

前言
粗浅的编写正则表达式,是造成性能瓶颈的主要原因。如下:
var reg1 = /(A+A+)+B/; var reg2 = /AA+B/;
上述两个正则表达式,匹配效果是一样的,但是,效率就相差太远了,甚至在与少量字符串匹配时,reg1就会造成你浏览器卡死。
不信?我们可以测试下。
首先,我们声明一个字符串变量str,同时赋予一个包含20个A的字符串给str,采用match方法与上述reg1、reg2进行匹配测试,如下:
var str = 'AAAAAAAAAAAAAAAAAAAA';
str.match(reg1);
str.match(reg2);
在浏览器中运行该段代码,发现一切正常嘛。
然而,随着,我们不断向变量str中添加A后,重复测试,在某一刻(取决于你的浏览器),reg1就会让我们的浏览器挂起,但,回头看看最终的str字符串长度,却还不到50。而,reg2却安然无恙。
心里有一丝疑问,是什么造成了它们如此巨大的差别?以后我们在写正则表达式时,又该如何避免防范这类问题呢?
那么,接下来,我们就有必要深入理解JavaScript正则表达式的内部执行原理了。
如果,在此你还不是很了解正则表达式,那么可以参考如下两篇博客后,再前来,小生在此等候。
正则表达式工作原理
为了高效的使用正则表达式,理解它们的工作原理是很重要的。
具体如下:
Step1.编译
当我们创建一个正则表达式(字面量或者RegExp对象)后,浏览器会检查该正则的模板是否符合标准,然后将其转化成内部代码,用于执行匹配工作。
所以,如果我们将正则表达式赋予一个变量,可以避免重复执行该 ‘编译’ 步骤。
Step2.设置开始位置
当我们使用Step1中编译后的正则表达式时,首先它将确定从目标字符串中什么位置进行匹配。通常,是目标字符串的起始位置,或者由正则表达式的lastIndex属性指定。
但是,当它从Step4(匹配失败)中返回时,该位置则为匹配失败的位置的下一个位置。
Step3.正则匹配
当经历Step2后,正则表达式将从指定位置,从左到右,与目标字符串,逐个匹配。若,正则表达式在匹配过程中,遇到某个字元匹配不了时,它不会立即失败,而是尝试回溯到最近一个决策点,然后在剩余选项中选择一个,以求继续能匹配。
Step4.匹配结果
当经历Step3后,发现能与正则匹配成功的子字符串,那么就匹配成功。如果,经历了Step3后,发现没有能与正则匹配的子字符串,那么,它将回到Step2,继续。只有当目标字符串中的每个字符(以及最后一个字符后面的位置)都经历了Step3后,仍没有找到匹配项,才宣布失败。
下面就举个例子,使我们更透彻地明白以上4步。
如下:
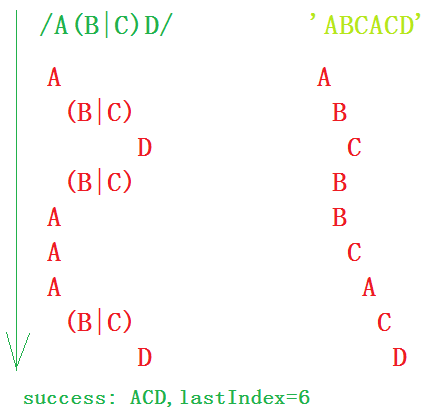
var reg = /A(B|C)D/g; var str = 'ABCACD';
reg.exec(str);
① 首先,浏览器将解析reg正则表达式(Step1)。
② 然后,由于是首次匹配,所以确认开始位置即为字符串起始位置(Step2)。
③ 首先由正则的第一个字元A与字符串起始位置字符A匹配,成功,并在之后的位置记录一个决策点,因为后面有分支嘛;然后由 (B|C)分支中的B选项去匹配字符串的B,发现匹配;然后再由正则下一个字元D去匹配目标字符串第三个字符C,发现不匹配,但是并没有放弃,而是回溯,查看是否有决策点,发现有,回溯到就近一个决策点(字符串首字母A之后的那个位置上),尝试利用第二个分支选项C去匹配字符串第二个字符B,发现不匹配,回溯,查询是否还有其他分支选项,发现没有,然后宣布该次失败(Step3)。
④ 经历Step3后,发现没有与正则匹配的子字符串,但是,与之匹配的目标字符串的匹配位置并不是最后一个位置,所以,回到Step2,从目标字符串的下一个位置(即,字符串首字母A之后的那个位置上)开始匹配。首先由正则表达式的第一个字元A与目标字符串B匹配,不成功,又无回溯点,故而,进入Step4,判断是否是最后一个位置,发现不是,又跳到Step2中继续。
⑤ 就这样一步一步,来到了目标字符串的第四个位置,首先A去与目标字符串的第三个字符A匹配,成功;接下来就是由分支(B|C),去匹配C,首先由分支中的第一个选项B去与C匹配,发现没有成功,回溯到就近一个决策点,尝试利用第二个分支选项C匹配,成功,紧接着D也成功了。
⑥ 匹配成功,并将lastIndex置为6。
回溯
上述 “正则表达式工作原理” 一小节,Step3中的回溯我们是一笔带过的。但是,可不要忽略了,回溯在正则中是非常重要的,如果理解得不明白,我们在编写正则时,很容易造成回溯失控。
下面我们就来一起看看回溯在正则表达式中的运用。
正则表达式中有两种情况,会制造回溯点:
-分支(通过|操作符)
-量词(诸如*,+?,或者{…})
下面我们就分别举例来看看。
分支和回溯
对于分支,详见 ‘正则表达式工作原理’ 小节中Demo。
量词和回溯
在量词中,有贪婪量词(诸如*,+)和非贪婪量词(诸如*?,+?)之分。所以回溯形式对于它们而言也就有差别咯。我们首先写个demo看看贪婪量词是怎么回溯的。
Demo如下:
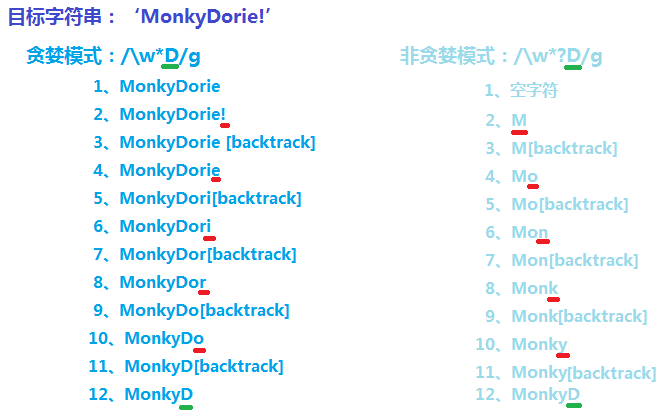
var reg = /\w*D/g; var str = 'MonkyDorie!';
reg.exec(str);
就上述贪婪模式匹配流程如下:
提醒:正则表达式reg中\w表示匹配“字母、数字或下划线”,*这个贪婪量词表示重复匹配零次或者多次,由于是贪婪量词,故而它会尽可能多的匹配。
① 首先,正则中的\w*与目标字符串匹配,会一直匹配到‘!’之前,即’MonkyDorie’,并且,每个匹配位置都会记录一个决策点,便于回溯。
② 然后,由正则中的剩余字元D与字符串中!匹配,匹配失败;但是,它并没有放弃(因为在此之前,记录了决策点),而是回溯到就近一个决策点(字符e的前一个位置),然后正则D与字符e匹配,匹配失败;再回溯到就近一个决策点(字符i的前一个位置),然后正则D与字符i匹配,匹配失败;就这样一直回溯到字符D的前一个位置时,正则D与字符D匹配,匹配成功,并置lastIndex为6。
好了,这就是上述贪婪匹配流程。
随后,我们将上述Demo中的正则表达式,稍微调整下,在*后面加上?,变成非贪婪模式,看看非贪婪量词是怎么回溯的。
Demo如下:
var reg = /\w*?D/g; var str = 'MonkyDorie!';
reg.exec(str);
就上述非贪婪模式匹配流程如下:
提醒:正则表达式reg中\w表示匹配“字母、数字或下划线”,*?是个非贪婪量词,也表示重复匹配零次或者多次,但是由于是非贪婪量词,故而它会尽可能少的匹配。
首先,正则中的\w*?会选择匹配零个字符(尽可能少的匹配),并将第一个位置(字符M的前一个位置)记录一个决策点,继而轮到字元D与字符串字符M匹配,匹配失败;回溯到就近一个决策点(字符M的前一个位置),然后\w*?选择匹配一个字符M,并记录一个回溯点(第二个字符o的前一个位置),继而轮到字元D与字符串字符o匹配,匹配失败;回溯到就近一个决策点(字符o的前一个位置),就这样一步一步,当\w*?选择匹配五个字符Monky时,继而轮到字元D与字符串字符D匹配,匹配成功,并置lastIndex为6.
上述两Demo,对比图如下:
利用前瞻和后向引用避免回溯
正如上述 ‘回溯’ 小节中谈到,重复量词和分支会记录决策点,引起回溯。但是,如果在实际需求中,我们不想让它们记录决策点呢—因为回溯太多就会导致回溯失控,影响性能,正如我们在 ‘前言’ 中看到的那样。
一些正则表达式引擎,支持一种叫做原子组的属性。原子组,写作(?>…),省略号表示任意正则表达式模板。存在原子组中的正则表达式组中的任何决策点都将被丢弃。利用原子组,我们就可以在必要时,消除由重复量词和分支记录的决策点了。
但,在JavaScript中不支持原子组,怎么办呢?
我们可以利用前瞻来模拟原子组,但是,前瞻在整个匹配过程中,是不消耗字符的,它只是检查自己包含的模板是否能在当前位置匹配。然而,我们又可以利用后向引用解决此问题,如下:
(?=(pattern to make atomic))\1
好了,针对 ‘利用前瞻和后向引用避免回溯’ 一节,我们写个Demo,自我测试下:
var str = 'ABCDM'; //目标字符串 var reg1 = /\w*M/; //贪婪模式 var reg2 = /(?=(\w*))\1M/; //贪婪模式,使用前瞻和后向引用 var reg3 = /\w*?M/; //非贪婪模式 var reg4 = /(?=(\w*?))M/; //非贪婪模式,使用前瞻和后向引用
对于以下匹配结果,各位看官答对否:
str.match(reg1); str.match(reg2); str.match(reg3); str.match(reg4);
来自:http://www.cnblogs.com/giggle/p/5990486.html
扫码二维码 获取免费视频学习资料

- 本文固定链接: http://www.phpxs.com/post/5426/
- 转载请注明:转载必须在正文中标注并保留原文链接
- 扫码: 扫上方二维码获取免费视频资料