

只用了不到4小时。
AlphaZero在去年底通过自我对弈,就完爆上一代围棋冠军程序AlphaGo,且没有采用任何的人类经验作训练数据(至少DeepMind坚持这么认为,嗯)。
昨天,GitHub有位大神@Zeta36用Keras造出来了国际象棋版本的AlphaZero,具体操作指南如下。
项目介绍
该项目用到的资源主要有:
去年10月19号DeepMind发表的论文《不靠人类经验知识,也能学会围棋游戏》 基于DeepMind的想法,GitHub用户@mokemokechicken所做的Reversi开发,具体前往https://github.com/mokemokechicken/reversi-alpha-zero DeepMind刚发布的AlphaZero,从零开始掌握国际象棋:https://arxiv.org/pdf/1712.01815.pdf。 之前量子位也报道过,AlphaZero仅用了4小时(30万步)就击败了国际象棋冠军程序Stockfish。是不是赛雷(´・Д・)」
更多细节去wiki看呗。
笔记
我是这个信息库(repositories,也简称repo)的创造者。
这个repo,由我和其他几个小伙伴一起维护,并会尽我们所能做到最好。
repo地址:https://github.com/Zeta36/chess-alpha-zero/graphs/contributors
不过,我们发现让机器自己对弈,要烧很多钱。尽管监督学习的效果很好,但我们从来没有尝试过自我对弈。
在这里呢,我还是想提下,我们已经转移到一个新的repo,采用大多数人更习惯的AZ分布式版本的国际象棋(MCTS in C ++):https://github.com/glinscott/leela-chess
现在,项目差不多就要完成啦。
每个人都可以通过执行预编译的Windows(或Linux)应用程序来参与。这个项目呢,我们赶脚自己做得还是不错的。另外,我也很确定,在短时的分布式合作时间内,我们可以模拟出DeepMind结果。
所以呢,如果你希望能看到跑着神经网络的UCI引擎打败国际象棋冠军程序Stockfish,那我建议你去看看介个repo,然后肯定能增强你家电脑的能力。
使用环境
Python 3.6.3
tensorflow-gpu: 1.3.0
Keras: 2.0.8
最新结果 (在@Akababa用户的大量修改贡献后获得的)
在约10万次比赛中使用监督式学习,我训练了一个模型(7个剩余的256个滤波器块),以1200个模拟/移动来估算1200 elo。 MCTS有个优点,它计算能力非常好。
下面动图泥萌可以看到,我(黑色)在repo(白色)模型中对阵模型:

下面的图,你可以看到其中一次对战,我(白色,〜2000 elo)在这个回购(黑色)中与模型对战:

首个好成绩
在用了我创建的新的监督式学习步骤之后,我已经能够训练出一个看着像是国际象棋开局的学习模型了。
下图,大家可以看到这个模型的对战(AI是黑色):

下面,是一场由@ bame55训练的对战(AI玩白色):

5次迭代后,这个模型就能玩成这样了。这5次里,’eval’改变了4次最佳模型。而“opt”的损失是5.1(但结果已经相当好了)。
Modules
监督学习
我已经搞出来了一个监督学习新的流程。
从互联网上找到的那些人类游戏文件“PGN”,我们可以把它们当成游戏数据的生成器。
这个监督学习流程也被用于AlphaGo的第一个和最初版本。
考虑到国际象棋算是比较复杂的游戏,我们必须在开始自我对弈之前,先提前训练好策略模型。也就是说,自我对弈对于象棋来说还是比较难。
使用新的监督学习流程,一开始运行挺简单的。
而且,一旦模型与监督学习游戏数据足够融合,我们只需“监督学习”并启动“自我”,模型将会开始边自我对弈边改进。
python src/chess_zero/run.py sl
如果你想使用这个新的监督学习流程,你得下载一个很大的PGN文件(国际象棋文件)。
并将它们粘贴到data / play_data文件夹中。BTW,FICS是一个很好的数据源。
您也可以使用SCID程序按照玩家ELO,把对弈的结果过滤。
为了避免过度拟合,我建议使用至少3000场对战的数据集,不过不要超过3-4个运行周期。
强化学习
AlphaGo Zero实际上有三个workers:self,opt和eval。
self,自我模型,是通过使用BestModel的自我生成训练数据。
opt,训练模型,是用来训练及生成下一代模型。
eval是评测模型,用于评估下一代模型是否优于BestModel。如果更好,就替换BestModel。
分布式训练
现在可以通过分布式方式来训练模型。唯一需要的是使用新参数:
输入分布式:使用mini config进行测试,(参见src / chess_zero / configs / distributed.py)
分布式训练时,您需要像下面这样在本地运行三方玩家:
python src/chess_zero/run.py self —type distributed (or python src/chess_zero/run.py sl —type distributed) python src/chess_zero/run.py opt —type distributed python src/chess_zero/run.py eval —type distributed
图形用户界面(GUI)
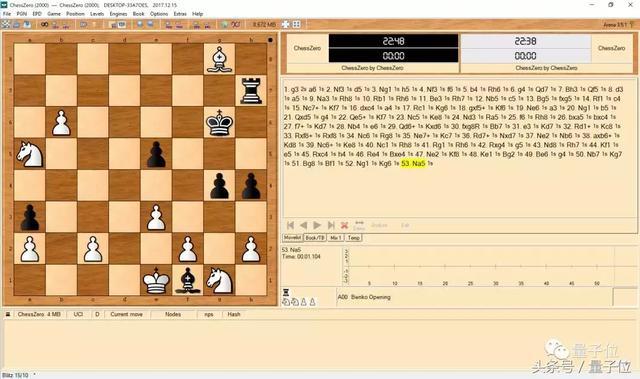
uci启动通用象棋界面,用于GUI。 为ChessZero设置一个GUI,将其指向C0uci.bat(或重命名为.sh)。例如,这是用Arena的自我对弈功能的随机模型的屏幕截图:
数据
data/model/modelbest: BestModel. data/model/next_generation/: next-generation models. data/playdata/play*.json: generated training data. logs/main.log: log file. 如果您想从头开始训练模型,请删除上述目录。
使用说明
安装
安装库
pip install -r requirements.txt
如果您想使用GPU,请按照以下说明使用pip3进行安装。
确保Keras正在使用Tensorflow,并且你有Python 3.6.3+。根据您的环境,您可能需要运行python3 / pip3而不是python / pip。
基本使用
对于训练模型,执行自我对弈模型,训练模型和评估模型。
注意:请确保您正在从此repo的顶级目录运行脚本,即python src / chess_zero / run.py opt,而不是python run.py opt。
自我对弈
python src/chess_zero/run.py self
执行时,自我对弈会开始用BestModel。如果不存在BestModel,就把创建的新的随机模型搞成BestModel。
你可以这么做
创建新的BestModel;
使用mini config进行测试,(参见src / chess_zero / configs / mini.py)。
训练模型
python src/chess_zero/run.py opt
执行时,开始训练。基础模型会从最新保存的下一代模型中加载。如果不存在,就用BestModel。训练好的模型每次也会自动保存。
你可以这么做
输入mini:使用mini config进行测试,(参见src / chess_zero / configs / mini.py)
用全套流程:指定整套流程的(小批量)编号,不过跑完全程会影响训练的学习率。
评价模型
python src/chess_zero/run.py eval
执行后,开始评估。它通过玩大约200场对战来评估BestModel和最新的下一代模型。如果下一代模型获胜,它将成为BestModel。
你可以这么做
输入mini: 使用mini config进行测试,(请参阅src / chess_zero / configs / mini.py)
几点小提示和内存相关知识点
GPU内存
通常来讲,缺少内存会触发警告,而不是错误。
如果发生错误,请尝试更改src / configs / mini.py中的vram_frac,
self.vram_frac = 1.0
较小的batch_size能够减少opt的内存使用量。可以尝试在MiniConfig中更改TrainerConfig#batch_size。
最后,附原文链接,
https://github.com/Zeta36/chess-alpha-zero/blob/master/readme.md
来自:https://baijia.baidu.com/s?id=1593981712049561306&wfr=pc&fr=ch_lst
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/5944/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料