道一个内存对象什么时候不再使用了,一定要知道这个内存对象的终点在哪里。当代码越来越复杂,参与开发的程序员越来越多,甚至随着岁月的流逝更换了新的程序员,这个时候,很难有人说的清了。于是,要么那个内存对象一直留在那里,没人敢释放,整个程序占用的空间越来越大;要么,一个胆大的程序员将它释放掉,某处发生了crash。尽管大家总结出许多类似“谁创建谁释放”、“谁持有谁释放” 的原则,但都导致存储空间的浪费:为了保留仅仅一个内存对象,却要将与它关联的一大堆对象保留住,而其中大部分已经不再使用了。要么,自己写许许多多的代码,频繁对容器进行主动操作。 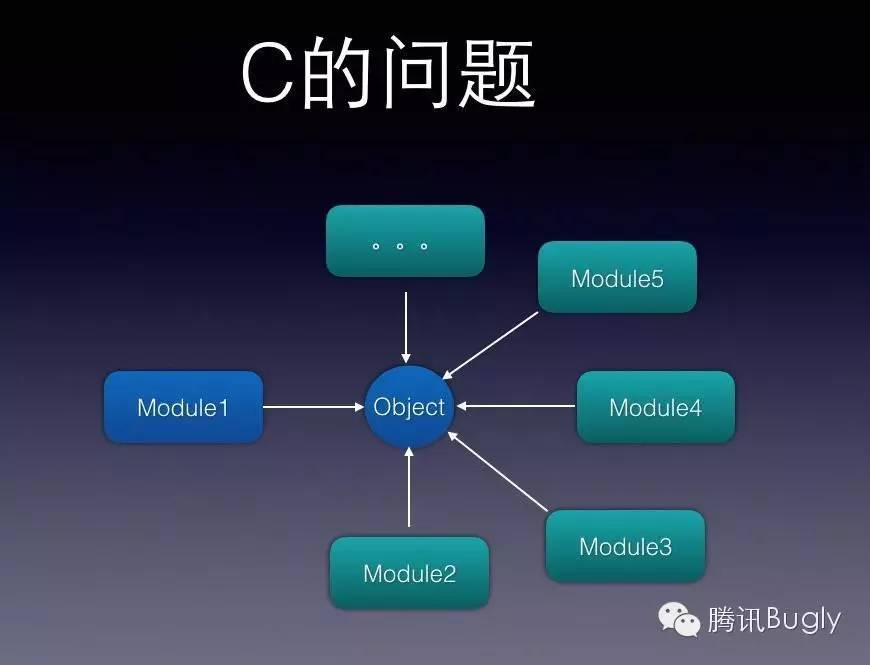
于是,苹果要解决这个问题。初衷就是:任何一个内存对象由系统自己处理释放的问题,无论创建者也好,持有者也好,不需要去考虑别人是否还在使用同一个内存对象,做好自己该做的就是了,别人的事情别人负责。苹果实现此目的的手段就是引用计数。所有使用到同一内存对象的地方,使用者只要保证自己 retain 一次,release 一次,就 OK 了,即便别人还在使用,你只要调用 release 将自己的引用次数清零就好了,不用管别人!
与 C/C++传统的内存管理方式相比,MRC 是不是显得非常智能?是不是更加方便?而且,这样做的代价也非常低廉,每一个内存对象增加一个计数器就 OK 了,每一次 release,只需要检查一遍计数器是否为零,如果为零就释放,如果不为零就不执行真正的释放逻辑。
另外,为了解决函数返回值的问题,需要搞一个 autorelease 的东西,否则就会打破这个良好的初衷:“只负责自己范围内的事情就 OK了,不要管别人!”
那么,为什么不将所有内存对象都统一成 retain呢?对于一种编译器,它能够用一个技术解决所有问题,就坚决不会用两种并列的技术导致问题更复杂。
OC 有一个 delegate 的东西,这个东西的出现也是有其现实需求的,在此先跳过。如果所有地方都使用 retain,delegate 的问题一定会导致循环引用,除了 delegate,苹果不敢保证所有用户代码的逻辑都是树形结构的,最简单的比如说循环链表、双向链表,除此之外,业务层肯定也有某些地方必须做成“循环引用”,如果都是 retain,那么,最终处于循环中的内存对象谁也不会被最终释放掉。为了解决这个问题,苹果依然保留了 C/C++的那种弱引用方式。——至少给程序员留个过渡的空间。
[MRC 的优点和无奈]
总结一下:
- MRC 的计数器机制改善了内存管理的方式,减少了各个模块的逻辑耦合,释放了程序员对“何时该释放”的心理压力,解决了大部分的问题
- 为了应对各种复杂的场景,很无奈的留了一个口子;
- 两种模式的并存,对 C++程序员转移到 OC战场,树立了一个无形的心理门槛,使得起步阶段问题更加复杂,比如:retain、assign、release、autorelease 等。
难道就没有更好的方式么?当然有更好的方式,而且一定有许多公司的 C++程序员或者 C 程序员写了类似引用计数的程序,甚至比引用计数还要高级,只不过大多数公司没有实力推广一个编程语言而已。
而且,略微深入思考,一定许多人想到:如果让系统对所有内存对象在运行时统一管理,问题就能彻底解决了。是的,的确如此,一定有人设计出来了。但是,代价比较高。
系统在运行时统一管理所有内存对象的释放,会导致增加额外的内存和 CPU 开销,在硬件设备尚且处于低级阶段的时候,当程序员们依然在努力降低内存降低 CPU 消耗的时候,推出这样的机制,是不合时宜的!
引用计数器的方式,编译器并没有增加太多的逻辑,只是在创建的时候增加一个计数器,在释放的时候编译器自动帮程序员增加一个逻辑判断。这个逻辑并没有增加太多的内存和 CPU 开销。
再来看 autorelease,这个逻辑增加的成本可就大了去了,系统要一直持有该类型的内存对象,直到本次 runloop 结束。所以,无论苹果,还是有经验的程序员,都建议:能不用就尽量不用,能缩短范围就尽量缩短范围。 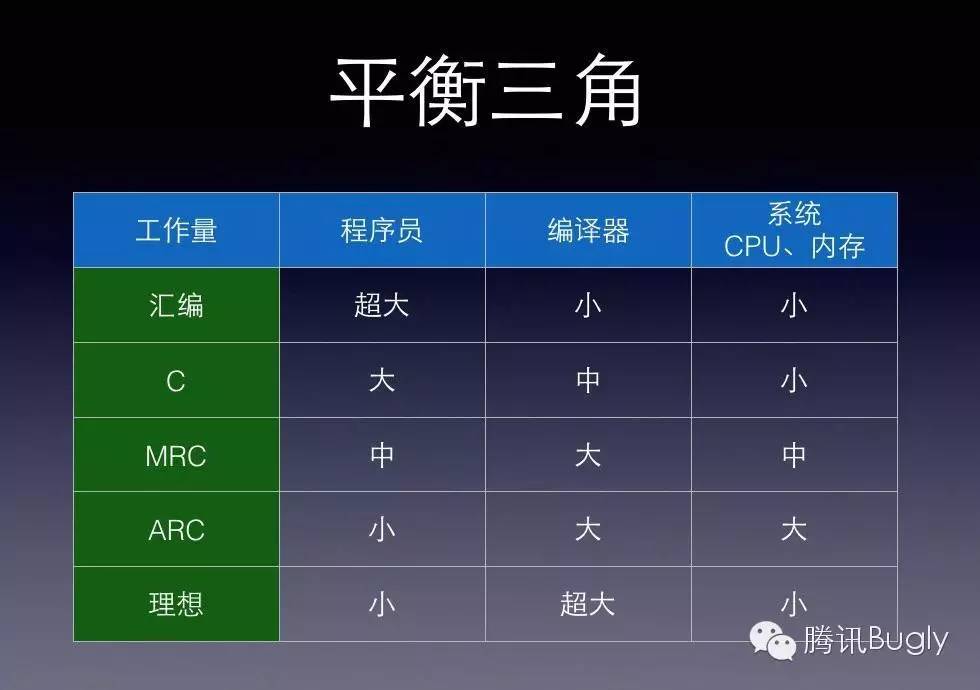
[编程语言和编译器的发展方向]
由于留了无奈的口子,野指针依然会出现,该 crash 的时候依然 crash。许多人说:这是程序员的问题,如果代码写的足够好,一定不会出现野指针,一定不会出现 crash。是的,如果大家足够小心,如果大家足够尽力,这个世界上不会有任何冲突。
然而,编程语言和编译器的发展,一定向着便利、易用、稳健、职能,甚至傻瓜!如果一个编译器能够让一个对计算机毫无了解的人一天之内搞出自己想要的业务应用,谁又会拒绝呢?
许多程序员都是技术控,自己能做的事情尽量不让别人做,自己能实现的逻辑尽量不用别人的。比如:C++的各种封装、引用,我用 C 也能实现,有什么大不了的!系统提供的各种类库,我自己用底层的代码也能实现,而且性能更优,代码更少!但是,如果你连一个砖头都要自己烧制,连一堵墙都要自己去砌,其它更重要的事情谁去做?
更何况,人,总有打盹的时候。 
[ARC 的适时推出]
随着硬件的升级,条件已经成熟了,ARC到来了!
ARC 的初衷是为了让程序员写代码的时候更加便利,最好不用再关注任何内存释放的问题(也不用关注用什么方式初始化的问题)。当然了,解决野指针的问题也是很重要的!总之,让编码更加简单,程序更加健壮!
之前对 C++程序员头疼的问题变得异常简单:
NSString * str1 = [NSString stringWithFormat:”qqstock“];
NSString * str2 = [[NSString alloc] initWithData:recvData encoding:NSUTF8StringEncoding];
self.name = @“qqstock”; _name = @“qqstock”;
到底何时释放?总之,你不用管了,用你的就好! 到底有何区别?没啥区别,只管用就好了!
笔者之前一直很疑惑,因为自己一直想搞明白到底有何区别——技术控本质。现在,了解了ARC的初衷,也就敢于放心大胆的用了——许多刨根究底的程序员从汇编代码也印证了这个“猜想”。ARC 的目的就是将程序员从 MRC 的各种”不同点“上解脱出来,对于尚未接触过 MRC 的 C 程序员,是非常容易理解的,而对于已经习惯了 MRC 的程序员,反倒有点”不敢相信“!
如果让你做,你会如何实现?逻辑其实很简单。 首先,强引用依然保留 MRC 的方式,因为这样实现的方式代价很低; 其次,一旦出现弱引用,则将内存对象在系统中建立映射表;一旦内存对象因为所有强引用归零而释放,则将所有弱引用指针归零(指向 nil)——应该有一个链表。
其实,将弱引用强制指向 nil,也是一种无奈的方式,按理说,这依然是个隐患,是代码逻辑的缺陷,只是人家帮你将错误的代价降到最低而已。
总之,强引用的逻辑是:如果都不用了,我就释放掉;弱引用的逻辑是:如果释放了,我就置 nil!最终,程序员不需要关注内存的持有和释放问题,更不需要关注别的模块是否依然在使用同一个内存。做好自己分内的事情,别的事情交给系统和编译器! 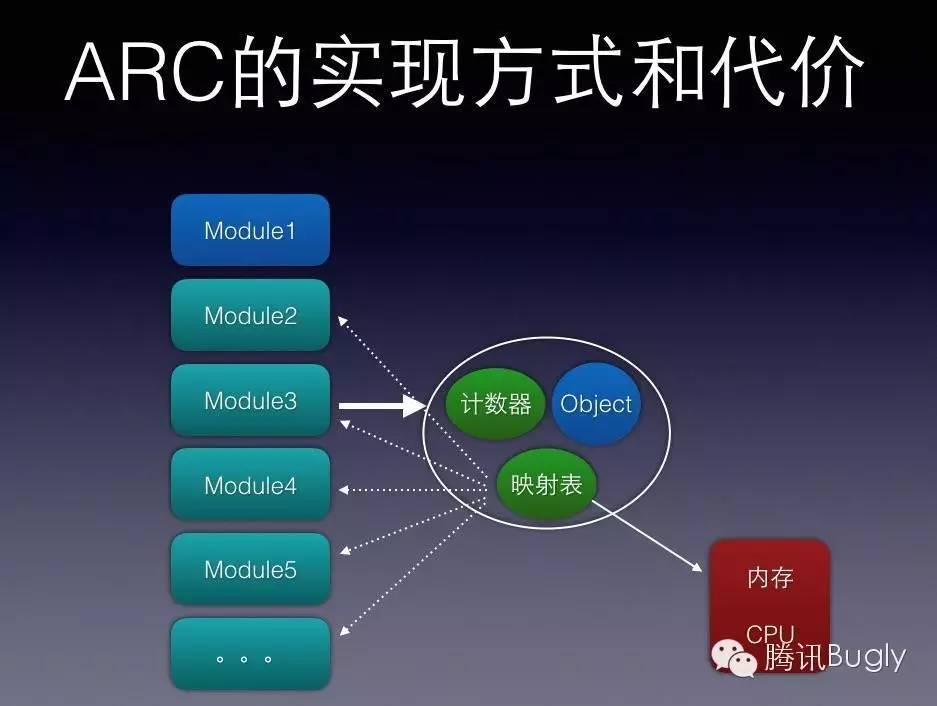
[总结]
其实,笔者之前对 ARC 的了解也仅仅在 coding 层面,最近打算将老的项目从 MRC 转到 ARC,需要提前让团队的所有人了解代码如何迁移,否则即便依靠一两个人的力量将代码迁移了,开发人员的意识和 coding 依然停留在 MRC,那后续的开发任务将会极其危险。但凡做大的动作就应该首先在团队层面无论是意识还是能力上做好准备,否则就等着填坑吧。
于是突发奇想,想对苹果问一个为什么?即:苹果为什么要搞一个 ARC?任何一件事情,都不是毫无来由的。一个极客程序员可能会突发奇想搞个牛逼的技术来展现自己的才华,但苹果这么大一个公司,做这么大的改动,一定是有缘由的。果不其然,当自己费尽心思将这个问题搞清楚之后,如何 coding 的问题也得到了大幅提升!
回头想想,这条路是很牛逼的,如果所有地方都用强引用,或者所有地方都交予系统管理,势必会导致内存的快速膨胀。某些其它语言的例子就非常明显,无论程序员如何努力,内存也很难降低下来。
一个心得就是:许多问题,如果我们能够站在设计者的立场上考虑,就能够更加清楚自己该如何 coding,设计者的初衷决定了我们 coding 的方式,设计者的 coding 决定了我们的思维方式。
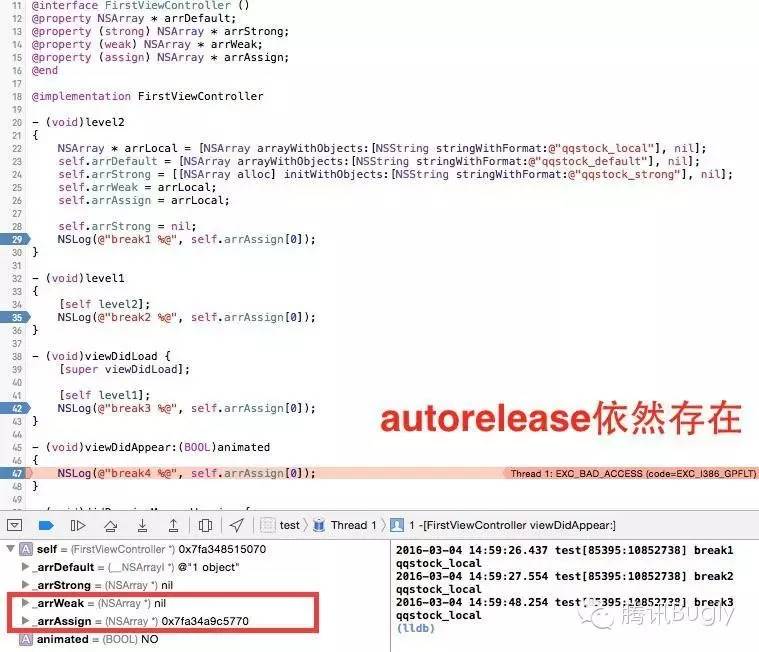
以下是一个简单的 demo,从代码运行结果能够很明显的验证 ARC 下 strong、weak、assign、局部变量、类方法初始化以及 autorelease 等使用方法与MRC下的不同。
首先:使用 retain 类型初始化方法给 weak 和 assign 类型变量赋值时,编译器会报警。 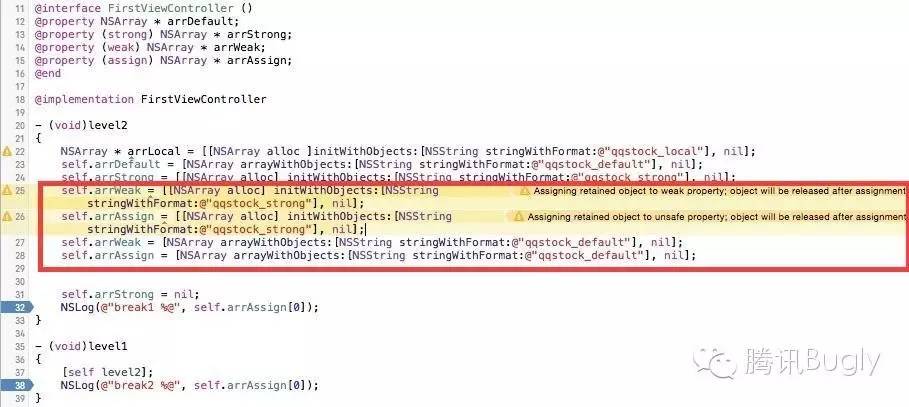
其次:weak 变量当其指向的变量的所有强引用置零后,自己会被置 nil,而 assign 却不会。 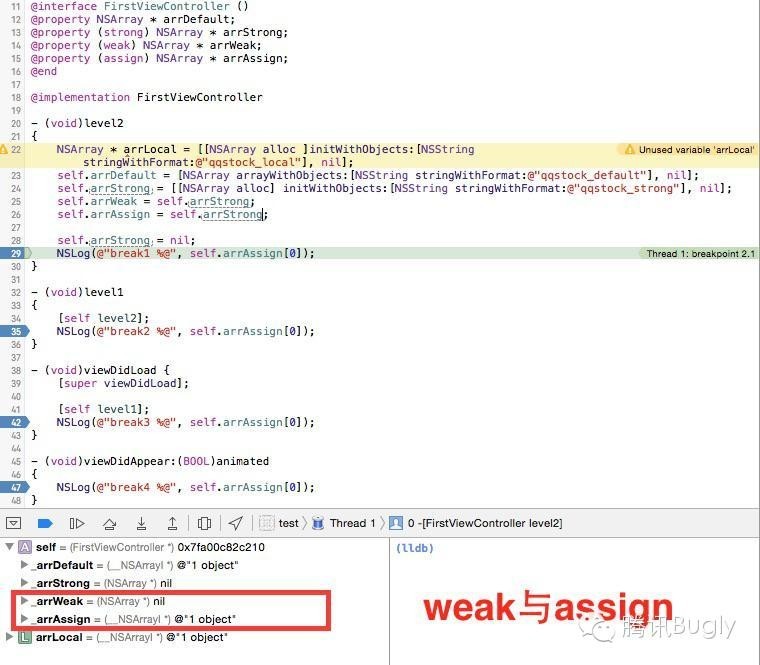
再有:weak 变量被置 nil,不是当其指向变量析构的时候,而是在强引用归零的时候就已经发生了。 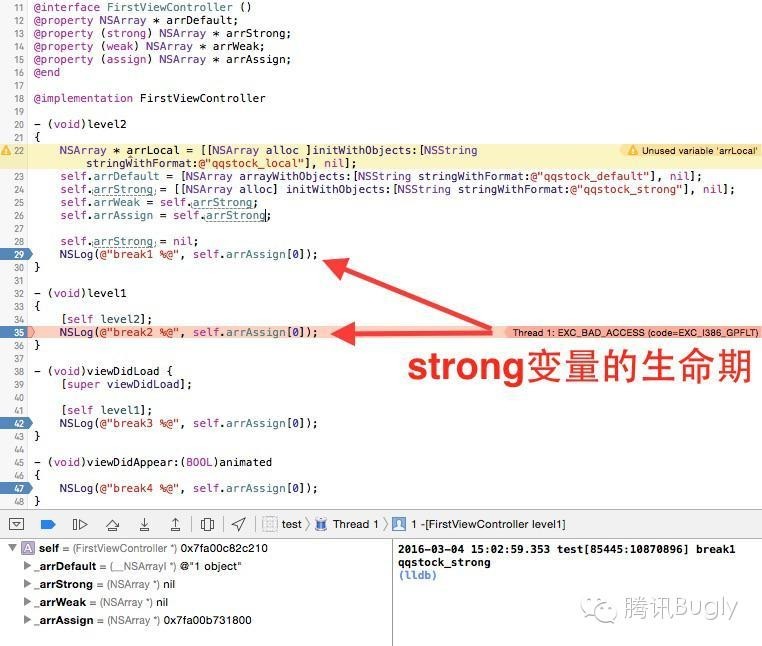
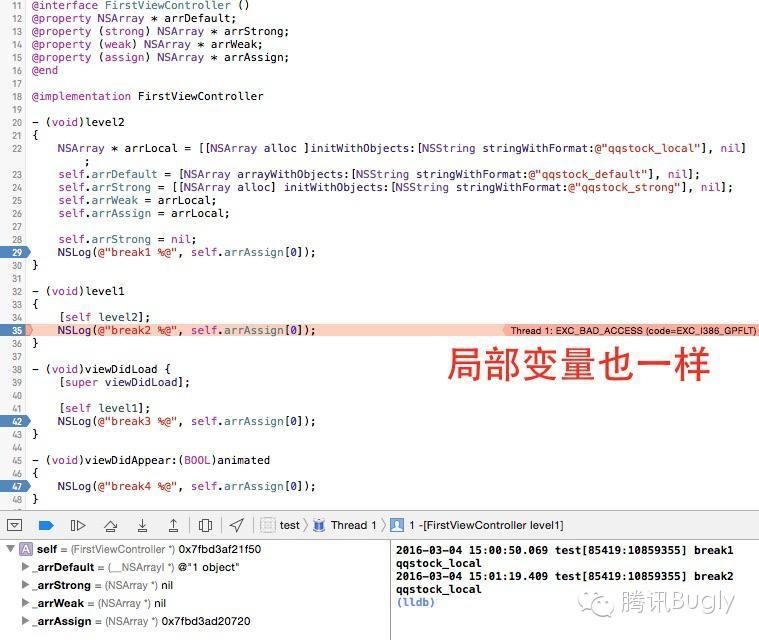
还有,各种类方法初始化的 autorelease 对象,依然是在 runloop 结束的时候析构的,而 retain 类型的对象,却是在代码模块终止的时候析构的。所以,出于内存管理的考虑,依然建议少用 autorelease。 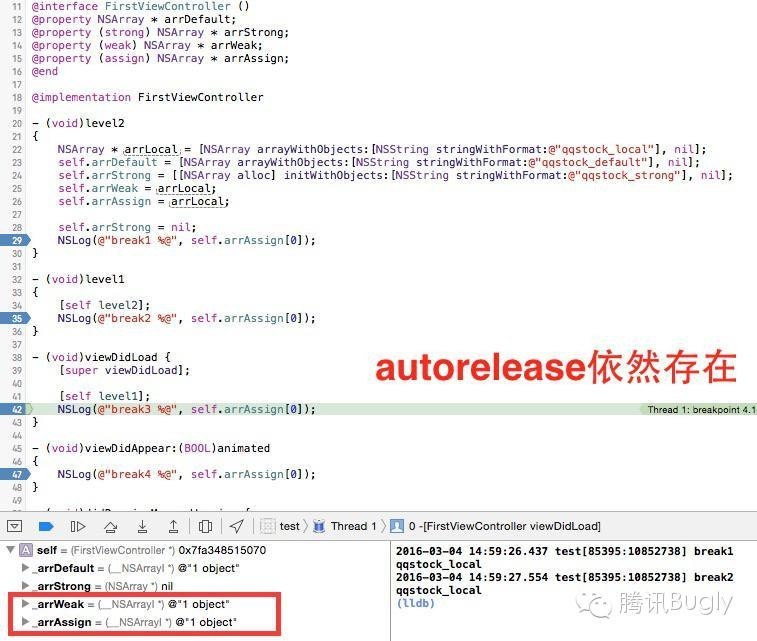
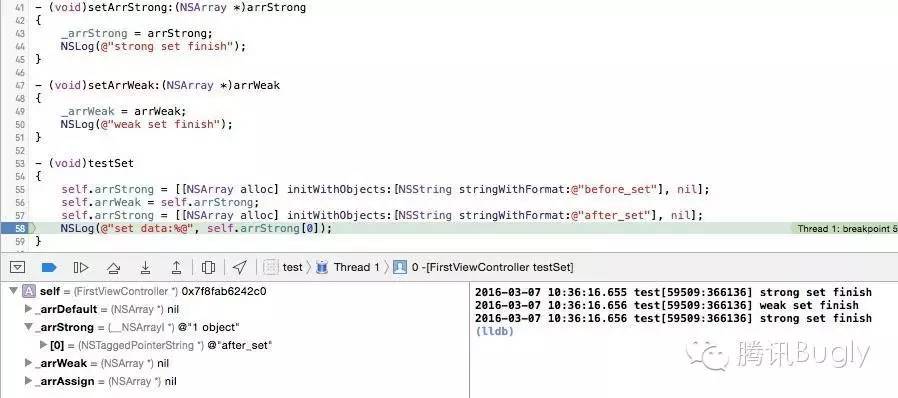
最后,strong 和 weak 对应的 set 方法,简单了许多哦!
来自:http://dev.qq.com/topic/59194943f473278853516915
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/6043/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料