


Hadoop作为目前大数据处理的主流平台框架,MapReduce和HDFS是其主要的组成组件。使用MapReduce可以顺利完成大数据分析任务,其经典的应用场景就是使用Java语言编写MapReduce任务。除此之外,MapReduce还兼容了Streaming方式,为其他语言提供使用MapReduce完成大数据分析的接口。本文章主要介绍如何使用Python语言来编写MapReduce程序进行模拟分布式计算,对于不擅长Java语言但熟悉使Python语言(大数据分析必用语言)的人来说是福音。
模拟分布式计算
作为分布式计算的入门例子 wordCount ,是统计大文件中每个单词的个数。任务非常简单,如果这个文件的大小超过了单机的内存,处理起来很困难,我们需要借助集群来完成这个统计任务。下图是本文程序的流程:
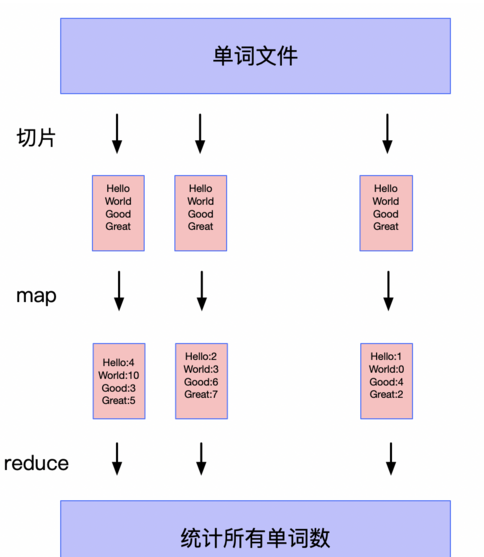
首先导入使用的包
from functools import reduce import numpy as np from typing import List, Dict from collections import defaultdict
首先我们模拟生成单词文件,每个单词假设3个字母。输出文件名称为 words.txt .
def generate_random_words_file(sample_num: int = 100):
"""
生成随机字母的样本文件
:param sample_num: 样本数
"""
# 97-122 ==> a-z
with open("words.txt", "w") as fd:
random_words = np.random.randint(97, 110, (3, sample_num))
for row in range(sample_num):
words = "".join([chr(each) for each in random_words[:, row]])
fd.write(words + "\n")
接下来读取单词文件,然后进行分块。我们就直接分块读取,默认块大小为10个单词。
def read_file_by_chunk(lines: int = 10) -> List[List[str]]:
"""
分块读取文件
:param lines: 行数
"""
res = []
with open("words.txt") as fd:
tmp_chunk = []
for idx, line in enumerate(fd.readlines(), start=1):
tmp_chunk.append(line.strip())
if idx % lines == 0:
res.append(tmp_chunk)
tmp_chunk = []
return res
对大文件进行分块以后,接下来对每个块文件进行map映射,统计出每个块的单词数量,返回字典数据,映射函数作为map的参数。
def map_count(data: List[str]) -> Dict[str, int]:
"""
统计单词个数
"""
word_count = defaultdict(int)
for item in data:
word_count[item] += 1
return word_count
有了映射函数,接下来写归纳操作。归纳操作的函数只需要完成两个map的计算,这个函数将作为reduce的参数,将所有map结果进行归纳。
def reduce_count(data1: Dict[str, int], data2: Dict[str, int]) -> Dict[str, int]:
"""
合并两个map
"""
for k, v in data2.items():
data1[k] = data1[k] + data2[k]
return data1
定义完map和reduce以后接下来完成主函数.模拟生成10万个单词的文件,每个数据块100个单词,通过MapReduce计算以后,输出词频最高的前10个单词。
if __name__ == '__main__':
generate_random_words_file(sample_num=100000)
data_chunk = read_file_by_chunk(lines=100) # 数据切片
map_res = map(map_count, data_chunk) # map
reduce_res = reduce(reduce_count, map_res) # reduce
reduce_res = sorted(reduce_res.items(), key=lambda x: x[1], reverse=True) # 排序
for each in reduce_res[:10]:
print(each)
输出结果:
('ckk', 72)
('cak', 72)
('lae', 72)
('mah', 68)
('abe', 67)
('gcg', 67)
('jlg', 66)
('hmf', 66)
('bmd', 65)
('jem', 64)
总结
本文模拟了MapReduce分布式计算过程。真实的分布式是将每个数据块分到不同的节点进行计算,然后再将计算的结果再归纳到同一个节点输出。大规模数据正式通过这样的MapReduce过程,由集群完成计算。技术变更很快,MapReduce框架早已被取代,但是分布式计算的思想一直被继承下来。想要获取更多Python教程欢迎持续关注编程学习网
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://phpxs.com/post/8521/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料