

个人认为,学习本身并不是一件轻松愉快的事情,寓教于乐是个美好的愿望。想要深刻地领悟,就得付出别人看不见的努力。学习从来都不会是一件轻松的事情,枯燥是正常的。耐住性子,深入研究某个问题,读书、看文章、写博客都可以,浮躁时代做个专注的人!
不多说,贴上本文的目录:

指针类型
在正式介绍 unsafe 包之前,需要着重介绍 Go 语言中的指针类型。
我本科开始学编程的时候,第一门语言就是 C。之后又陆续学过 C++,Java,Python,这些语言都挺强大的,但是没了 C 语言那么“单纯”。直到我开始接触 Go 语言,又找到了那种感觉。Go 语言的作者之一 Ken Thompson 也是 C 语言的作者。所以,Go 可以看作 C 系语言,它的很多特性都和 C 类似,指针就是其中之一。
然而,Go 语言的指针相比 C 的指针有很多限制。这当然是为了安全考虑,要知道像 Java/Python 这些现代语言,生怕程序员出错,哪有什么指针(这里指的是显式的指针)?更别说像 C/C++ 还需要程序员自己清理“垃圾”。所以对于 Go 来说,有指针已经很不错了,仅管它有很多限制。
为什么需要指针类型呢?参考文献 go101.org 里举了这样一个例子:
package main
import "fmt"
func double(x int) {
x += x
}
func main() {
var a = 3
double(a)
fmt.Println(a) // 3
}
非常简单,我想在 double 函数里将 a 翻倍,但是例子中的函数却做不到。为什么?因为 Go 语言的函数传参都是值传递。double 函数里的 x 只是实参 a 的一个拷贝,在函数内部对 x 的操作不能反馈到实参 a。
如果这时,有一个指针就可以解决问题了!这也是我们常用的“伎俩”。
package main
import "fmt"
func double(x *int) {
*x += *x
x = nil
}
func main() {
var a = 3
double(&a)
fmt.Println(a) // 6
p := &a
double(p)
fmt.Println(a, p == nil) // 12 false
}
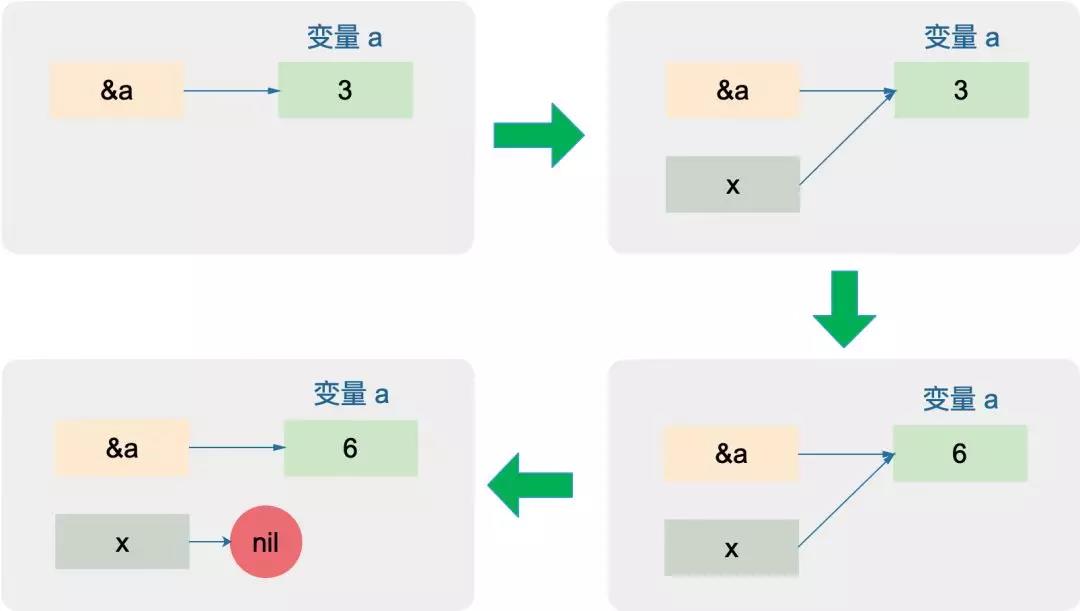
很常规的操作,不用多解释。唯一可能有些疑惑的在这一句:
x = nil
这得稍微思考一下,才能得出这一行代码根本不影响的结论。因为是值传递,所以 x 也只是对 &a 的一个拷贝。
*x += *x
这一句把 x 指向的值(也就是 &a 指向的值,即变量 a)变为原来的 2 倍。但是对 x 本身(一个指针)的操作却不会影响外层的 a,所以x=nil掀不起任何大风大浪。
下面的这张图可以“自证清白”:
然而,相比于 C 语言中指针的灵活,Go 的指针多了一些限制。但这也算是 Go 的成功之处:既可以享受指针带来的便利,又避免了指针的危险性。
限制一:Go的指针不能进行数学运算。
来看一个简单的例子:
a := 5 p := &a p++ p = &a + 3
上面的代码将不能通过编译,会报编译错误:invalid operation,也就是说不能对指针做数学运算。
限制二:不同类型的指针不能相互转换。
例如下面这个简短的例子:
func main() {
a := int(100)
var f *float64
f = &a
}
也会报编译错误:
cannot use &a (type *int) as type *float64 in assignment
关于两个指针能否相互转换,参考资料中 go 101 相关文章里写得非常细,这里我不想展开。个人认为记住这些没有什么意义,有完美主义的同学可以去阅读原文。当然我也有完美主义,但我有时会克制,嘿嘿。
限制三:不同类型的指针不能使用==或!=比较。
只有在两个指针类型相同或者可以相互转换的情况下,才可以对两者进行比较。另外,指针可以通过==和!=直接和nil作比较。
限制四:不同类型的指针变量不能相互赋值。
这一点同限制三。
什么是 unsafe
前面所说的指针是类型安全的,但它有很多限制。Go 还有非类型安全的指针,这就是 unsafe 包提供的 unsafe.Pointer。在某些情况下,它会使代码更高效,当然,也更危险。
unsafe 包用于 Go 编译器,在编译阶段使用。从名字就可以看出来,它是不安全的,官方并不建议使用。我在用 unsafe 包的时候会有一种不舒服的感觉,可能这也是语言设计者的意图吧。
但是高阶的 Gopher,怎么能不会使用 unsafe 包呢?它可以绕过 Go 语言的类型系统,直接操作内存。例如,一般我们不能操作一个结构体的未导出成员,但是通过 unsafe 包就能做到。unsafe 包让我可以直接读写内存,还管你什么导出还是未导出。
为什么有 unsafe
Go 语言类型系统是为了安全和效率设计的,有时,安全会导致效率低下。有了 unsafe 包,高阶的程序员就可以利用它绕过类型系统的低效。因此,它就有了存在的意义,阅读 Go 源码,会发现有大量使用 unsafe 包的例子。
unsafe 实现原理
我们来看源码:
type ArbitraryType int type Pointer *ArbitraryType
从命名来看,Arbitrary是任意的意思,也就是说 Pointer 可以指向任意类型,实际上它类似于 C 语言里的void*。
unsafe 包还有其他三个函数:
func Sizeof(x ArbitraryType) uintptr func Offsetof(x ArbitraryType) uintptr func Alignof(x ArbitraryType) uintptr
Sizeof返回类型 x 所占据的字节数,但不包含 x 所指向的内容的大小。例如,对于一个指针,函数返回的大小为 8 字节(64位机上),一个 slice 的大小则为 slice header 的大小。
Offsetof返回结构体成员在内存中的位置离结构体起始处的字节数,所传参数必须是结构体的成员。
Alignof返回 m,m 是指当类型进行内存对齐时,它分配到的内存地址能整除 m。
注意到以上三个函数返回的结果都是 uintptr 类型,这和 unsafe.Pointer 可以相互转换。三个函数都是在编译期间执行,它们的结果可以直接赋给const型变量。另外,因为三个函数执行的结果和操作系统、编译器相关,所以是不可移植的。
综上所述,unsafe 包提供了 2 点重要的能力:
任何类型的指针和 unsafe.Pointer 可以相互转换。
uintptr 类型和 unsafe.Pointer 可以相互转换。

pointer 不能直接进行数学运算,但可以把它转换成 uintptr,对 uintptr 类型进行数学运算,再转换成 pointer 类型。
// uintptr 是一个整数类型,它足够大,可以存储 type uintptr uintptr
还有一点要注意的是,uintptr 并没有指针的语义,意思就是 uintptr 所指向的对象会被 gc 无情地回收。而 unsafe.Pointer 有指针语义,可以保护它所指向的对象在“有用”的时候不会被垃圾回收。
unsafe 包中的几个函数都是在编译期间执行完毕,毕竟,编译器对内存分配这些操作“了然于胸”。在/usr/local/go/src/cmd/compile/internal/gc/unsafe.go路径下,可以看到编译期间 Go 对 unsafe 包中函数的处理。
更深层的原理需要去研究编译器的源码,这里就不去深究了。我们重点关注它的用法,接着往下看。
unsafe 如何使用
获取 slice 长度
slice header 的结构体定义:
// runtime/slice.gotype slice struct {array unsafe.Pointer // 元素指针len int // 长度cap int // 容量}
调用 make 函数新建一个 slice,底层调用的是 makeslice 函数,返回的是 slice 结构体:
func makeslice(et *_type, len, cap int) slice
因此我们可以通过 unsafe.Pointer 和 uintptr 进行转换,得到 slice 的字段值。
func main() {
s := make([]int, 9, 20)
var Len = *(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + uintptr(8)))
fmt.Println(Len, len(s)) // 9 9
var Cap = *(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + uintptr(16)))
fmt.Println(Cap, cap(s)) // 20 20
}
Len,cap 的转换流程如下:
Len: &s => pointer => uintptr => pointer => *int => int Cap: &s => pointer => uintptr => pointer => *int => int
获取 map 长度
再来看一下上篇文章我们讲到的 map:
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
和 slice 不同的是,makemap 函数返回的是 hmap 的指针,注意是指针:
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap
我们依然能通过 unsafe.Pointer 和 uintptr 进行转换,得到 hamp 字段的值,只不过,现在 count 变成二级指针了:
func main() {
mp := make(map[string]int)
mp["qcrao"] = 100
mp["stefno"] = 18
count := **(**int)(unsafe.Pointer(&mp))
fmt.Println(count, len(mp)) // 2 2
}
count 的转换过程:
&mp => pointer => **int => int
map 源码中的应用
在 map 源码中,mapaccess1、mapassign、mapdelete 函数中,需要定位 key 的位置,会先对 key 做哈希运算。
例如:
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))
h.buckets是一个unsafe.Pointer,将它转换成uintptr,然后加上(hash&m)*uintptr(t.bucketsize),二者相加的结果再次转换成unsafe.Pointer,最后,转换成bmap指针,得到 key 所落入的 bucket 位置。如果不熟悉这个公式,可以看看上一篇文章,浅显易懂。
上面举的例子相对简单,来看一个关于赋值的更难一点的例子:
// store new key/value at insert position
if t.indirectkey {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectvalue {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(val) = vmem
}
typedmemmove(t.key, insertk, key)
这段代码是在找到了 key 要插入的位置后,进行“赋值”操作。insertk 和 val 分别表示 key 和 value 所要“放置”的地址。如果 t.indirectkey 为真,说明 bucket 中存储的是 key 的指针,因此需要将 insertk 看成指针的指针,这样才能将 bucket 中的相应位置的值设置成指向真实 key 的地址值,也就是说 key 存放的是指针。
下面这张图展示了设置 key 的全部操作:
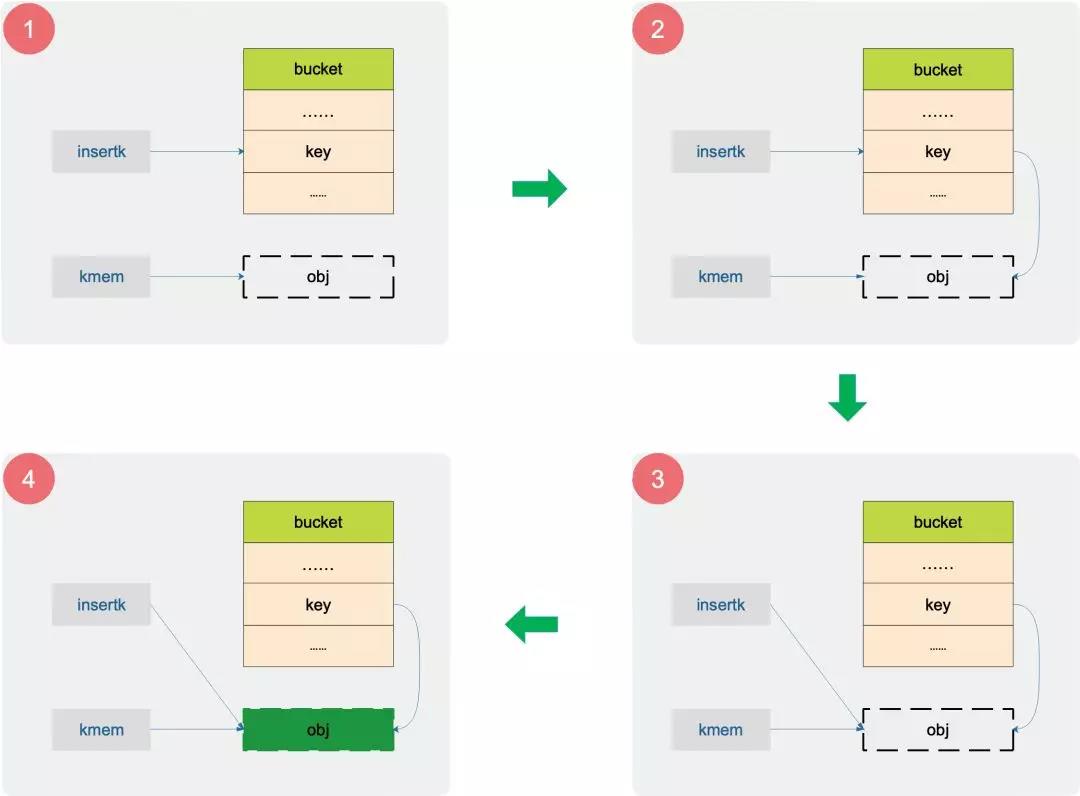
obj 是真实的 key 存放的地方。第 4 号图,obj 表示执行完typedmemmove函数后,被成功赋值。
Offsetof 获取成员偏移量
对于一个结构体,通过 offset 函数可以获取结构体成员的偏移量,进而获取成员的地址,读写该地址的内存,就可以达到改变成员值的目的。
这里有一个内存分配相关的事实:结构体会被分配一块连续的内存,结构体的地址也代表了第一个成员的地址。
我们来看一个例子:
package main
import (
"fmt"
"unsafe"
)
type Programmer struct {
name string
language string
}
func main() {
p := Programmer{"stefno", "go"}
fmt.Println(p)
name := (*string)(unsafe.Pointer(&p))
*name = "qcrao"
lang := (*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&p)) + unsafe.Offsetof(p.language)))
*lang = "Golang"
fmt.Println(p)
}
运行代码,输出:
{stefno go}
{qcrao Golang}
name 是结构体的第一个成员,因此可以直接将 &p 解析成 *string。这一点,在前面获取 map 的 count 成员时,用的是同样的原理。
对于结构体的私有成员,现在有办法可以通过 unsafe.Pointer 改变它的值了。
我把 Programmer 结构体升级,多加一个字段:
type Programmer struct {
name string
age int
language string
}
并且放在其他包,这样在 main 函数中,它的三个字段都是私有成员变量,不能直接修改。但我通过 unsafe.Sizeof() 函数可以获取成员大小,进而计算出成员的地址,直接修改内存。
func main() {
p := Programmer{"stefno", 18, "go"}
fmt.Println(p)
lang := (*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&p)) + unsafe.Sizeof(int(0)) + unsafe.Sizeof(string(""))))
*lang = "Golang"
fmt.Println(p)
}
输出:
{stefno 18 go}
{stefno 18 Golang}
string 和 slice 的相互转换
这是一个非常精典的例子。实现字符串和 bytes 切片之间的转换,要求是zero-copy。想一下,一般的做法,都需要遍历字符串或 bytes 切片,再挨个赋值。
完成这个任务,我们需要了解 slice 和 string 的底层数据结构:
type StringHeader struct {
Data uintptr
Len int
}
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
上面是反射包下的结构体,路径:src/reflect/value.go。只需要共享底层 []byte 数组就可以实现zero-copy
func string2bytes(s string) []byte {
stringHeader := (*reflect.StringHeader)(unsafe.Pointer(&s))
bh := reflect.SliceHeader{
Data: stringHeader.Data,
Len: stringHeader.Len,
Cap: stringHeader.Len,
}
return *(*[]byte)(unsafe.Pointer(&bh))
}
func bytes2string(b []byte) string{
sliceHeader := (*reflect.SliceHeader)(unsafe.Pointer(&b))
sh := reflect.StringHeader{
Data: sliceHeader.Data,
Len: sliceHeader.Len,
}
return *(*string)(unsafe.Pointer(&sh))
}
代码比较简单,不作详细解释。通过构造 slice header 和 string header,来完成 string 和 byte slice 之间的转换。
总结
unsafe 包绕过了 Go 的类型系统,达到直接操作内存的目的,使用它有一定的风险性。但是在某些场景下,使用 unsafe 包提供的函数会提升代码的效率,Go 源码中也是大量使用 unsafe 包。
unsafe 包定义了 Pointer 和三个函数:
type ArbitraryType int type Pointer *ArbitraryType func Sizeof(x ArbitraryType) uintptr func Offsetof(x ArbitraryType) uintptr func Alignof(x ArbitraryType) uintptr
通过三个函数可以获取变量的大小、偏移、对齐等信息。
uintptr 可以和 unsafe.Pointer 进行相互转换,uintptr 可以进行数学运算。这样,通过 uintptr 和 unsafe.Pointer 的结合就解决了 Go 指针不能进行数学运算的限制。
通过 unsafe 相关函数,可以获取结构体私有成员的地址,进而对其做进一步的读写操作,突破 Go 的类型安全限制。关于 unsafe 包,我们更多关注它的用法。
顺便说一句,unsafe 包用多了之后,也不觉得它的名字有多么地不“美观”了。相反,因为使用了官方并不提倡的东西,反而觉得有点酷炫。这就是叛逆的感觉吧。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/7107/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料