

sync.WaitGroup里面的实现逻辑其实蛮简单的,在看过之前的sync.Mutex和synx.RWMutex之后,阅读起来应该非常简单,而唯一有差异的其实就是sync.WaitGroup里面的state1
1.1 等待机制
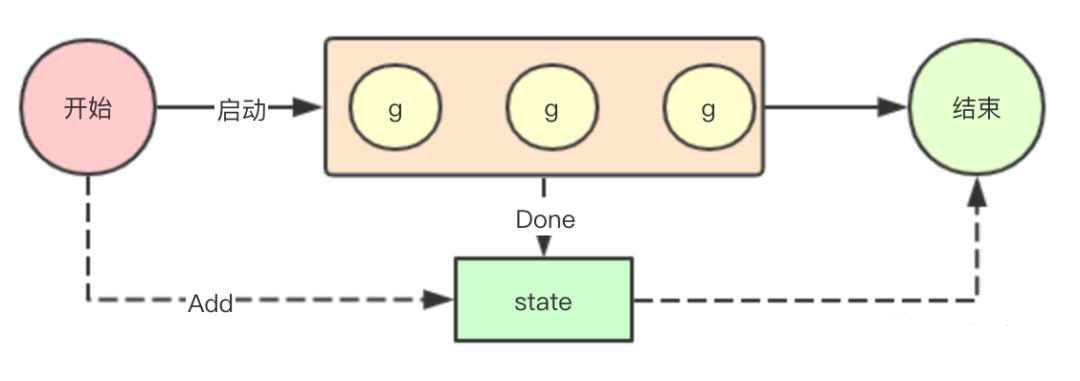
sync.WaitGroup主要用于等待一组goroutine退出,本质上其实就是一个计数器,我们可以通过Add指定我们需要等待退出的goroutine的数量,然后通过Done来递减,如果为0,则可以退出
1.2 内存对齐

内存对齐是一个比较大的话题,其核心机制是编译器根据结构体内部元素的size结合平台和编译器自身的规则来进行补位, 而在sync.WaitGroup里面就有用到,也是我感觉可能在WaitGroup所有实现的核心特性里面最重要的一条了
在WaitGroup里面只有state1 [3]uint32这一个元素,通过类型我们可以计算uint32是4个字节,长度3的数组总长度12,其实之前这个地方是[12]byte, 切换uint32是go语言里面为了让底层的编译器保证按照4个字节对齐而做的切换
1.3 8字节
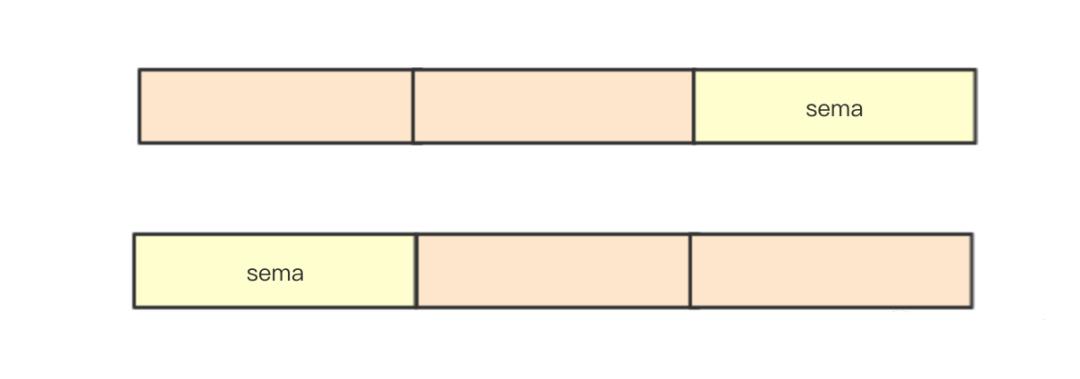
8字节即两个4字节,也就是两个uint32的长度,实际上也是一个uint64的长度,在sync.WaitGroup里面通过uint64来进行等待数量的计数
这里有一个相对比较hack的问题,我翻阅过很多文章,都没有找到能让我完全信服的答案,接下来就是我自己的臆测了
1.4 8字节的臆测
首先go语言需要兼容32位和64位平台,但是在32位平台上对64字节的uint操作可能不是原子的,比如在读取一个字长度的时候,另外一个字的数据很有可能已经发生改变了(在32位操作系统上,字长是4,而uint64长度为8), 所以在实际计数的时候,其实sync.WaitGroup也就使用了4个字节来进行

在cpu内有一个cache line的缓存,这个缓存通常是8个字节的长度,在intel的cpu中,会保证针对一个cache line的操作是原子,如果只有8个字节很有可能会出现上面的这种情况,即垮了两个cache line, 这样不论是在原子操作还是性能上可能都会有问题
1.5 测试8字节指针
我这里简单构造了一个8字节的长度指针,来做演示,通过读取底层数组的指针和偏移指针(state1数组的第2个元素即index=1)的地址,可以验证猜想即在经过编译器进行内存分配对齐之后,如果当前元素的指针的地址不能为8整除,则其第地址+4的地址,可以被8整除(这里感觉更多的是在编译器层才能看到真正的东西,而我对编译器本身并不感兴趣,所以我只需要一个证明,可以验证结果即可)
import ( "unsafe" ) type a struct { b byte } type w struct { state1 [3]uint32 } func main() { b := a{} println(unsafe.Sizeof(b), uintptr(unsafe.Pointer(&b)), uintptr(unsafe.Pointer(&b))%8 == 0) wg := w{} println(unsafe.Sizeof(wg), uintptr(unsafe.Pointer(&wg.state1)), uintptr(unsafe.Pointer(&wg.state1))%8 == 0) println(unsafe.Sizeof(wg), uintptr(unsafe.Pointer(&wg.state1[1])), uintptr(unsafe.Pointer(&wg.state1[1]))%8 == 0) }
输出结果
1 824633919343 false 12 824633919356 false 12 824633919360 true
1.6 分段计数
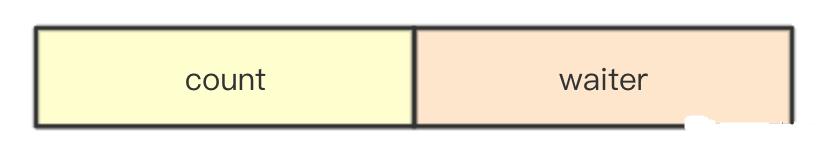
在sync.WaitGroup中对上面的提到的8字节的uint64也是分段计数,即高位记录需要等待 Done的数量,而低位记录当前正在Wait等待结束的计数
2. 源码速读
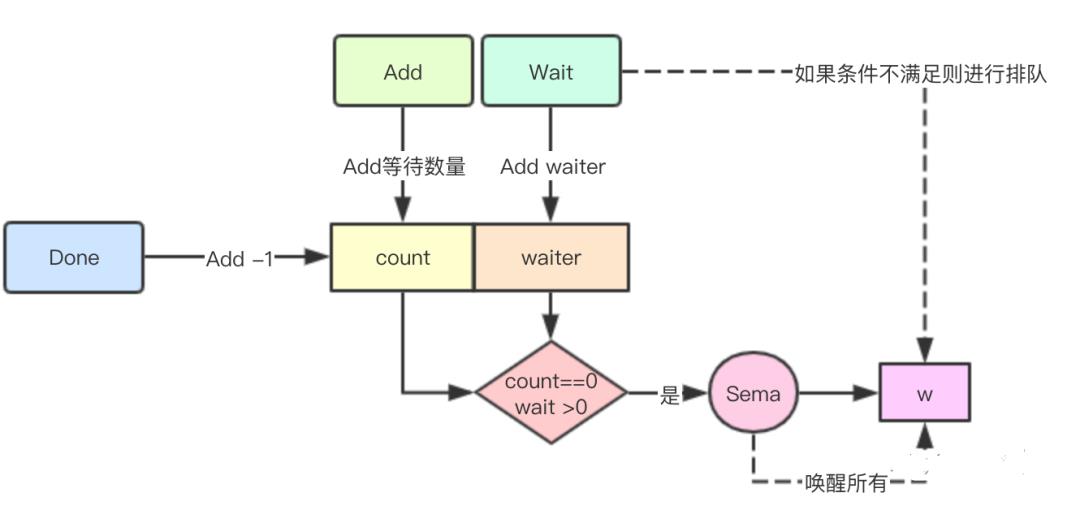
1.核心原理就是通过之前说的64位的uint64来进行计数,采用高位记录需要Done的数量,低位记录Wait的数量2.如果发现当前count>0则Wait的goroutine会进行排队3.任务完成后的goroutine则进行Done操作,直到count==0,则完成,就唤醒所有因为wait操作睡眠的goroutine
2.1 计数与信号量
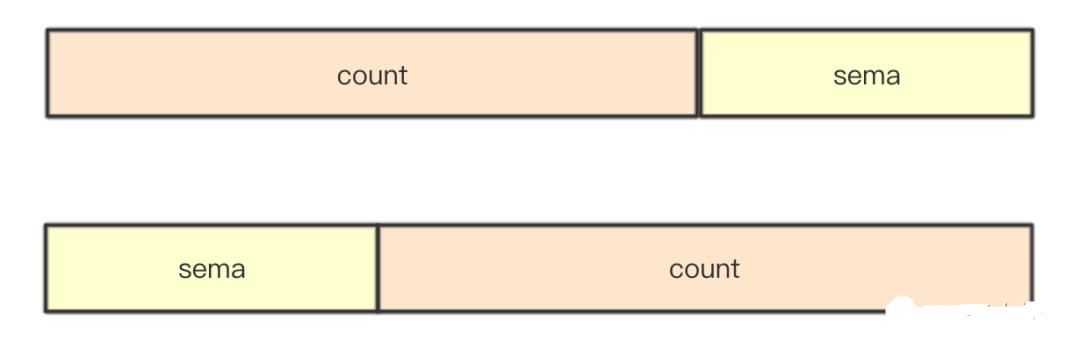
就像基础部分说的那样,针对12字节的[3]uint32会根据当前指针的地址来进行计算,确定采用哪个分段进行计数和做为信号量等待,详细的说明上面已经提过,这里只是根据采取的分段,然后将对应的分段转换为*uint64的指针和一个uint32的指针就可以了
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) { if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 { return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2] } else { return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0] } }
2.2 添加等待计数
func (wg *WaitGroup) Add(delta int) { // 获取当前计数 statep, semap := wg.state() if race.Enabled { _ = *statep // trigger nil deref early if delta < 0 { // Synchronize decrements with Wait. race.ReleaseMerge(unsafe.Pointer(wg)) } race.Disable() defer race.Enable() } // 使用高32位进行counter计数 state := atomic.AddUint64(statep, uint64(delta)<<32) v := int32(state >> 32) // 获取当前需要等待done的数量 w := uint32(state) // 获取低32位即waiter等待计数 if race.Enabled && delta > 0 && v == int32(delta) { // The first increment must be synchronized with Wait. // Need to model this as a read, because there can be // several concurrent wg.counter transitions from 0. race.Read(unsafe.Pointer(semap)) } if v < 0 { panic("sync: negative WaitGroup counter") } if w != 0 && delta > 0 && v == int32(delta) { panic("sync: WaitGroup misuse: Add called concurrently with Wait") } // 如果当前v>0,则表示还需要继续未完成的goroutine进行Done操作 // 如果w ==0,则表示当前并没有goroutine在wait等待结束 // 以上两种情况直接返回即可 if v > 0 || w == 0 { return } // 当waiters > 0 的时候,并且当前v==0,这个时候如果检查发现state状态前后发生改变,则 // 证明当前有人修改过,则删除 // 如果走到这个地方则证明经过之前的操作后,当前的v==0,w!=0,就证明之前一轮的Done已经全部完成,现在需要唤醒所有在wait的goroutine // 此时如果发现当前的*statep值又发生了改变,则证明有有人进行了Add操作 // 也就是这里的WaitGroup滥用 if *statep != state { panic("sync: WaitGroup misuse: Add called concurrently with Wait") } // 将当前state的状态设置为0,就可以进行下次的重用了 *statep = 0 for ; w != 0; w-- { // 释放所有排队的waiter runtime_Semrelease(semap, false) } }
2.2 Done完成一个等待事件
func (wg *WaitGroup) Done() { // 减去一个-1 wg.Add(-1) }
2.3 等待所有操作完成
func (wg *WaitGroup) Wait() { statep, semap := wg.state() if race.Enabled { _ = *statep // trigger nil deref early race.Disable() } for { // 获取state的状态 state := atomic.LoadUint64(statep) v := int32(state >> 32) // 获取高32位的count w := uint32(state) // 获取当前正在Wait的数量 if v == 0 { // 如果当前v ==0就直接return, 表示当前不需要等待 // Counter is 0, no need to wait. if race.Enabled { race.Enable() race.Acquire(unsafe.Pointer(wg)) } return } // 进行低位的waiter计数统计 if atomic.CompareAndSwapUint64(statep, state, state+1) { if race.Enabled && w == 0 { // Wait must be synchronized with the first Add. // Need to model this is as a write to race with the read in Add. // As a consequence, can do the write only for the first waiter, // otherwise concurrent Waits will race with each other. race.Write(unsafe.Pointer(semap)) } // 如果成功则进行排队休眠等待唤醒 runtime_Semacquire(semap) // 如果唤醒后发现state的状态不为0,则证明在唤醒的过程中WaitGroup又被重用,则panic if *statep != 0 { panic("sync: WaitGroup is reused before previous Wait has returned") } if race.Enabled { race.Enable() race.Acquire(unsafe.Pointer(wg)) } return } } }
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/6860/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料