

摘要:一般来说的全文搜索服务,大体是基于字和关键词的,基于语句的全文搜索服务是一个有意思的课题。以文字为最小节点,以语句为分枝,建立语义树,提供基于语义树的全文检索服务。通过对语句进行语义特征编码,并结合数据库,来实现基于语义树的全文索引和搜索服务。

1 引言
搜索引擎是信息时代的基础服务之一,搜索引擎服务的核心为全文检索。常用的全文检索,一般以关键词的检索为主,对于不同的语言需要不同的处理方法。
对于常规的全文搜索来说,基本的功能就是分词加上倒排序表。
全 文检索对于分词技术和字典的依赖,使得全文搜索实施的难度加大。对于不同语种需要不同的字典和分词技术,对于同一语种不同专业的文档也需要不同的分词技术 和字典,不同字典和分词技术也影响了系统的通用性。搜索引擎的服务随着信息量的增大,存在索引时间长,搜索速度慢等问题。
本文探讨以语句为单位,构建基于语句的搜索引擎,绘制文字的语义树,搜索按自然语句的形式搜索,并提供自然语句或者词汇后续的文字,以此进一步的搜索。
2 全文索引技术综述
全文索引主要解决文字信息的搜索问题,结构化信息的检索依托数据库的索引技术实现,对于文档类的信息,就需要转换为结构化信息的全文搜索来完成。
为了提高索引的效率,应用了基于字典的关键词索引,引进分词技术,同义词和停止词技术,这样做主要目的是减少索引的个数,通过词的引入减少倒排序的存储来实现效率的提升。关键词的搜索,没有考虑字词之间的关系,没有语义方面的考量。
全文索引随着数据量的增大,会出现效率低下的问题,为了提高效率,会修改配置,降低索引的维度和次数来提高,例如给定关键词条索引,自动分析文档编写摘要,用摘要索引来代替全文索引。为了保证搜索匹配的效率, 有效的索引方法是十分关键的, 特别是需要考虑语义匹配的时候, 索引就会变得更为复杂[1]。
如何通过语句来进行文档和语句的关系索引,直接用自然语句进行搜索,是本文研究的课题。
3 语句索引和检索
有了基于字词的全文索引,自然有基于语句的全文索引。由于行文规则的确定,语句的数量是一个可测的集合,远小于基于字词组合的集合维度,数量级小,粒度大,索引的存储量相对小。
语句索引技术需要解决的核心问题主要有:
1、语句索引问题。
2、查询语句的匹配问题。
语句的索引主要通过语义树来实现,对语句进行语义特征编码,通过链接表的形式来存储。语句的匹配问题有很多方法,选择实用便捷的方法是系统主要考量的。
3.1语义特征编码
语句的索引问题是语句索引和搜索的核心。利用语义特征编码解决语句的统一编码问题,不再基于自然语句做字符串的匹配,解决了语句匹配的问题。通过特征编码实现语句的快速查找,组织语义树实现了文章信息的自然索引,可以顺着文字的脉络进行搜索。
语 义特征编码定义:实现语句中的文字统一映射到一个线性空间,文字在语句中的特征信息编码主要由该文字本身和该文字在语句中之前的文字决定的。该特征编码决 定了文字和语句中之前文字,关联文字顺序的信息。通过该编码可以直接查询到该语句片段。下面介绍采用线性的维度来构建语义树。
语句中的文字通过增量哈希算法映射到统一的线性空间,形成特征标识,最长可以为128bit,一般64bit即可,空间容量为2的128次方或2的64次方。
语义特征编码采用哈希算法实现,具体的实现方法如下:
1、对于语句排列定义如下:
i. 最小文字单元为w;
ii. W i 表示句中第i个最小文字单元;
2、特征序列编码如下:
i. T i 表示W i 的特征编码
3、公式如下:
T i =Tencode(T i-1 +w i );当i=0时为T 0 =Tencode(w 0 )
4、Tencode为特征编码公式。一般为hash算法,然后取一定的位数。
特征编码的意义主要是利用哈希算法,构建句中文字最小单元的特征编码,特征编码主要指的是语句截至到该最小单元的编码。
统一的编码格式映射到线性的空间,方便检索。32位的编码空间有一定的碰撞几率,64位几乎没有碰撞。
利用语义特征编码保存一段有序的文字片段,存储和检索均采用该特征编码。
3.2 语义树构建
语义树指的是用树形图来表示语句,树的节点为最小文字单元,最小文字单元一般来说指的是文字词汇,中文的为单个文字,英文的为词汇。通俗来讲就是文字的树。
建立语义树,先给出语义三元组的定义:
{T i ,W i ,T i-1 };当i=0时,为{T 0 ,W 0 ,0}或者{T 0 ,W 0 }。
具体含义为:语义特征信息编码,文字,前语义特征信息编码。
语义三元组构建语义树。
语义三元组包含了最小文字单元的上下连接关系。
用链式存储的方式来构建语义树。三元组存储到数据库中,文字的特征信息为唯一索引,为了查找方便,在前特征信息编码建立索引,方便语义的检索,
语义树的作用主要有:
1、直观的描述语句中文字和文字之间的连接;
2、给定语句的前文,可以方便的查找后续的文字;
3、语义匹配。进行语句的匹配,匹配检索的语句和存储的语句。
3.3 语义树存储
通过语义树的构建提供一种快速匹配语义的方法,根据语义和文档的关系,查找到相关的文档信息。语义树的存储主要包括:语义树、语义树和文档的关系和文档。
语义树的节点分为三类节点:位于句首的节点,其前节点或者父系节点为空;句中节点;句尾节点。由于语言的多样性,有的节点可能同时具有三类中的一项或者多项。
在实验系统中,“生物实验室”的语义树如下:

图 1 “生物实验室”语义树
图1为“生物实验室”在系统中的语义树存储的展示图,展示以“生物实验室”为根节点的语义树,每个文字均为一个节点,有的节点关系到文档的记录,有的仅仅是一个承接上下文的链接节点,或者说给节点没有文档标识。
点击有文档标识的节点既可以展示相关文档。
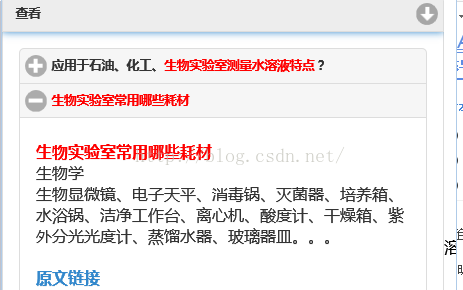
图 2 文档信息显示
“李白的诗”和“杜甫的诗”的语义树如下:
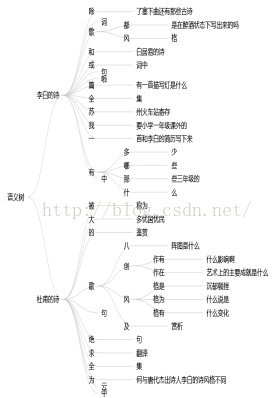
图 3 “李白的诗”和“杜甫的诗”语义树
图中展示的联系在一起的文字之间也是有连接符的,这样的处理仅仅表示文字之间没有分支。
语义树展示的是字与字的关系,在自然语句中的联系形式。通过语义三元组的存储,实现了自然语言的语义树。
语义树的存储是通过数据库来实现的。语义树存储四个字段:文字特征编码,最小文字单元,前文字特征编码,是否为句尾。一般来说,在文字特征编码上建立唯一索引;前文字特征编码建立索引,这样方便语义树的查询。
为了实现全文搜索,还需要存储语句和文档的关系表和文档。文档和语句的关系表主要存储两个字段:语句尾部特征编码和文档识别Id,并以语句特征标识为主键建立数据库表。
如果需要存储文档,则建立文档存储表,一般在文档ID上建立索引即可。
3.4 语义搜索
文献[2]提出语义相似度计算,认为语义相似度计算时自然语言处理关键技术之一。
要进行语义搜索首先需要进行语句的适配,考虑到搜索的效率,采用最大前缀匹配方法匹配语句,即在存储的语句中找到最大前缀的匹配,这样有利于简化搜索,提高搜索的效率。
搜索主要按以下步骤的来完成:对搜索的语句进行语义特征编码,找到最大的匹配,然后根据最大的匹配找到适合的语句,最后根据该语句找到相关的文档。
语义搜索简化搜索的方式,主要进行前缀的最大化匹配,主要基于的前提是随着语料的增多,可以满足查询;还在于按自然语言的习惯搜索,而不是断章取义的方式来进行。这样简化搜索的空间,有利于快速搜索。
语义搜索的流程如下:
1、搜索语句的特征编码,形成序列集合{T i ;i=0,1,2…n-1};
2、从T n-1 开始搜索,如果有则找到,否则搜索T n-2 ;
3、假定找到T k ,如果T k 有文档标识,则利用特征编码找文档;
4、否者沿着T kc 查找该特征序列所在分支的文档标识。即查找前特征编码为T k 的特征编码,一直递归找到位置。
3.5 系统实现与测试
开发语句的搜索服务系统,采用数据库存储,主要包括:语义树的存储,语句和文档的关系存储和文档的存储。实现基于语义树的查询和联想功能。
以百度知道的数据为例,27901630的标题索引,全文字系列,采用标点符号分割,非空格分词的语言空格作为断句符号。语义树单元存储条目为245009346,平均每标题占用8.78个。
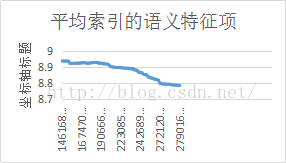
图 4 文档数和语义特征存储平均值
4结束语
采 用对文本信息进行特征序列的编码,形成相关的语义树,实质上提供了一种基于语句的全文搜索服务,一种基于语义树的索引方法和系统,一种不再依赖于分词的全 文索引引擎,一种适合不同语种的全文搜索引擎,具有存储空间小,索引速度和查询速度快等特点。系统已经实现通过语义树的索引全文,并提供相关的服务。
参考文献
[1] 关佶红,许红儒,周水.Web 服务搜索技术综述[J].计算机科学与探索, 2010(5)
[2] 张亮,尹存燕,陈家骏.基于语义树的中文词语相似度计算与分析[J].中文信息学报, 2010, 24(6)
[3] 王青.基于语义网的语义搜索服务交互模式研究与应用[D].北京:北京邮电大学硕士论文, 2011
来自:http://www.techug.com/full-text-search-and-full-sentences-search
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/5547/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料