

在我们最开始做一些简单的学习项目的时候,我们会遇到一些需要配置的东西,比如数据库连接池大小,用户的黑名单等等,我们都把这些东西写死在代码里面,比如if(userId == 123){do something},这种代码在项目里随处可见。后来参加工作了,发现这种写法并没有将配置很好的统一管理起来,配置地方随处可见,并且无法根据代码环境去进行调整,比如线上和线下都只能使用同一个配置,虽然可以通过if,else的方式,但是这个非常麻烦,所以在工作就开始使用xml,yaml等方式在文件里面进行配置,在不同的运行环境读取不同的配置。这种方式基本满足了大部分的需求,但是后面遇到了一个需要动态去修改这些配置的情况,如果通过文件的方式我们就只能修改文件然后重新上线服务,这样是非常麻烦的,所以就诞生了配置中心。
我们在这里可以想想,如果你要实现配置中心,应该具备哪些功能呢?我这里列举一些:
- 可以动态的修改配置。
- 配置中心挂了也不影响配置的使用。
- 配置是可以多个服务共享的。
- 支持权限管理,只有授予权限的人才能查看和修改配置
- 配置可以回滚,当我们遇到配置出现问题的时候可以像回滚服务一样回滚配置。
- 灰度发布,可以让某几台机器先使用这个配置如果没有问题,在进行全量。
- 配置中心自身的QPS能保证足够,如果是一个公司的基础服务的话是需要保证这个的
其实在开源的项目中有挺多配置中心的开源的比如spring cloud config, Apollo等等,其中Apollo是携程开源的配置中心,在业界也是非常出名,我们这边文章主要还是介绍Nacos的配置中心,当然有兴趣的同学可以下来自行查看其他注册中心相关介绍。
基本概念
同样的我们首先也先介绍一下和注册中心相关的一些基本名词概念:
-
命名空间(namespace):和注册中心一样,命名空间属于Nacos顶层的结构,用于进行租户级别的隔离,我们最常用的就是不同环境比如测试环境,线上环境进行隔离。
-
配置管理:系统配置的编辑、存储、分发、变更管理、历史版本管理、变更审计等所有与配置相关的活动。
-
配置项:一个具体的可配置的参数与其值域,通常以 param-key=param-value 的形式存在。例如我们常配置系统的日志输出级别(logLevel=INFO|WARN|ERROR) 就是一个配置项。
-
配置集: 一组相关或者不相关的配置项的集合称为配置集。在系统中,一个配置文件通常就是一个配置集,包含了系统各个方面的配置。例如,一个配置集可能包含了数据源、线程池、日志级别等配置项。
-
配置集 ID : Nacos 中的某个配置集的 ID。配置集 ID 是组织划分配置的维度之一。
-
配置分组:Nacos 中的一组配置集,是组织配置的维度之一。
-
配置快照:Nacos 的客户端 SDK 会在本地生成配置的快照。当客户端无法连接到 Nacos Server 时,可以使用配置快照显示系统的整体容灾能力。配置快照类似于 Git 中的本地 commit,也类似于缓存,会在适当的时机更新,但是并没有缓存过期(expiration)的概念。
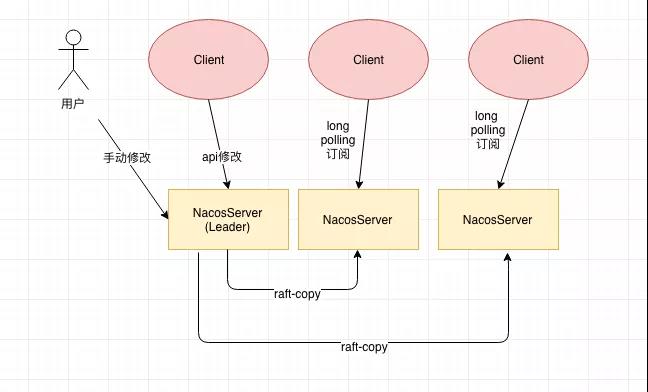
配置中心的架构图如下:
-
用户可以在后台界面进行添加或者修改配置,也可以通过client-api进行修改配置
-
所有修改的数据通过raft首先在Leader修改生效,然后同步至其他副本。
-
如果用户想订阅该配置通过long polling的方式进行订阅。
一致性存储
配置中心最为关键的就是如何去做好存储,一般我们存储就两种方式, 要么全内存存储,能保证性能非常高,但是维护不同机器内存一致性复杂度比较高,还有一种就是使用数据库,内存里面不维护任何状态,每一台机器都可以进行写入操作,这个复杂度比较低,不需要考虑一致性的问题,但是由于所有的读写都会走数据库所以性能就不能保证。在Nacos中对这两种存储方式做了一些改进,实现了既保证了性能又保证了复杂度一致性。
在Nacos1.3之后提供了mysql 和 raft + derby两种存储方式,接下来介绍一一介绍一下这两种存储方式。
mysql + 异步全量通知
nacos最开始提供的就是mysql的方式,所有机器都可以进行读写,没有主备之分,如下图所示:
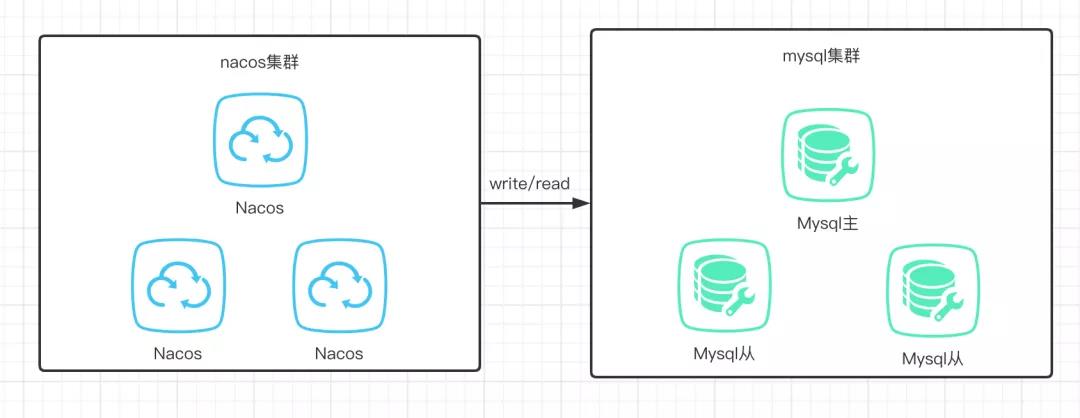
如果只是使用mysql,有同学会提出问题,只使用mysql如何才能保证数据库性能不会成为瓶颈呢?最简单的方法就是使用高配置的Mysql,用钱给我干上去,很明显这个不是很靠谱,只适用于土豪玩家。那么怎么去做这种优化呢?一般做业务的同学通常会在Mysql前面放一层缓存层,比如redis,memcached等等。
在Nacos中同样的也使用了缓存这个概念帮助我们缓解数据库压力。但是和普通的缓存稍微有点不同:
但是对于具体存储的值我们不会直接放在内存,而是存储到了本地磁盘,这么做的好处是因为我们的config所配置的值我们不能保证他的大小,如果每个config的值都很大,那么我们的内存必然会不足,这个时候Nacos和Apollo 两个开源中间件给出两种解法:
-
Apollo的做法是使用一个guavaCache,使用淘汰策略将不经常使用的进行淘汰。
-
Nacos的做法是全量缓存元数据,具体的值存储到磁盘空间,采用分离存储的方式,nacos采用这种方法,如果只是访问元数据那么全量内存即可,不会像Apollo一样可能会遇到淘汰的原因,访问数据库。
Dump
Nacos使用的是全量缓存元数据到内存,具体的值存储到磁盘空间,但是会存在一个问题,那就是当一台机器的数据发生变更,其他机器的内存怎么变更呢?这就需要我们的全量异步通知,在每一次修改数据的时候都会发送一个ConfigDataChage事件,然后本机接受并进行处理,然后发送这个变更消息到其他的所有机器上。
其他机器收到这个变更通知之后,会进行一次dump操作:
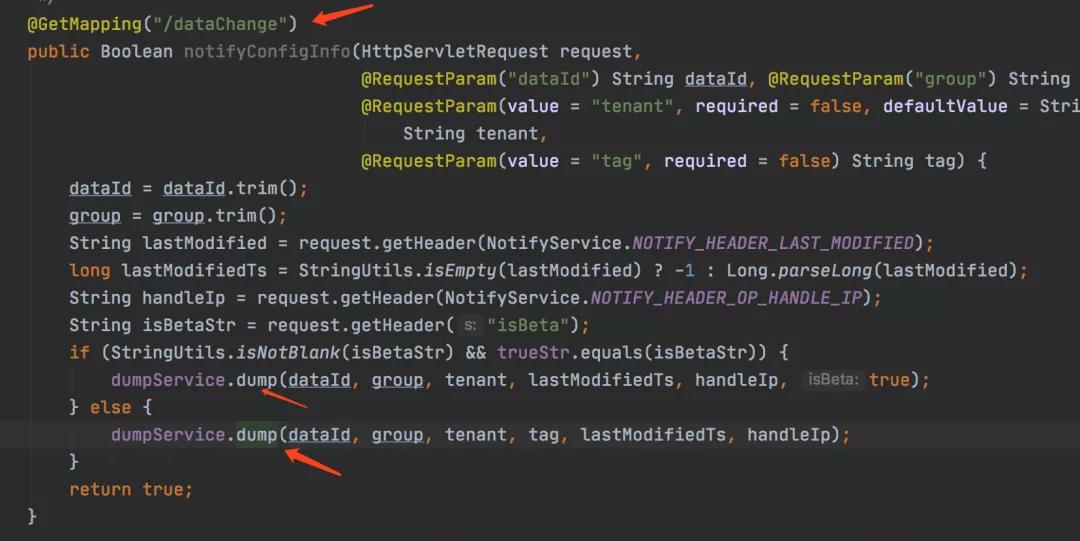
会先查询元数据中的MD5,MD5其实也是根据我们配置中的值算出来的,所以能进行快速判断这一次时候发生了值的变更,如果发生变更,我们就将这个值存储到磁盘上。
如果我们这个机器是新启动的,这个时候其实就不会存在任何缓存以及dump文件,那么DumpService会遍历数据库的所有数据,全量的都缓存到机器上,以便我们使用。
raft + derby
Nacos在1.3.0之后提供了一个新的存储模式,那就是使用raft协议保证数据一致性,使用apache derby进行内嵌的数据存储。提供这种方式的目的是减少用户维护mysql数据库集群的成本,并且简化了集群部署的成本,部署Nacos的时候直接打包Nacos镜像就好,不需要再单独部署一套数据库。
在Nacos中使用的是sofa-jraft,这个是蚂蚁开源的一个java版本高性能的raft实现,不熟悉raft的同学可以阅读以下raft的论文,了解过raft的同学应该都知道raft非常强化Leader的概念:
-
系统中必须存在且同一时刻只能有一个 leader,只有 leader 可以接受 clients 发过来的请求
-
Leader 负责主动与所有 followers 通信,负责将’提案’发送给所有 followers,同时收集多数派的 followers 应答
-
Leader 还需向所有 followers 主动发送心跳维持领导地位

我们发现所有的事情都和leader相关,那么我们的性能必定被限制在leader上面,所以在Nacos中选择了对raft本身有大量优化的sofa-jraft,在sofa-jraft中做了如下的优化:
-
批量化:批量化操作是很多系统的一个优化策略,在jraft中同样的也采用了批量化操作,通过disruptor 的 MPSC 模型批量消费,实现了下面的一些批量操作,提升了很多的性能:
-
批量提交 task
-
批量网络发送
-
本地 IO batch 写入
-
批量应用到状态机
-
pipeline复制: pipeline是一种管道技术,帮助我们不再和以前请求-响应模型一样,他可以持续往管道中放入请求,过程中而不需要等待请求的回复,在最后再一并读取结果即可。在jraft中开启pipeline性能会提升30%。
-
并行化:leader持久化log和发送Log到follower是并行的,发送到不同的follower也是并行的。
-
线性读:在raft协议中,读请求会按照 Log 处理,通过 Log 复制和状态机执行来得到读结果,然后再把结果返回给 Client。这种办法的缺点是需要 Log 存储、复制,这样会带来刷盘开销、存储开销、网络开销,因此在读操作很多的场景下对性能影响很大。在Sofajrat中进行了ReadIndex,Lease Read优化,让所有的读都可以在本地执行,这个对性能的提升特别大。
Apache Derby也是一个Java编写的轻量级数据库,Nacos通过这样的设计其实是构建了一个轻量级的分布式数据库,在每一台的机器上都会有一个保存数据的数据库,然后通过raft协议保证所有机器数据的一致性。
内嵌数据库的方式并不比Mysql的方式更好,在性能上Mysql那种方式因为存了很多缓存,并且content也保存到磁盘上,读取的时候基本不会走库,所以Mysql的方式其实更好,但是内嵌数据库的方式在运维部署的方式上是非常占优的。这里如何取舍需要用户自己进行一个选择
客户端订阅变更
我们在上一节说到Nacos注册中心中的订阅是通过udp广播+定时轮训来获取到,而在配置中心中采用的是长轮训的方式进行订阅变更,为什么这两个实现订阅会采用不同的方式来实现呢?我们注册中心中所保存的数据都是小数据比如节点的Ip,端口等信息,但是我们在配置中心中你不能控制配置的大小,比如一个服务订阅了100个配置,每个配置的数据大小是1M,如果按照定时轮训的做法每次会拉100M的数据,显然是不靠谱的,所以这里采用了长轮训的方式,具体长轮训的方式如下:
-
Step1: 客户端定时发出长轮训的请求,超时时间默认为30s。发出的请求是自己所有订阅配置内容的MD5,这里我们不会把整个内容当成请求发出,不然又会出现上面所说的每次都会发出很多的数据。
-
Step2: 服务端收到这个请求后利用Servlet3.0的特性,开启了异步AsyncContext。
-
Step3: 服务端存储这个AsyncContext,等待配置的变更,数据的变更会通过DataChangeEvent事件中进行触发,然后判断之前请求中的md5和新更新的md5是否一样,如果一致将变更信息写入到AsyncContext的response中。
-
Ste4: 如果超时还没有到,那么代表本次没有配置进行更新,又会回到Step1。
通过这样的方式,我们每次请求量都会很少,只有在数据真正更新的时候才会将真正的数据返回给我们。
配置灰度
我们可能有这样的一个需求,我们需要验证某个配置是否对业务上有影响,通常的配置中心都是直接修改,所有机器全量都会被更新,如果这个配置出现问题,那么就会全量的出现故障。在Nacos中提供了一个灰度的功能,我们可以将某个配置只给某一些机器使用,这样就可以完成一些小流量验证。
在Nacos中灰度发布也叫做beta发布,如下图所示:
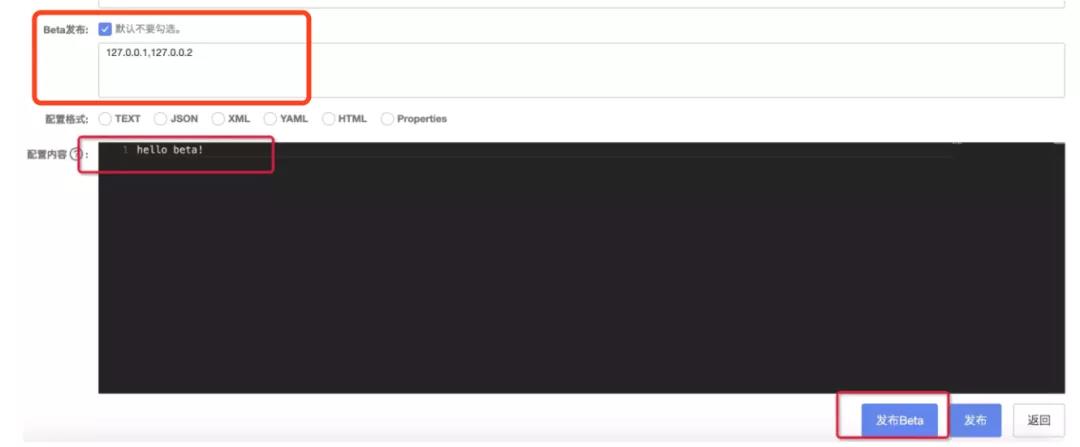
在nacos中的具体实现的是用一个单独的表去保存beta相关的信息:
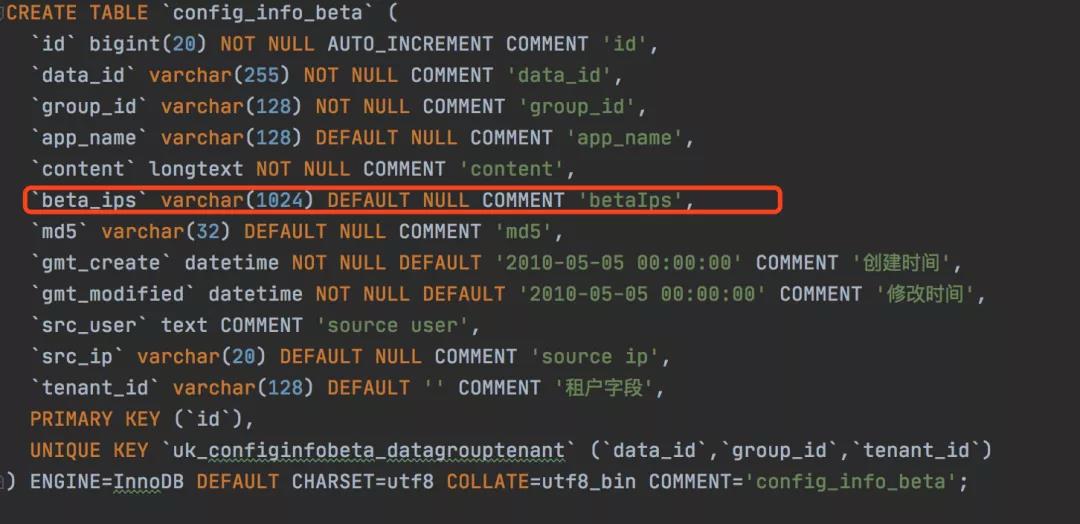
用beta_ips字段保存了我们需要灰度的机器,在客户端订阅进行长轮训的时候,也会过滤是否是灰度的机器,如果是才会进行更新,下面是LongPollingService的代码:
历史回滚
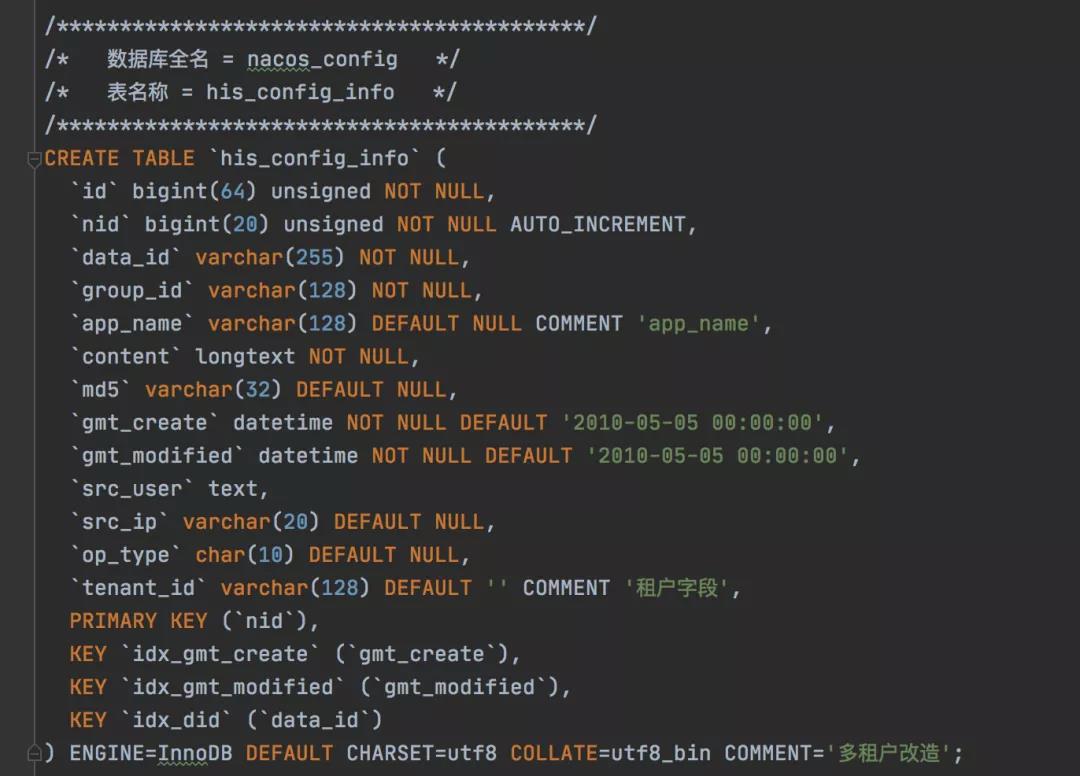
在Nacos中也提供了历史版本,类似git的commit一样,只要你有commitid你就能回滚到对应的版本,在Nacos用了一个history_config表来进行保存,我们可以通过这个表获取我们某个配置的所有历史,以此来进行回滚。
总结
在Nacos中还有很多其他的功能,比如权限管理等等,在这里我就不一一介绍了。在Nacos的配置中心中设计得最为巧妙的也就是存储和订阅了,存储Nacos提供了两种模式,一个是Mysql+缓存+本次磁盘的方式,还有一种是通过raft+derby的方式,都有自己的优劣点。订阅的话Nacos采用的和注册中心完全不一样的方式,通过长轮训很好的解决了更新的实时通知,并且不需要大量请求资源。如果大家对Nacos感兴趣,建议还是可以阅读下Nacos的代码。
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/7460/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料