

有些同学可能不知道,struct 中的字段顺序不同,内存占用也有可能会相差很大。比如:
type T1 struct {
a int8
b int64
c int16
}
type T2 struct {
a int8
c int16
b int64
}
在 64 bit 平台上,T1 占用 24 bytes,T2 占用 16 bytes 大小;而在 32 bit 平台上,T1 占用 16 bytes,T2 占用 12 bytes 大小。可见不同的字段顺序,最终决定 struct 的内存大小,所以有时候合理的字段顺序可以减少内存的开销。
这是为什么呢?因为有内存对齐的存在,编译器使用了内存对齐,那么最后的大小结果就会不一样。至于为什么要做对齐,主要考虑下面两个原因:
-
平台(移植性)
不是所有的硬件平台都能够访问任意地址上的任意数据。例如:特定的硬件平台只允许在特定地址获取特定类型的数据,否则会导致异常情况
-
性能
若访问未对齐的内存,将会导致 CPU 进行两次内存访问,并且要花费额外的时钟周期来处理对齐及运算。而本身就对齐的内存仅需要一次访问就可以完成读取动作,这显然高效很多,是标准的空间换时间做法
有的小伙伴可能会认为内存读取,就是一个简单的字节数组摆放。但实际上 CPU 并不会以一个一个字节去读取和写入内存,相反 CPU 读取内存是一块一块读取的,块的大小可以为 2、4、6、8、16 字节等大小,块大小我们称其为内存访问粒度。假设访问粒度为 4,那么 CPU 就会以每 4 个字节大小的访问粒度去读取和写入内存。
在不同平台上的编译器都有自己默认的 “对齐系数”。一般来讲,我们常用的 x86 平台的系数为 4;x8664 平台系数为 8。需要注意的是,除了这个默认的对齐系数外,还有不同数据类型的对齐系数。数据类型的对齐系数在不同平台上可能会不一致。例如,在 x8664 平台上,int64 的对齐系数为 8,而在 x86 平台上其对齐系数就是 4。
还是拿上面的 T1、T2 来说,在 x86_64 平台上,T1 的内存布局为:

T2 的内存布局为(int16 的对齐系数为 2):
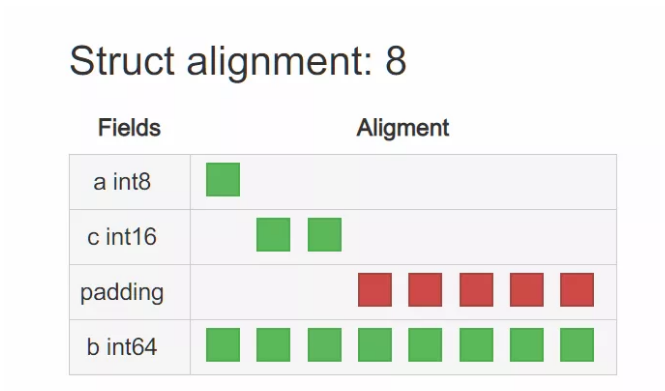
仔细看,T1 存在许多 padding,显然它占据了不少空间。那么也就不难理解,为什么调整结构体内成员变量的字段顺序就能达到缩小结构体占用大小的疑问了,是因为巧妙地减少了 padding 的存在。让它们更 “紧凑” 了。
其实内存对齐除了可以降低内存占用之外,还有一种情况是必须要手动对齐的:在 x86 平台上原子操作 64bit 指针。之所以要强制对齐,是因为在 32bit 平台下进行 64bit 原子操作要求必须 8 字节对齐,否则程序会 panic。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/6991/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料